


Hey guys,
Convex hull optimization is a well known technique used for speeding up dynamic programming algorithms.A thorough explanation of the technique can be found in the end of the post at (1). You can also check the codeforces blog post about various dynamic programming optimizations at (2). I made this blog post to explain how to make convex hull optimization fully persistent. Even though the persistent version consists of a very natural extension of the original data structure I couldn't find anything with a quick search on google, therefore i decided to share it with the codeforces community. So here it goes.
At first let me state the problem. We want to construct a DS which can support the following operations:
- Insert a line in the DS, given by a pair (a,b) which represents the slope of the line and the vertical displacement. We demand that the line we are inserting has greater slope than any of the lines previously on the DS.
- Given a vertical line x = x0, find the line in the DS which intersects the vertical line higher than any of the other lines in the DS. Basically we are searching for the line y = ai * x + bi for which the system of equations
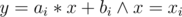 has a solution (x, y) for which y is maximum.
has a solution (x, y) for which y is maximum.
This is the original version of the convex hull problem. In order to get the fully persistent version of the problem we also demand that we can modify an older version of the DS and also query a certain version of the DS. To clarify, when we talk about versions of the DS we consider that version 0 consists of the empty data structure and every insertion defines a new version of the DS.
In order to support the operations above we will use a technique similar to that of a persistent stack. We will build a rooted tree so that every node represents a line and a node to root path represents a version of the stack. The root represents the empty stack. We maintain a pointer that points to the current version of the DS. To insert a line to the current version, we simply insert a child from the current version to a new node that contains the line to be inserted and we update the pointer. For example if we add the following lines: (1, 2), (2, 3), (3, 5) our DS will have the following form: 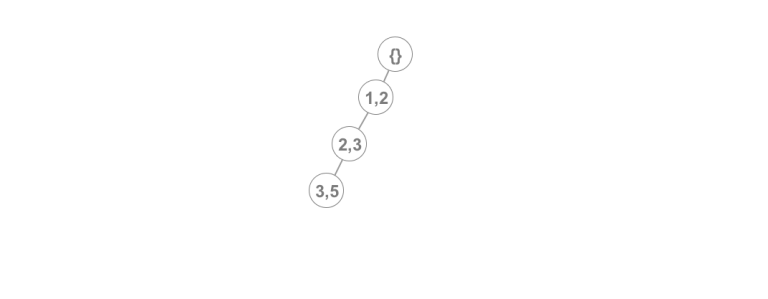
We use this model to support the persistent operations. When we want to add a line to a specific version we simply find the node that represents that version in our tree model and we add a new branch containing our line. To be able to do that we also need a version to node correspondence but this is easy to maintain with a simple array. Therefore if we wanted to add a line (e,g (4,5)) in version 2 of our DS we simply add a new child. Therefore we would have something like this:
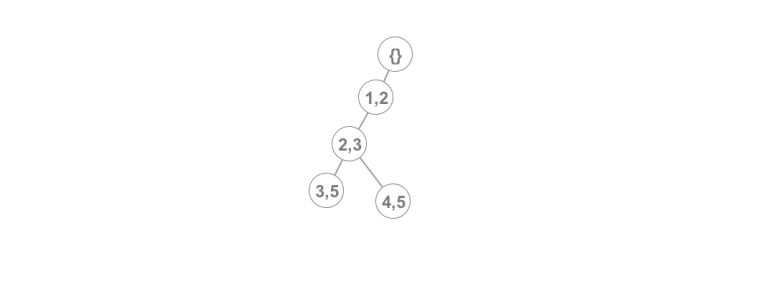
Of course, when we add a specific line to a version, some of the lines may become irrelevant (i.e Never be optimal). therefore, if that's the case, we pop from the top of the stack until our lines are relevant. Of course, popping in our current setting is equivalent to traversing from the node of the current line in that version of the DS to the root and updating the version settings. This may create a problem in the complexity of our structure since we cannot make the same amortization argument we do in our original version (We may be asked to traverse to the root multiple times). We will see how to resolve that shortly.
The question remains though, how could we query a version of our DS represented in the way we described above. We will use jump pointers. Every time we insert a line to a specific version we create links to its 2k - th parent for all k in the same way we do it for LCA. Now, in order to query a version we go to the node that represents the version in the tree and using the jump pointers we perform a binary search. Remember that we only care about the path from the specific node to the root since that's what our stack consists of in that version. Let's use u to represent our node in question (the version we are querying) and let P[u, k] be the 2k-th parent of node u. We find the largest k for which 2k ≤ depthu and we operate similarly to the original version of the problem. We check the node v = P[u, k] and its parent p(v), if the line that is stored in p(v) intersects the vertical line higher than the line stored in v we go to v and continue our search from there. Otherwise we decrease k and continue.
By using jump pointers we can also resolve the problems we had updating the data structure. We will simply perform a binary search to find the first line in the node to root path that should not be erased from the DS and add a child to that specific node. The binary search condition is the same as with the original version of the DS.
Therefore we have achieved to support our operations in O(NlogN) space O(logN) worst case time for update and query.
(2) Dynamic Programming Optimizations
I am sure that a similar idea is probably discussed somewhere, I just felt like sharing it since i think that it can be used for many cool problems. If you know any problems that can be solved using this technique please add them in the comments. Feel free to make any corrections or point out any mistakes, there might be quite a few of them.






