


Дорогие посетители Codeforces!
Наступают летние каникулы — лучшее время для подготовки к олимпиадам. Именно поэтому мы запускаем для вас курс Спортивное программирование на платформе Stepik! Преподаватели курса: Наталья Бондаренко (natalia) – золотой призер ACM ICPC 2009 года и серебряный призер 2010 года, Андрей Гайдель (Shlakoblock) и Елена Рогачева (elena) – тренеры команд Самарского университета и организаторы олимпиад по спортивному программированию.
Старт курса — 1 июля, но записываться можно уже сейчас. Особо нетерпеливые могут пройти этот курс на платформе Coursera, на которой он уже запущен.
В процессе работы с двумя платформами, мы видим большое преимущество Stepik в том, что на нем каждое задание представляет собой отдельный шаг. После успешной сдачи или нескольких неудачных попыток по заданию, слушатель получает возможность обсуждать решение с другими слушателями и преподавателями, публиковать свое правильное или неправильное решение независимо от ситуации с другими заданиями. Наш предыдущий курс Математика для олимпиад по программированию породил огромное количество таких обсуждений. Мы надеемся, что новый курс окажется не менее интересным и полезным для участников. Он включает в себя много практики решения задач.
С уважением, команда курса.








 .
.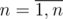 . Выбирая максимум по левым частям и минимум по правым, получим неравество вида
. Выбирая максимум по левым частям и минимум по правым, получим неравество вида 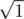 ,
, 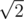 ,
, 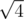 ,
, 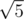 и т.д., т.е. корни целых чисел, представимых в виде
и т.д., т.е. корни целых чисел, представимых в виде 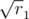 ,
, 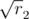 , ... В некоторых случаях можно взять в качестве длин сторон первые
, ... В некоторых случаях можно взять в качестве длин сторон первые 