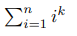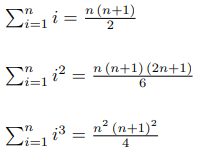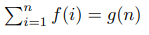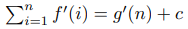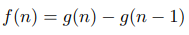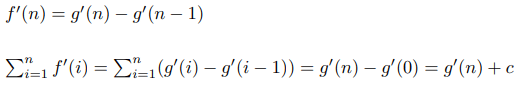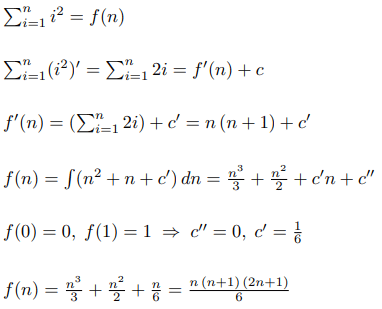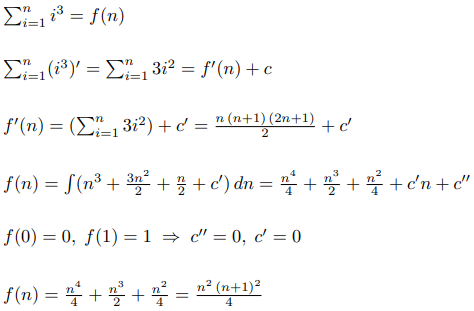The USACO.Guide is excited to announce the 2026 USACO.Guide Informatics Tournament!
The contest takes place on Pi Day (March 14th) from 10:30 AM to 1:30 PM PDT. The contest is $$$3$$$ hours long, and contestants will compete individually to solve $$$8$$$ problems. There are two divisions, Standard and Advanced. Everyone can compete, although only pre-college students are eligible for prizes. There are $$$900$$$ dollars in prizes:
Advanced:
$$$300$$$ dollars
$$$200$$$ dollars
$$$100$$$ dollars
through 8. $$$15$$$ dollars
Beginner:
$$$75$$$ dollars
$$$50$$$ dollars
$$$25$$$ dollars
through 8. $$$15$$$ dollars
We are also raffling three $$$15$$$ dollar gift cards to random participants who make at least one submission during the contest.
The contest will be held at https://contest.joincpi.org/. More detailed instructions and rules are present there. Most notably, you may not use AI tools in any way during the contest.
Register today!
Join our discord server!