


I'd like to invite everybody to participate in HourRank 12 on HackerRank. It'll start tomorrow at 19:30 PM MSK.
It's my first HourRank but I've prepared problems for HackerRank several times. I also used to prepare problems for Codeforces long time ago.
There will be three problems and one hour to solve them. Contest will be rated and top-10 contestants on the leaderboard will receive amazing HackerRank T-shirts!
I'd like to thank wanbo for testing the problems, it's always a pleasure to work with him. I hope you will enjoy the problems and some of you will solve everything.
Scoring will be: 20-40-80. Editorials will be published right after the contest.
Good luck!






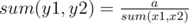 . There is corner case
. There is corner case 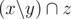 . So, we have to find shortest sequence of sets
. So, we have to find shortest sequence of sets 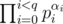 where
where 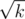 is also beautiful.
is also beautiful.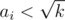 . Consider some element of factorisation of
. Consider some element of factorisation of 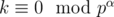 and it is not true that
and it is not true that 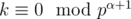 . Let
. Let 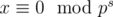 .
. 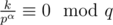 numbers
numbers 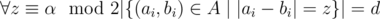 where
where 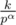 . So in
. So in 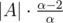 pairs both numbers are divisible by
pairs both numbers are divisible by 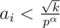 is equivalent approval.
is equivalent approval.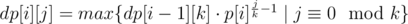

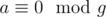 where
where 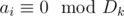 for every
for every 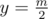 in cartesian coordinate system.
in cartesian coordinate system.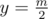 and enumareate all segments
and enumareate all segments 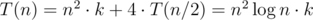 for square-shaped tables.
for square-shaped tables.
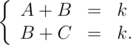
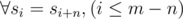
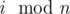 . For all
. For all 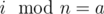 .
.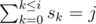 .
. 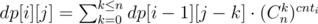
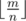 and
and 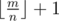 . Let's calc
. Let's calc 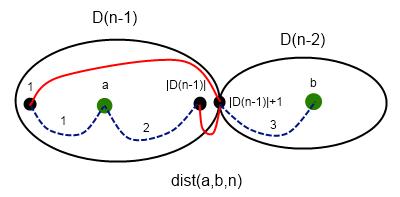
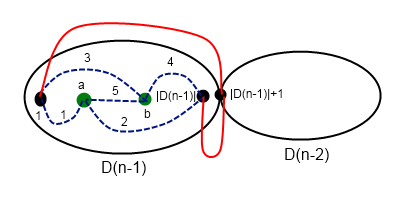
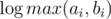 for one query. (it's log because
for one query. (it's log because 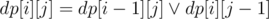 for the right part of board.
for the right part of board. 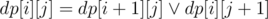 (
(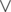 — logical or, here it's bitwise or for masks) for the left part. dp calcs mask of achieveable points in the central column.
— logical or, here it's bitwise or for masks) for the left part. dp calcs mask of achieveable points in the central column.
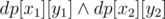 (
(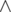 is bitwise and) is not empty.
is bitwise and) is not empty.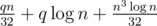 .
. 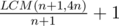 crosses.
crosses.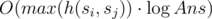 .
.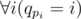 , we shall get the answer for the initial problem and initial permutation
, we shall get the answer for the initial problem and initial permutation 
 ,
, 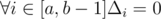 ,
, 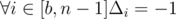 . (elements of permutation are numbered from 0). If
. (elements of permutation are numbered from 0). If 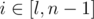
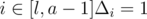 , for
, for 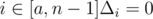 .
. 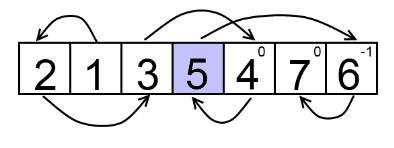
 .
.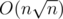 .
.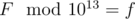 . Then
. Then 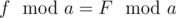 and
and 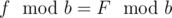 .
.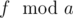 in Fibonacci sequence modulo
in Fibonacci sequence modulo 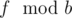 in Fibonacci sequence modulo
in Fibonacci sequence modulo 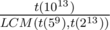 numbers. That was the author's solution.
numbers. That was the author's solution.