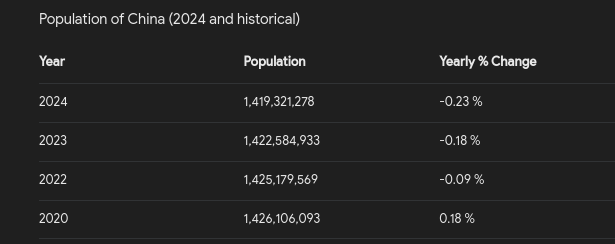
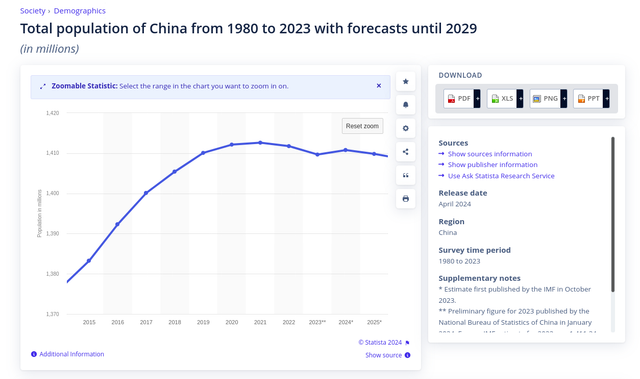
title
looking for either one person or a small group (at a similar skill level, 2200-2300)
would just like to discuss after contests/share random problems/take VCs together for the next few months
also, im not an OIer but don’t mind grinding OI problems
edit: ok found some people, thanks everyone!