6235741
/** Micro Mezzo Macro Flation -- Overheated Economy ., Last Update: Feb. 12th 2013 **/ //{
/** Header .. **/ //{
#define LOCAL
#include <functional>
#include <algorithm>
#include <iostream>
#include <fstream>
#include <sstream>
#include <iomanip>
#include <numeric>
#include <cstring>
#include <cassert>
#include <cstdio>
#include <string>
#include <vector>
#include <bitset>
#include <queue>
#include <stack>
#include <cmath>
#include <ctime>
#include <list>
#include <set>
#include <map>
using namespace std;
#define REP(i, n) for (int i=0;i<int(n);++i)
#define FOR(i, a, b) for (int i=int(a);i<int(b);++i)
#define DWN(i, b, a) for (int i=int(b-1);i>=int(a);--i)
#define REP_1(i, n) for (int i=1;i<=int(n);++i)
#define FOR_1(i, a, b) for (int i=int(a);i<=int(b);++i)
#define DWN_1(i, b, a) for (int i=int(b);i>=int(a);--i)
#define REP_C(i, n) for (int n____=int(n),i=0;i<n____;++i)
#define FOR_C(i, a, b) for (int b____=int(b),i=a;i<b____;++i)
#define DWN_C(i, b, a) for (int a____=int(a),i=b-1;i>=a____;--i)
#define REP_N(i, n) for (i=0;i<int(n);++i)
#define FOR_N(i, a, b) for (i=int(a);i<int(b);++i)
#define DWN_N(i, b, a) for (i=int(b-1);i>=int(a);--i)
#define REP_1_C(i, n) for (int n____=int(n),i=1;i<=n____;++i)
#define FOR_1_C(i, a, b) for (int b____=int(b),i=a;i<=b____;++i)
#define DWN_1_C(i, b, a) for (int a____=int(a),i=b;i>=a____;--i)
#define REP_1_N(i, n) for (i=1;i<=int(n);++i)
#define FOR_1_N(i, a, b) for (i=int(a);i<=int(b);++i)
#define DWN_1_N(i, b, a) for (i=int(b);i>=int(a);--i)
#define REP_C_N(i, n) for (int n____=(i=0,int(n));i<n____;++i)
#define FOR_C_N(i, a, b) for (int b____=(i=0,int(b);i<b____;++i)
#define DWN_C_N(i, b, a) for (int a____=(i=b-1,int(a));i>=a____;--i)
#define REP_1_C_N(i, n) for (int n____=(i=1,int(n));i<=n____;++i)
#define FOR_1_C_N(i, a, b) for (int b____=(i=1,int(b);i<=b____;++i)
#define DWN_1_C_N(i, b, a) for (int a____=(i=b,int(a));i>=a____;--i)
#define ECH(it, A) for (__typeof(A.begin()) it=A.begin(); it != A.end(); ++it)
#define REP_S(i, str) for (char*i=str;*i;++i)
#define REP_L(i, hd, nxt) for (int i=hd;i;i=nxt[i])
#define REP_G(i, u) REP_L(i,hd[u],suc)
#define DO(n) for ( int ____n ## __line__ = n; ____n ## __line__ -- ; )
#define REP_2(i, j, n, m) REP(i, n) REP(j, m)
#define REP_2_1(i, j, n, m) REP_1(i, n) REP_1(j, m)
#define REP_3(i, j, k, n, m, l) REP(i, n) REP(j, m) REP(k, l)
#define REP_3_1(i, j, k, n, m, l) REP_1(i, n) REP_1(j, m) REP_1(k, l)
#define REP_4(i, j, k, ii, n, m, l, nn) REP(i, n) REP(j, m) REP(k, l) REP(ii, nn)
#define REP_4_1(i, j, k, ii, n, m, l, nn) REP_1(i, n) REP_1(j, m) REP_1(k, l) REP_1(ii, nn)
#define ALL(A) A.begin(), A.end()
#define LLA(A) A.rbegin(), A.rend()
#define CPY(A, B) memcpy(A, B, sizeof(A))
#define INS(A, P, B) A.insert(A.begin() + P, B)
#define ERS(A, P) A.erase(A.begin() + P)
#define BSC(A, x) (lower_bound(ALL(A), x) - A.begin())
#define CTN(T, x) (T.find(x) != T.end())
#define SZ(A) int(A.size())
#define PB push_back
#define MP(A, B) make_pair(A, B)
#define PTT pair<T, T>
#define fi first
#define se second
#define Rush for(int ____T=RD(); ____T--;)
#define Display(A, n, m) { \
REP(i, n){ \
REP(j, m) cout << A[i][j] << " "; \
cout << endl; \
} \
}
#define Display_1(A, n, m) { \
REP_1(i, n){ \
REP_1(j, m) cout << A[i][j] << " "; \
cout << endl; \
} \
}
#pragma comment(linker, "/STACK:36777216")
//#pragma GCC optimize ("O2")
#define Ruby system("ruby main.rb")
#define Haskell system("runghc main.hs")
#define Python system("python main.py")
#define Pascal system("fpc main.pas")
typedef long long LL;
//typedef long double DB;
typedef double DB;
typedef unsigned UINT;
typedef unsigned long long ULL;
typedef vector<int> VI;
typedef vector<char> VC;
typedef vector<string> VS;
typedef vector<LL> VL;
typedef vector<DB> VF;
typedef set<int> SI;
typedef set<string> SS;
typedef map<int, int> MII;
typedef map<string, int> MSI;
typedef pair<int, int> PII;
typedef pair<LL, LL> PLL;
typedef vector<PII> VII;
typedef vector<VI> VVI;
typedef vector<VII> VVII;
template<class T> inline T& RD(T &);
template<class T> inline void OT(const T &);
inline LL RD(){LL x; return RD(x);}
inline DB& RF(DB &);
inline DB RF(){DB x; return RF(x);}
inline char* RS(char *s);
inline char& RC(char &c);
inline char RC();
inline char& RC(char &c){scanf(" %c", &c); return c;}
inline char RC(){char c; return RC(c);}
//inline char& RC(char &c){c = getchar(); return c;}
//inline char RC(){return getchar();}
template<class T> inline T& RDD(T &x){
char c; for (c = getchar(); c < '-'; c = getchar());
if (c == '-'){x = '0' - getchar(); for (c = getchar(); '0' <= c && c <= '9'; c = getchar()) x = x * 10 + '0' - c;}
else {x = c - '0'; for (c = getchar(); '0' <= c && c <= '9'; c = getchar()) x = x * 10 + c - '0';}
return x;
}
inline LL RDD(){LL x; return RDD(x);}
template<class T0, class T1> inline T0& RD(T0 &x0, T1 &x1){RD(x0), RD(x1); return x0;}
template<class T0, class T1, class T2> inline T0& RD(T0 &x0, T1 &x1, T2 &x2){RD(x0), RD(x1), RD(x2); return x0;}
template<class T0, class T1, class T2, class T3> inline T0& RD(T0 &x0, T1 &x1, T2 &x2, T3 &x3){RD(x0), RD(x1), RD(x2), RD(x3); return x0;}
template<class T0, class T1, class T2, class T3, class T4> inline T0& RD(T0 &x0, T1 &x1, T2 &x2, T3 &x3, T4 &x4){RD(x0), RD(x1), RD(x2), RD(x3), RD(x4); return x0;}
template<class T0, class T1, class T2, class T3, class T4, class T5> inline T0& RD(T0 &x0, T1 &x1, T2 &x2, T3 &x3, T4 &x4, T5 &x5){RD(x0), RD(x1), RD(x2), RD(x3), RD(x4), RD(x5); return x0;}
template<class T0, class T1, class T2, class T3, class T4, class T5, class T6> inline T0& RD(T0 &x0, T1 &x1, T2 &x2, T3 &x3, T4 &x4, T5 &x5, T6 &x6){RD(x0), RD(x1), RD(x2), RD(x3), RD(x4), RD(x5), RD(x6); return x0;}
template<class T0, class T1> inline void OT(const T0 &x0, const T1 &x1){OT(x0), OT(x1);}
template<class T0, class T1, class T2> inline void OT(const T0 &x0, const T1 &x1, const T2 &x2){OT(x0), OT(x1), OT(x2);}
template<class T0, class T1, class T2, class T3> inline void OT(const T0 &x0, const T1 &x1, const T2 &x2, const T3 &x3){OT(x0), OT(x1), OT(x2), OT(x3);}
template<class T0, class T1, class T2, class T3, class T4> inline void OT(const T0 &x0, const T1 &x1, const T2 &x2, const T3 &x3, const T4 &x4){OT(x0), OT(x1), OT(x2), OT(x3), OT(x4);}
template<class T0, class T1, class T2, class T3, class T4, class T5> inline void OT(const T0 &x0, const T1 &x1, const T2 &x2, const T3 &x3, const T4 &x4, const T5 &x5){OT(x0), OT(x1), OT(x2), OT(x3), OT(x4), OT(x5);}
template<class T0, class T1, class T2, class T3, class T4, class T5, class T6> inline void OT(const T0 &x0, const T1 &x1, const T2 &x2, const T3 &x3, const T4 &x4, const T5 &x5, const T6 &x6){OT(x0), OT(x1), OT(x2), OT(x3), OT(x4), OT(x5), OT(x6);}
inline char& RC(char &a, char &b){RC(a), RC(b); return a;}
inline char& RC(char &a, char &b, char &c){RC(a), RC(b), RC(c); return a;}
inline char& RC(char &a, char &b, char &c, char &d){RC(a), RC(b), RC(c), RC(d); return a;}
inline char& RC(char &a, char &b, char &c, char &d, char &e){RC(a), RC(b), RC(c), RC(d), RC(e); return a;}
inline char& RC(char &a, char &b, char &c, char &d, char &e, char &f){RC(a), RC(b), RC(c), RC(d), RC(e), RC(f); return a;}
inline char& RC(char &a, char &b, char &c, char &d, char &e, char &f, char &g){RC(a), RC(b), RC(c), RC(d), RC(e), RC(f), RC(g); return a;}
inline DB& RF(DB &a, DB &b){RF(a), RF(b); return a;}
inline DB& RF(DB &a, DB &b, DB &c){RF(a), RF(b), RF(c); return a;}
inline DB& RF(DB &a, DB &b, DB &c, DB &d){RF(a), RF(b), RF(c), RF(d); return a;}
inline DB& RF(DB &a, DB &b, DB &c, DB &d, DB &e){RF(a), RF(b), RF(c), RF(d), RF(e); return a;}
inline DB& RF(DB &a, DB &b, DB &c, DB &d, DB &e, DB &f){RF(a), RF(b), RF(c), RF(d), RF(e), RF(f); return a;}
inline DB& RF(DB &a, DB &b, DB &c, DB &d, DB &e, DB &f, DB &g){RF(a), RF(b), RF(c), RF(d), RF(e), RF(f), RF(g); return a;}
inline void RS(char *s1, char *s2){RS(s1), RS(s2);}
inline void RS(char *s1, char *s2, char *s3){RS(s1), RS(s2), RS(s3);}
template<class T0,class T1>inline void RDD(const T0&a, const T1&b){RDD(a),RDD(b);}
template<class T0,class T1,class T2>inline void RDD(const T0&a, const T1&b, const T2&c){RDD(a),RDD(b),RDD(c);}
template<class T> inline void RST(T &A){memset(A, 0, sizeof(A));}
template<class T> inline void FLC(T &A, int x){memset(A, x, sizeof(A));}
template<class T> inline void CLR(T &A){A.clear();}
template<class T0, class T1> inline void RST(T0 &A0, T1 &A1){RST(A0), RST(A1);}
template<class T0, class T1, class T2> inline void RST(T0 &A0, T1 &A1, T2 &A2){RST(A0), RST(A1), RST(A2);}
template<class T0, class T1, class T2, class T3> inline void RST(T0 &A0, T1 &A1, T2 &A2, T3 &A3){RST(A0), RST(A1), RST(A2), RST(A3);}
template<class T0, class T1, class T2, class T3, class T4> inline void RST(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4){RST(A0), RST(A1), RST(A2), RST(A3), RST(A4);}
template<class T0, class T1, class T2, class T3, class T4, class T5> inline void RST(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, T5 &A5){RST(A0), RST(A1), RST(A2), RST(A3), RST(A4), RST(A5);}
template<class T0, class T1, class T2, class T3, class T4, class T5, class T6> inline void RST(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, T5 &A5, T6 &A6){RST(A0), RST(A1), RST(A2), RST(A3), RST(A4), RST(A5), RST(A6);}
template<class T0, class T1> inline void FLC(T0 &A0, T1 &A1, int x){FLC(A0, x), FLC(A1, x);}
template<class T0, class T1, class T2> inline void FLC(T0 &A0, T1 &A1, T2 &A2, int x){FLC(A0, x), FLC(A1, x), FLC(A2, x);}
template<class T0, class T1, class T2, class T3> inline void FLC(T0 &A0, T1 &A1, T2 &A2, T3 &A3, int x){FLC(A0, x), FLC(A1, x), FLC(A2, x), FLC(A3, x);}
template<class T0, class T1, class T2, class T3, class T4> inline void FLC(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, int x){FLC(A0, x), FLC(A1, x), FLC(A2, x), FLC(A3, x), FLC(A4, x);}
template<class T0, class T1, class T2, class T3, class T4, class T5> inline void FLC(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, T5 &A5, int x){FLC(A0, x), FLC(A1, x), FLC(A2, x), FLC(A3, x), FLC(A4, x), FLC(A5, x);}
template<class T0, class T1, class T2, class T3, class T4, class T5, class T6> inline void FLC(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, T5 &A5, T6 &A6, int x){FLC(A0, x), FLC(A1, x), FLC(A2, x), FLC(A3, x), FLC(A4, x), FLC(A5, x), FLC(A6, x);}
template<class T> inline void CLR(priority_queue<T, vector<T>, less<T> > &Q){while (!Q.empty()) Q.pop();}
template<class T> inline void CLR(priority_queue<T, vector<T>, greater<T> > &Q){while (!Q.empty()) Q.pop();}
template<class T0, class T1> inline void CLR(T0 &A0, T1 &A1){CLR(A0), CLR(A1);}
template<class T0, class T1, class T2> inline void CLR(T0 &A0, T1 &A1, T2 &A2){CLR(A0), CLR(A1), CLR(A2);}
template<class T0, class T1, class T2, class T3> inline void CLR(T0 &A0, T1 &A1, T2 &A2, T3 &A3){CLR(A0), CLR(A1), CLR(A2), CLR(A3);}
template<class T0, class T1, class T2, class T3, class T4> inline void CLR(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4){CLR(A0), CLR(A1), CLR(A2), CLR(A3), CLR(A4);}
template<class T0, class T1, class T2, class T3, class T4, class T5> inline void CLR(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, T5 &A5){CLR(A0), CLR(A1), CLR(A2), CLR(A3), CLR(A4), CLR(A5);}
template<class T0, class T1, class T2, class T3, class T4, class T5, class T6> inline void CLR(T0 &A0, T1 &A1, T2 &A2, T3 &A3, T4 &A4, T5 &A5, T6 &A6){CLR(A0), CLR(A1), CLR(A2), CLR(A3), CLR(A4), CLR(A5), CLR(A6);}
template<class T> inline void CLR(T &A, int n){REP(i, n) CLR(A[i]);}
template<class T> inline T& SRT(T &A){sort(ALL(A)); return A;}
template<class T, class C> inline T& SRT(T &A, C B){sort(ALL(A), B); return A;}
template<class T> inline T& UNQ(T &A){A.resize(unique(ALL(SRT(A)))-A.begin());return A;}
//}
/** Constant List .. **/ //{
const int dx4[] = {-1, 0, 1, 0};
const int dy4[] = {0, 1, 0, -1};
const int dx8[] = {-1, 0, 1, 0 , -1 , -1 , 1 , 1};
const int dy8[] = {0, 1, 0, -1 , -1 , 1 , -1 , 1};
const int dxhorse[] = {-2 , -2 , -1 , -1 , 1 , 1 , 2 , 2};
const int dyhorse[] = {1 , -1 , 2 , -2 , 2 ,-2 , 1 ,-1};
const int MOD = 1000000007;
//int MOD = 99990001;
const int INF = 0x3f3f3f3f;
const LL INFF = 1LL << 60;
const DB EPS = 1e-9;
const DB OO = 1e15;
const DB PI = acos(-1.0); //M_PI;
//}
/** Add On .. **/ //{
// <<= '0. Nichi Joo ., //{
template<class T> inline void checkMin(T &a,const T b){if (b<a) a=b;}
template<class T> inline void checkMax(T &a,const T b){if (a<b) a=b;}
template<class T> inline void checkMin(T &a, T &b, const T x){checkMin(a, x), checkMin(b, x);}
template<class T> inline void checkMax(T &a, T &b, const T x){checkMax(a, x), checkMax(b, x);}
template <class T, class C> inline void checkMin(T& a, const T b, C c){if (c(b,a)) a = b;}
template <class T, class C> inline void checkMax(T& a, const T b, C c){if (c(a,b)) a = b;}
template<class T> inline T min(T a, T b, T c){return min(min(a, b), c);}
template<class T> inline T max(T a, T b, T c){return max(max(a, b), c);}
template<class T> inline T min(T a, T b, T c, T d){return min(min(a, b), min(c, d));}
template<class T> inline T max(T a, T b, T c, T d){return max(max(a, b), max(c, d));}
template<class T> inline T sqr(T a){return a*a;}
template<class T> inline T cub(T a){return a*a*a;}
inline int ceil(int x, int y){return (x - 1) / y + 1;}
inline int sgn(DB x){return x < -EPS ? -1 : x > EPS;}
inline int sgn(DB x, DB y){return sgn(x - y);}
//}
// <<= '1. Bitwise Operation ., //{
namespace BO{
inline bool _1(int x, int i){return bool(x&1<<i);}
inline bool _1(LL x, int i){return bool(x&1LL<<i);}
inline LL _1(int i){return 1LL<<i;}
inline LL _U(int i){return _1(i) - 1;};
inline int reverse_bits(int x){
x = ((x >> 1) & 0x55555555) | ((x << 1) & 0xaaaaaaaa);
x = ((x >> 2) & 0x33333333) | ((x << 2) & 0xcccccccc);
x = ((x >> 4) & 0x0f0f0f0f) | ((x << 4) & 0xf0f0f0f0);
x = ((x >> 8) & 0x00ff00ff) | ((x << 8) & 0xff00ff00);
x = ((x >>16) & 0x0000ffff) | ((x <<16) & 0xffff0000);
return x;
}
inline LL reverse_bits(LL x){
x = ((x >> 1) & 0x5555555555555555LL) | ((x << 1) & 0xaaaaaaaaaaaaaaaaLL);
x = ((x >> 2) & 0x3333333333333333LL) | ((x << 2) & 0xccccccccccccccccLL);
x = ((x >> 4) & 0x0f0f0f0f0f0f0f0fLL) | ((x << 4) & 0xf0f0f0f0f0f0f0f0LL);
x = ((x >> 8) & 0x00ff00ff00ff00ffLL) | ((x << 8) & 0xff00ff00ff00ff00LL);
x = ((x >>16) & 0x0000ffff0000ffffLL) | ((x <<16) & 0xffff0000ffff0000LL);
x = ((x >>32) & 0x00000000ffffffffLL) | ((x <<32) & 0xffffffff00000000LL);
return x;
}
template<class T> inline bool odd(T x){return x&1;}
template<class T> inline bool even(T x){return !odd(x);}
template<class T> inline T low_bit(T x) {return x & -x;}
template<class T> inline T high_bit(T x) {T p = low_bit(x);while (p != x) x -= p, p = low_bit(x);return p;}
template<class T> inline T cover_bit(T x){T p = 1; while (p < x) p <<= 1;return p;}
} using namespace BO;//}
// <<= '2. Number Theory .,//{
namespace NT{
inline LL __lcm(LL a, LL b){return a*b/__gcd(a,b);}
inline void INC(int &a, int b){a += b; if (a >= MOD) a -= MOD;}
inline int sum(int a, int b){a += b; if (a >= MOD) a -= MOD; return a;}
inline void DEC(int &a, int b){a -= b; if (a < 0) a += MOD;}
inline int dff(int a, int b){a -= b; if (a < 0) a += MOD; return a;}
inline void MUL(int &a, int b){a = (LL)a * b % MOD;}
inline int pdt(int a, int b){return (LL)a * b % MOD;}
inline int sum(int a, int b, int c){return sum(sum(a, b), c);}
inline int sum(int a, int b, int c, int d){return sum(sum(a, b), sum(c, d));}
inline int pdt(int a, int b, int c){return pdt(pdt(a, b), c);}
inline int pdt(int a, int b, int c, int d){return pdt(pdt(pdt(a, b), c), d);}
inline int pow(int a, int b){
int c(1); while (b){
if (b&1) MUL(c, a);
MUL(a, a), b >>= 1;
}
return c;
}
inline int pow(int a, LL b){
int c(1); while (b){
if (b&1) MUL(c, a);
MUL(a, a), b >>= 1;
}
return c;
}
template<class T> inline T pow(T a, LL b){
T c(1); while (b){
if (b&1) c *= a;
a *= a, b >>= 1;
}
return c;
}
inline int _I(int b){
int a = MOD, x1 = 0, x2 = 1, q;
while (true){
q = a / b, a %= b;
if (!a) return (x2 + MOD) % MOD;
DEC(x1, pdt(q, x2));
q = b / a, b %= a;
if (!b) return (x1 + MOD) % MOD;
DEC(x2, pdt(q, x1));
}
}
inline void DIV(int &a, int b){MUL(a, _I(b));}
inline int qtt(int a, int b){return pdt(a, _I(b));}
inline int phi(int n){
int res = n; for (int i=2;sqr(i)<=n;++i) if (!(n%i)){
DEC(res, qtt(res, i));
do{n /= i;} while(!(n%i));
}
if (n != 1)
DEC(res, qtt(res, n));
return res;
}
};// using namespace NT;//}
//}
/** Miscellaneous .. **/ //{
/** Algorithm .. */ //{
// <<= '-. Math .,//{
namespace Math{
typedef long long typec;
///Lib functions
typec GCD(typec a, typec b)
{
return b ? GCD(b, a % b) : a;
}
typec extendGCD(typec a, typec b, typec& x, typec& y)
{
if(!b) return x = 1, y = 0, a;
typec res = extendGCD(b, a % b, x, y), tmp = x;
x = y, y = tmp - (a / b) * y;
return res;
}
///for x^k
typec power(typec x, typec k)
{
typec res = 1;
while(k)
{
if(k&1) res *= x;
x *= x, k >>= 1;
}
return res;
}
///for x^k mod m
typec powerMod(typec x, typec k, typec m)
{
typec res = 1;
while(x %= m, k)
{
if(k&1) res *= x, res %= m;
x *= x, k >>=1;
}
return res;
}
/***************************************
Inverse in mod p^t system
***************************************/
typec inverse(typec a, typec p, typec t = 1)
{
typec pt = power(p, t);
typec x, y;
y = extendGCD(a, pt, x, y);
return x < 0 ? x += pt : x;
}
/***************************************
Linear congruence theorem
x = a (mod p)
x = b (mod q)
for gcd(p, q) = 1, 0 <= x < pq
***************************************/
typec linearCongruence(typec a, typec b, typec p, typec q)
{
typec x, y;
y = extendGCD(p, q, x, y);
while(b < a) b += q / y;
x *= b - a, x = p * x + a, x %= p * q;
if(x < 0) x += p * q;
return x;
}
/***************************************
prime table
O(n)
***************************************/
const int PRIMERANGE = 1000000;
int prime[PRIMERANGE + 1];
int mobius[PRIMERANGE + 1];
int getPrime()
{
memset (prime, 0, sizeof (int) * (PRIMERANGE + 1));
memset(mobius , 0 , sizeof(mobius));
mobius[1] = 1;
for (int i = 2; i <= PRIMERANGE; i++)
{
if (!prime[i]) prime[++prime[0]] = i , mobius[i] = -1;
for (int j = 1; j <= prime[0] && prime[j] <= PRIMERANGE / i; j++)
{
prime[prime[j]*i] = 1;
if (i % prime[j] == 0) break;
else mobius[i * prime[j]] = -mobius[i];
}
}
return prime[0];
}
/***************************************
get factor of n
O(sqrt(n))
factor[][0] is prime factor
factor[][1] is factor generated by this prime
factor[][2] is factor counter
need: Prime Table
***************************************/
///you should init the prime table before
int factor[100][3], facCnt;
int getFactors(int x)
{
facCnt = 0;
int tmp = x;
for(int i = 1; prime[i] <= tmp / prime[i]; i++)
{
factor[facCnt][1] = 1, factor[facCnt][2] = 0;
if(tmp % prime[i] == 0)
factor[facCnt][0] = prime[i];
while(tmp % prime[i] == 0)
factor[facCnt][2]++, factor[facCnt][1] *= prime[i], tmp /= prime[i];
if(factor[facCnt][1] > 1) facCnt++;
}
if(tmp != 1)
factor[facCnt][0] = tmp, factor[facCnt][1] = tmp, factor[facCnt++][2] = 1;
return facCnt;
}
typec combinationModP(typec n, typec k, typec p)
{
if(k > n) return 0;
if(n - k < k) k = n - k;
typec a = 1, b = 1, x, y;
int pcnt = 0;
for(int i = 1; i <= k; i++)
{
x = n - i + 1, y = i;
while(x % p == 0) x /= p, pcnt++;
while(y % p == 0) y /= p, pcnt--;
x %= p, y %= p, a *= x, b *= y;
b %= p, a %= p;
}
if(pcnt) return 0;
extendGCD(b, p, x, y);
if(x < 0) x += p;
a *= x, a %= p;
return a;
}
};//using namespace Math;
//}
// <<= '-. Geo ,.//{
namespace Geo{
#define typec double
const typec eps=1e-9;
int dblcmp(double d)
{
return d < -eps ? -1 : d > eps;
}
inline double sqr(double x){return x*x;}
struct point
{
double x,y;
point(){}
point(double _x,double _y):
x(_x),y(_y){};
void input()
{
scanf("%lf%lf",&x,&y);
}
void output()
{
printf("%.2f %.2f\n",x,y);
}
bool operator==(point a)const
{
return dblcmp(a.x-x)==0&&dblcmp(a.y-y)==0;
}
bool operator<(point a)const
{
return dblcmp(a.x-x)==0?dblcmp(y-a.y)<0:x<a.x;
}
double len()
{
return hypot(x,y);
}
double len2()
{
return x*x+y*y;
}
double distance(point p)
{
return hypot(x-p.x,y-p.y);
}
double distance2(point p)
{
return sqr(x-p.x)+sqr(y-p.y);
}
point add(point p)
{
return point(x+p.x,y+p.y);
}
point operator + (const point & p) const{
return point(x+p.x,y+p.y);
}
point sub(point p)
{
return point(x-p.x,y-p.y);
}
point operator - (const point & p) const{
return point(x-p.x,y-p.y);
}
point mul(double b)
{
return point(x*b,y*b);
}
point div(double b)
{
return point(x/b,y/b);
}
double dot(point p)
{
return x*p.x+y*p.y;
}
double operator * (const point & p) const{
return x*p.x+y*p.y;
}
double det(point p)
{
return x*p.y-y*p.x;
}
double operator ^ (const point & p) const{
return x*p.y-y*p.x;
}
double rad(point a,point b)
{
point p=*this;
return fabs(atan2(fabs(a.sub(p).det(b.sub(p))),a.sub(p).dot(b.sub(p))));
}
point trunc(double r)
{
double l=len();
if (!dblcmp(l))return *this;
r/=l;
return point(x*r,y*r);
}
point rotleft()
{
return point(-y,x);
}
point rotright()
{
return point(y,-x);
}
point rotate(point p,double angle)//�Ƶ�p��ʱ����תangle�Ƕ�
{
point v=this->sub(p);
double c=cos(angle),s=sin(angle);
return point(p.x+v.x*c-v.y*s,p.y+v.x*s+v.y*c);
}
#undef typec
};
};//using namespace Geo;
//}
//}
/** I/O Accelerator Interface .. **/ //{
template<class T> inline T& RD(T &x){
//cin >> x;
//scanf("%d", &x);
char c; for (c = getchar(); c < '0'; c = getchar()); x = c - '0'; for (c = getchar(); '0' <= c && c <= '9'; c = getchar()) x = x * 10 + c - '0';
//char c; c = getchar(); x = c - '0'; for (c = getchar(); c >= '0'; c = getchar()) x = x * 10 + c - '0';
return x;
}
inline DB& RF(DB &x){
//cin >> x;
scanf("%lf", &x);
/*char t; while ((t=getchar())==' '||t=='\n'); x = t - '0';
while ((t=getchar())!=' '&&t!='\n'&&t!='.')x*=10,x+=t-'0';
if (t=='.'){DB l=1; while ((t=getchar())!=' '&&t!='\n')l*=0.1,x += (t-'0')*l;}*/
return x;
}
inline char* RS(char *s){
//gets(s);
scanf("%s", s);
return s;
}
int Case; template<class T> inline void OT(const T &x){
//printf("Case %d: %d\n", ++Case, x);
//printf("%.2lf\n", x);
//printf("%d\n", x);
cout << x << endl;
}








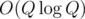 or
or 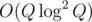 solution.
solution. parts of
parts of 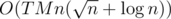 . My solution with this algorithm ACs the problem.
. My solution with this algorithm ACs the problem.
