


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | Radewoosh | 3415 |
| 8 | Um_nik | 3376 |
| 9 | maroonrk | 3361 |
| 10 | XVIII | 3345 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 133 |
|
+184
I hope you all enjoyed solving this year's Qualification Round! After many years of competing on HC, now (as Alphabet employee) I proposed this year's problem, and built two datasets: B -- which is based on real streets of Lisbon, and D -- which is a challenging-to-navigate network from the Barabási-Albert distribution. Unleashing random walks on such a graph forces many paths to go through a small amount of hub nodes, causing more challenging scheduling scenarios. It's been great to read about all the heuristics you've come up with! |

|
0
Auto comment: topic has been updated by PetarV (previous revision, new revision, compare). |
|
+6
Speaking for Cambridge: we have been able to get travel and accommodation support from our Department (and often, Colleges). However, it is evident that they're not really accustomed/involved with this stuff, i.e. there's not an 'established' way of funding, but a few responsible people have to sort funding out directly and separately for every year. Especially this year, when we had an unusual number of teams advancing to the regionals. And just to add to the above conversation: all of our contending teams at NWERC this year have been (nearly-)homogeneous w.r.t. nationality. It makes sense — people who have had the chance to work together before coming to university will have already developed somewhat of a nice synergy in the problem-solving process. |
|
+14
|
|
+19
The Serbian Olympiad in Informatics has recently finished---so here is Serbia's IOI team, subject to appeals:
|
|
0
Of course you can, if it would provide a benefit to any user with respect to the (partial) solution you have built up before. If it doesn't, there's really no need to (the algorithm will assign a value of zero). |
|
0
Sounds about right. To be fully precise, "assuming that there are no other caches" is incorrect, since you do take into account all the assignments you made to other caches when you compute the utilities of the videos (e.g. if some cache already has video X, and serves it to everyone better than the cache you're currently filling, then X will have zero value with respect to its knapsack). The order in which this is done is clearly important — it should be simple to construct a case with only two caches, where choosing which cache to fill first will impact the result significantly. You can think of optimising each cache as a local ("greedy") solution, which might not yield the best results in the global case. Lastly, I don't think the word should is the best word to use. This is indeed the strategy we used, and we managed to (barely) get into the finals (ranked 53rd). As some other people have said, it seems that it's possible to outperform us with simpler randomised greedy strategies (that do not involve solving several dynamic programming problems as a subtask). |
|
0
Assuming you've fully decided which videos go in all the other caches. (Of course, in reality, while executing this algorithm you usually haven't---and that's why the solution obtained at the end is only approximate.) |
|
0
Sure, it's on my GitHub: https://github.com/PetarV-/HashCode2017 |
|
+10
Solving for a single cache, assuming all others are fixed, is simple: compute the gain in overall latency should you add video X (for all videos X), and then solve a 0/1-knapsack problem. Our solution: Shuffle the caches, and solve the knapsacks one-by-one. Overall (with some tiny optimisations/randomisations here and there): 2.578M |
|
0
Thanks! Good to know that such a proof can be made to work during the contest. N.B. I still think that there were quite a few teams who played it completely by hunch (basically us included, but only after exhausting any other possible option). |
|
+17
Here are my $0.02, being the person that coded up the AC solution of H for our (eduardische, VladGavrila and mine) team at the onsite. I think that coming up with the idea that randomisation could work at some point of the algorithm is not hard to come by here (the very small degree of the person:team bipartite graph really hints at it, and such weirdly small constraints often hint at the fact rand() could be plugged in somewhere). But if the probabilistic proof of the fact this works is not easy to come by, then I would expect at least some part of the construction to require somethig sensible. But from what I gathered, even trying fully randomised assignments would've worked here? In this case it really amounts to a hunch. This does not mean that the problem is "broken" in any way. It just points at the question of what the problem is trying to reward. And here it seems that the reward comes from tenacity (i.e. the "move fast and maybe things won't break approach") rather than anything else. In fact I think another team's member told me that they got the determination to try the rand approach when they saw how another team reacted to getting AC, which in my opinion totally bypasses any educational value of a problem like this. This was the only thing which made me dislike this problem ultimately. And I normally really like encountering stochastic problems like this (good example is NWERC 2014 Problem F: http://2014.nwerc.eu/nwerc2014problems.pdf). Otherwise I thought that the BC9 problemset was awesome and organisation was great (no hiccups at all on contest day despite several issues during training session). Great work, and I hope to go again next year. |
|
0
Our issue ended up being network size — doubled the amount of convolutional kernels and it magically worked. For the record, the architecture used was: Conv -> ReLU -> Conv -> ReLU -> MaxPool -> FC (+ dropout) -> ReLU -> FC -> Softmax Of course, the "golden middle way" would've been the way to go, had we taken up this problem earlier on during the contest. |
|
+2
We didn't receive any appeals. For all intents and purposes, you may consider this team to be final. :) |
|
+41
The Serbian Olympiad in Informatics has just finished---so here is Serbia's IOI team, subject to appeals:
|
|
0
I'm glad that this has sparked a constructive debate on approaches. Honestly, I wasn't trying to say that all approaches other than mine are "wrong". I just find the presumption that whenever I write "int" I could as well have written "long long" to be wrong — exactly for the reasons I_love_Hoang_Yen given — and that's why I would never write that as part of a fixed template. I even used to take the "more hacky" approach myself early on. Now I'm less of a competitive programmer, more like a computer scientist who likes to keep his algorithmic skills somewhat polished. :) |
|
+8
Because this is (in my opinion) not good style. Also, what if you want to define a potentially very large int vector? (Such that 4x as much would exceed the memory limit) |
|
0
Probably — the sum of all loudness levels could exceed the range of 32-bit integers. |
|
0
Did you use 64-bit integers (long longs) to store intermediate values? |
|
+13
In my opinion, the problems themselves were very good, but some of the statements required more scrutiny. Also, yay — after two failed GCJs, one failed FBHCup and who-knows-how-many failed CF rounds — I didn't trip on 64-bit integers. |
|
0
The complexity of my solution is actually something along the lines of O(N^2 log N) in the worst case (something like 5 6 7 8 1 2 3 4) anyway. I try to follow the approach which is easiest for me to comprehend on a high level. If it requires complicated structures, so be it (especially if they're already part of the STL). :) |
|
0
You can maintain an ordered set (balanced binary search tree) of all elements that need to go to the left (call this set L), and all that need to go to the right of the permutation (call this set R). In each iteration you perform one swap, that involves swapping the leftmost element in L with its closest element in R to the left (it clearly has to exist). If you store both the elements and their positions, you can efficiently maintain this structure as you go along in logarithmic complexity. You may refer to my code: http://mirror.codeforces.com/contest/584/submission/13456405 |
|
+14
It seems like there is an "anti-cheating" pass, or something similar, after systest? I noticed my rank increase from 83 to 81 already :D |
|
+1
Editorial is already out: |
|
+1
Thank you for this round — it felt great solving the problems. Especially problem D, with having to go on a hunch of doing LIS from two sides for some number of copies of the array, even though I wasn't able to prove on-the-fly that this will work. Hopefully I'll be back to div1 now. :) |
|
+26
The Serbian selection contest has just ended. The team this year will be:
|
|
+5
I failed to solve this problem, but I'm pretty sure your condition x ≥ k does not hold. Consider a cycle 1 -> 2 -> 3 -> 1; for this example, k = 3. Setting k = 4: f4(1) = 2, f4(2) = 3, f4(3) = 1. f8(1) = 3, f8(2) = 1, f8(3) = 2. What needs to be solved turns out to be a system of congruences, I think. |
|
+1
Note that, after T minutes, you can easily calculate how many people have been assigned a barber (including people that have finished). It is simply summing over the amount of people that each barber has, i.e.
where ⌈·⌉ represents the ceiling function. Clearly, this sum grows as T grows, hence you can do a binary search for the highest time Tmax when less than N people are assigned a barber (i.e. such that cnt(Tmax) < N). At that exact time, you know that a barber will be available to service the N-th person. All you need to do is go through all available barbers (the k-th barber is available at this point if Tmax ≡ 0 (mod Mk)). Whenever encountering an available barber, we increment a variable X, which is initially set to X = cnt(Tmax). Once X = N, we have assigned a barber to the N-th person, and we only need to return that barber's id. Here's my code: http://hastebin.com/vigefudase.vala |
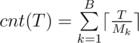
|
On
MikeMirzayanov →
2014-2015 ACM-ICPC, NEERC, Southern Subregional Contest (Online Mirror, ACM-ICPC Rules, Teams Preferred), 12 years ago
+5
First of all, in order to ease your processing you might want to convert the tree such that each node has only one key/value pair. Then each "component" will be represented by a chain of k/v pair nodes, connected from the first one to its parent (unless it's the main component), and from the last one to all of its children in the component graph. Now your problem is simply reduced to finding the first occurrence of some key on the path from any node to the root. This can be done in O(log N) time per query using a technique known as Heavy-Light Decomposition (HLD) — a fairly simple transform that allows you to get from any node in a tree to the root in logarithmic time, by potentially skipping over entire chains. |
|
+8
Piramida: First, note that the zig-zag change in direction of the letters is irrelevant. Now, the thing you need to know for a requested row of the structure is which index in the string it starts with. It should be clear that the starting index (with indexing from zero) of the n-th row is Hope that was clear. |
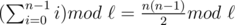 , where
, where 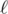 is the length of the string. Now that you know the start position and the length of the sequence (which is equal to the row's index) — hence you can first add up all the appearances of the desired letter in the whole string a few times, and then possibly have some more letters left over to check. These can be added up using partial sums (summed for each letter individually). A trick to consider here, which cost me 30pts, is that all partial sums won't fit in the memory requirement, hence you need to first calculate all queries containing the letter A, then all the queries containing B, and so on, reusing the same 1D array as you go.
is the length of the string. Now that you know the start position and the length of the sequence (which is equal to the row's index) — hence you can first add up all the appearances of the desired letter in the whole string a few times, and then possibly have some more letters left over to check. These can be added up using partial sums (summed for each letter individually). A trick to consider here, which cost me 30pts, is that all partial sums won't fit in the memory requirement, hence you need to first calculate all queries containing the letter A, then all the queries containing B, and so on, reusing the same 1D array as you go.|
0
Yeah. I handle the array members that are less than or equal to K separately from the others (as you can see from my code). |
|
+3
What I did was quite simple. Initially I hardcoded the first 64 primes and pre-calculated the bitmasks representing which primes were used in each of the possible numbers' prime factorisations. (overkill, I know) Afterwards I dealt with the simple case of all A[i] <= K (in this case, we make all members of the new array to be K, except for if there are any zeroes, one of them can become a zero). If this does not hold, I initially bounded the solution with using only K * P[i] as my new array, where P is an array of only primes. Now I performed a simple brute-force recursion. It takes parameters of the current sum, index, bitmask and number used). It starts a for loop from max(previousNumber + 1, A[i]/K). If the current number in the loop doesn't violate the bit mask already there, it is placed in the i-th position and we move on. I disable recursing into impossible solutions by enforcing that the elements of the new array must be in increasing order; hence, if I have just added the number X to my array and I have Y numbers left to place, then the sum is bounded below by prevSum + Y*X + Y*(Y+1)/2 (the case where the following numbers are: X+1, X+2, ..., X+Y). If this lower bound is greater than the already found minimum, we can safely stop recursing. This turned out to execute quite quickly on my machine (the time spent on a file with 1000 random test cases with N = 20 was negligible). Here's my code. |
|
On
MikeMirzayanov →
Internet-version of the Southern (Saratov) Subregional Contest (NEERC) 2013, 13 years ago
+3
l=x[i]-sqrt(ra*ra-1); r=x[i]+sqrt(ra*ra+1); shouldn't it be |
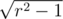 in both cases? :)
in both cases? :)|
On
MikeMirzayanov →
Internet-version of the Southern (Saratov) Subregional Contest (NEERC) 2013, 13 years ago
+3
double low = pos[i] — 1.0*r; double hi = pos[i] + 1.0*r; I think these are incorrect. You should use Pythagoras' theorem here. r2 = 12 + D2 (where D is the distance you need to add/subtract from pos[i]). |
|
On
MikeMirzayanov →
Internet-version of the Southern (Saratov) Subregional Contest (NEERC) 2013, 13 years ago
+9
Problem B: Move the camera lazily to the nearest good position in every step. You can find the nearest good position in each step by doing f.ex. binary search on the array C. Problem F: You can write the solution of the expected value as such:
where and t[i] represents the time when i-th testcase will be processed. |
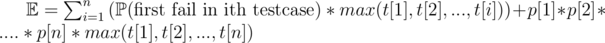
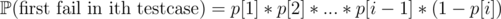 .
.|
On
gen →
About the University of Cambridge NWERC selection contest and Codeforces groups, 13 years ago
+34
Well-written blog post. This was an exciting and challenging onsite contest! Quite a few successful submissions happened in the last 10 minutes. It definitely reignited my interest in such contests. :) Gratz to the advancing teams! |
|
0
You interpreted the task properly (if by subarray you mean a substring). You can calculate the solution in a single pass through the array, such that when you are at the j-th position, you also store the minimum i such that [i..j] is the maximum substring that ends in j. What you do is add the j-th value to the current sum, and while the sum is larger than t, subtract the i-th value and shift i one space forward. After each step is done, check whether the current interval size is larger than the maximum recorded so far and you're done. Here's my code for that: 3240473 |
|
0
I think that BIT is not convenient to use there. Segment tree seems like a much better option :) |
|
0
read(b) — read(a-1), except if a = 1, then just read(b). If I understood correctly that you want to get the sum of the substring [a,a+1,...,b]. Or if you mean just the sum of all amounts together (with respect to this problem C), you'd have to iterate through every field separately. It's not possible to do it in O(1) read commands if you store data this way. You'd have to extract the sequence, and then make a new BIT / prefix sum array out of it, if you want to do it with only two read() commands (if we assume the queries have already been loaded and processed). |
|
0
You have essentially did the same thing mostly everybody else did — storing cumulative sums. The only difference between your solution and mine is that my access/update times are O(log N) and yours are O(1). And it has no overall effect on the complexity because you need O(N log N) to sort the sequence anyway (unless you use a non-comparison sorting method i.e. counting sort). |
|
0
1&x is 1 if and only if x is odd, otherwise it is zero. |
|
0
Because we are storing the value on some index as its cumulative sum: when we update left index with 1 and right+1 with -1, we increase the cumulative sum from the left to the right index by 1 and not change any other. |
|
0
Oh yes, I forgot that, silly me :) |
|
+1
Just noticed it's possible to do C in O(n), without a BIT, just using a regular array to calculate cumulative sums. But I think there's nothing wrong with my solution, at least with respect to the given constraints. :) |
|
+7
Here's an unofficial editorial: http://www.codeforces.com/blog/entry/6778 Great round! |
|
+3
Just wrote a code that solves it without explicitly involving graphs: 2031563 The idea is the same as in the graph solution, you just assign each point to a group as you process the input (creating a new group when a point you just added has no other reachable point), and if necessary merge groups if a point is found that merges some groups together. The result is the amount of groups minus 1. |
|
0
it is correct (ofc with also removing one more player if the number of players left is odd), but look at the test which you failed: n = 4 3 -> 2 4 -> 2 4 -> 3 There is one cycle here, and also this leaves us with an odd number of people left so we got to remove one more, rendering the final solution of 2. Your program outputs 0. My only conclusion could be that you implemented something wrongly. (since you passed the pretests I guess you already minded the case when the remaining number of players is odd) |
|
+7
This contest started horribly for me (it took me a very long time to correctly deduce the formula for A, noob :P), but ended as my best placement ever (35th). I'm really happy, and I really enjoyed this entire competition, all the tasks were very interesting! Especially the Web one (even though the idea behind it is not that difficult, the formulation was very nice :D). Gratz everyone! |
|
+5
Very nice analysis! However, I think that introducing matrix exponentiation is unnecessary for this task, since we have a rather simple system of recurrence relations here, we can relatively easily reduce it to integer exponentiation: Let's take two sequences, A and B, where A will be the sequence of amounts of upwards triangles, and B the sequence of downwards ones. We know the following: A[0] = 1 B[0] = 0 A[i] = A[i-1] * 3 + B[i-1] (i > 0) (F1) B[i] = A[i-1] + B[i-1] * 3 (i > 0) (F2) Solving the following recurrence system easily yields a 2nd order homogeneous difference equation: 3 * A[i] — B[i] = 8 * A[i-1] (3*F1 — F2) 3 * A[i] = 8 * A[i-1] + Bi 3 * A[i-1] = 8 * A[i-2] + B[i-1] (F3 for i-1) A[i] — 3 * A[i-1] = 3 * A[i-1] + B[i-1] — 8*A[i-2] — B[i-1] (F1 — F3) A[i+2] = 6 * A[i+1] — 8 * A[i] Solving this yields A[i] = 2^(i-1) * (2^i + 1). Now all we got to do is calculate 2^(n-1) and 2^n to solve the task. Do mind the special case when n = 0 though, i forgot that one at the contest and got hacked :P There are other, less formal ways of deducing this A[i] formula. For example, one may notice that the number of upwards triangles will always be 1 + 2 + ... + 2^N (if we observe them by "rows"). This gives us (using the formula for the sum of first K numbers): 2^N*(2^N + 1) / 2 = 2^(N-1) * (2^N + 1) |
|
+7
Excellent competition, I enjoyed solving the tasks and they were all very clear. One of the better ones in a long while for me. By the way, is there something wrong with my browser, or did all the rating changes in Div2 for this contest get removed? If so, when can we expect it fixed? |
|
0
Serbia: Boris Grubić (borisgrubic), Ivan Stošić (ivan100sic), Demjan Grubić (Demjan) and Andrej Ivašković (no handle). |
|
0
We take the square's fields as a linear sequence of 4*n fields. To simplify our calculations, we'll mark the fields starting from 0 (the bottom left corner).. all the way to 4*n — 1. In every move we will traverse n+1 fields, thus landing on the field marked as k * (n+1) mod 4*n, where k is the amount of moves we made. Now it is obvious that the solution to the problem is the smallest positive k for which k * (n+1) gives a remainder 0 when dividing with 4*n, plus 1 (because we have to count the initial cross too). Hope this helped. |
|
+1
Really enjoyable and challenging contest. I could've done much better, but I still had lots of fun doing it and it's all that matters. Congratulations to the organizer! |
|
+19
Very enjoyable competition, I do not regret missing out on COCI for this :D I particularly enjoyed solving task E (E1 and E2 at that, I had no idea how to cope with the "noise" — but still, it was a very interesting task) :) |
|
+1
Very enjoyable contest for me :) Just one question: Was my idea for Space Voyage correct? What I did was perform a binary search for the lower and upper bounds of X (of course, only if it was confirmed that there weren't infinite solutions). My rightmost bound for the BS was c * MAX(b[i]), and I got WA on test ~ 23 or so. |
