


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 163 |
| 2 | adamant | 149 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 135 |
| 7 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 132 |
|
0
Sorry for the misunderstandings. Actually, I tried to say that in a Div. 1 only round around 500-600 people attend. If there are X problems in that round, probably around 25-30 people should be able to solve X/X-1 problems. |

|
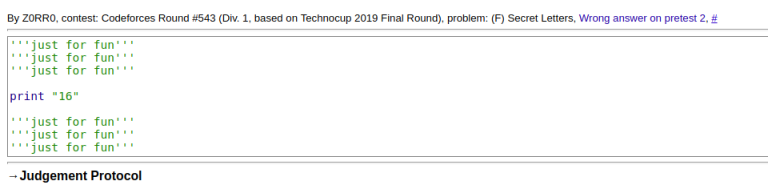
+50
Submitted all the problems like this
|
|
+6
Ofcourse the later one. I have updated the comment. |
|
+136
As usual I am asking for it every year :p We want countrywise standings in each round. |
|
+27
In every year, 5-7 national level ACM ICPC style contests held in Bangladesh. In each contest there are always 100-150 teams. So, for a person who is doing competitive programming for 4/5 years and having good results in these contests can be popular among themselves. This has nothing to do with their Codeforces rating. Apart from that, the number of contestants from Bangladesh in Codeforces is very high. The newly starters have a tendency to add contestants from the top of the table. |
|
+34
It should have been said, most followed handle's rankings or something like this. But I go with this anyway. Of course populated countries have many popular contestants among them. And I have fixed this. Thank you. |
|
+11
Generate 2 sets of random strings of size ceil(N/2) and floor(N/2). Lets denote them as set A and set B. Let the size of each set is X. You can generate random strings by changing just a single random character of previous string as this will change the hash value randomly. Now generate their hashes. Now on, we only will deal with the hash values, forget the strings. For each hash value of set B, we can say we need a desired hash from set A such that we can make the final hash value. Say hash value of an element of set B is H2. So we need another hash value from set A, H1 such that this equation satisfies ( H1 + (H2 << ceil(N/2)) ) % M = final_hash. Here shift operator denotes the polynomial shifting, hope it is understandable. Now, for the first H2 of set B, we will not be able to find the desired H1 with a probability (1-X/M). Now, as our desired hash value is not found in set A for the first element, for the second element we can assume it's desired hash value will not collide with the first one's. So, now the sample space is reduced by one. So, this will also not match with a probability (1-X/(M-1)). For the third element the probability is (1-X/(M-2)) and so on. This is the birthday paradox. With a good enough size of set A and set B the probability of not finding desired pair becomes 0. Like when X = 1e4, chance of not finding is more than 95%, when X = 1e5, chance of not finding is less than 1%. But when you take X = 1e6, chance of not finding is way way close to 0. I might miss some calculation here, but this is the idea. |
|
0
In problem D, I assumed if we destroy a node from this graph and can not find a cycle then the desired edge should be connected with that node(from and to). I took one node that meets that condition. So, now It is just needed to destroy at most (n+n) edges. So, total complexity is O(n(n+m)). But the assumption is wrong, any node that meets that condition does not necessarily have the desired edge connected with it. So, I took all nodes that meet that condition and checked randomly from each node till I get a desired edge. This one passed in less than half second. Total complexity is O(k*n*(n+m)) where k is number of such possible node. But I think in practical this k should be very small. I can not come up with any graph to disprove this and I am not also sure if the k should always be very small. |
|
+8
Exactly. One can get AC after a few minutes with 1/2 additional penalty. But after system test, BOOM, you dropped down by a huge margin for some silly coding error or corner case misses which could have been easily found. |
|
0
I did the exact same thing but my query block size was sqrt(Q), Passed in 1.45s Solution |
|
0
Is there any chance codeforces going full feedback in near future ? |
|
0
Your performance rating R means you performed like a contestant having rating R. If you became x'th in a contest and someone having rating R had the expected position x'th in that contest, then your performance rating is R for that particular contest. |
|
+23
Can you give us 2 new features as a New Year Gift? :p Countrywise Standings and Performance Rating in each contest like Atcoder does. |
|
+3
I guess the 5th problem has a bit weaker data set. I iterated over all siblings of each node instead using prefix and suffix sum. And it passed in just 0.4s. code |
|
+18
|
|
+2
FA Cup Semi-final: Arsenal vs Man City match perhaps :p |
|
0
thanks all :) |
|
+19
Their combined team rating is 3516(if we consider their max rating and according to cf's team rating calculation algorithm). And you know who's rating is greater than this :p |
|
+6
The number of people you are friend of |
|
+21
and Intel Code Challenge Elimination Round (Div.1 + Div.2, combined) C. Destroying Array was exact same problem with CS Academy round 9 Array Removal problem. |
|
+5
My problem F was one submission away to get Accepted ! In final minutes I tried to submit it but Internet connection failed !! After system test I submitted my code and I just wanted my solution to get a wrong answer and guess what, it is an Accepted :( |
|
+61
cricketers doing their job. you should do your job as a contestant too ;) |
|
+11
thank you for this wonderful data structure. I am recovering from aibohphobia with the help of eertree :D |
|
0
just solved this problem with the given resources. thanks to all |
|
On
Farnan.PUST →
স্ট্রিং এর সাবস্ট্রিং বের করার ক্ষেত্রে জটিলতা (Complexity between Naive approach & KMP algorithm for searching substring from a string), 10 years ago
0
Are you serious Brother ! |
|
0
Can anyone please explain the idea of Div1/C or Div2/E ? |
|
+25
It would be very nice if you can add countrywise standings in every round. I know there are some API/browser extensions for this feature but if we get this here that would be great. |
|
+1
I used it to know if LCM(w,b) is greater than t or not.I used unsigned long long. It's more than 18.4e18 . Inputs are 5e18 . In first step you add some value X to the result and in the next step add 2X to the answer and then 4X and so on. Say your latest addition was X to the result that did not cross 5e18 but was very close to it . your next addition will be 2X . So, In worst case result will become something like 15e18. So,stop the calculation as you know the result will definitely be larger than what you needed. |
|
+1
I used Russian Peasant for Multiplication but later realized it was not necessary. |
|
+3
I was so confused about my solution of C and D . System Test was so late that I wrote many random huge dataset for them and took high rated coder's code as AC solution . My code worked for them and got some relief . :D |
|
+10
"We use di = (R - ri) / 2 as rating change for the i-th participant." initially it was di = (R-ri) / 3 and now this is di = (R-ri) / 2. was that a typo or the formula has been modified ? |
|
On
MikeMirzayanov →
2015-2016 ACM-ICPC, NEERC, Southern Subregional Contest (Online Mirror, ACM-ICPC Rules, Teams Preferred), 11 years ago
+13
got AC after 36 attempts :3 |
|
On
MikeMirzayanov →
2015-2016 ACM-ICPC, NEERC, Southern Subregional Contest (Online Mirror, ACM-ICPC Rules, Teams Preferred), 11 years ago
0
is it possible to solve G with square-root decomposition ? |
|
0
It would be nice if contestants can see their expected place in the standings or somewhere else for a particular round. |
|
0
This is why I suggested for keeping that button for few initial minutes too as it is hard for someone to make sure in that very short time if he can solve his desired problem. |
|
0
Yes,everyone has a chance to participate and also div1 contestants participate in div2 contests as unrated. I am only saying that one should confirm at the beginning of the contest that he is ready to participate as rated. Anybody can see and solve the problems and also their rank can be seen in standings but unofficially. |
|
+10
I have read it just now :) . Sometimes we can not attend the contest although we registered before. I think "Confirm Participation" is probably the best thing we can ask for. |
|
-12
People just like to downvote comparatively low rated programmers comments whatever they write.Racist everywhere. |
|
+4
Normally score of Div1E is equal to 5 times of Div1A. And for Low Candidate Masters and High Experts it's needed a great effort to solve Div2D than Div2C. So,Div2D should get a lot more scores than Div2C as it actually gets in Div1,in fact double. 250 — 500 — 750 — 1500 — 2250 — 3000 — 3750 would be good if we consider this i think. |
|
0
5000+ registration and all of them are official . This is great :D |
