


Spectral::Cup 2026 Round 2 (Codeforces Round 1100, Div. 1 + Div. 2)
33:38:23
Register now »
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | Radewoosh | 3415 |
| 8 | Um_nik | 3376 |
| 9 | maroonrk | 3361 |
| 10 | XVIII | 3345 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 133 |
|
+278
Great editorial for problem G |


|
+5
What happens if you take medium? |
|
+38
Same thing happened to me :( |
|
+40
I think it's roughly equals to (number of CF users hit by meteorite fall) / (number of meteorite falls) |
|
+133
I like antontrygubO_o problems, but once Thanos said "Perfectly balanced as all thing should be", I feel that CF is missing this balance in the problems, I would prefer a bit of diversity in the problem set. |
|
+20
Yeah, that's definitely what I was looking for |
|
0
Auto comment: topic has been updated by fmota (previous revision, new revision, compare). |
|
+25
I mean a filter for standings |
|
+3
Yet another screencast. The channel have focus in brazilian community so many videos will be in portuguese, but from time to time I maybe do something in english, or with no audio like this screencast |
|
+40
I suggest to create something as a collaborative repository to hold translations (or maybe just a short description of the problem) based in automatic translations, I think this could helpful to you and easier to be achieved. |
|
+1
Can anyone hack https://mirror.codeforces.com/contest/1285/submission/68545833 ? |
|
+38
What is TC9 in E ? |
|
On
Errichto →
Codeforces Round #584 (Dasha Code Championship Elimination Round) (div. 1 + div. 2), 7 years ago
+8
I did it, but WA62 UPD: It works, I have made a silly bug |
|
-7
You are a genius. I am already waiting for it. |
|
+19
In G, isn't possible to construct a case where taking the modulo during the calculations will lead to a wrong answer ? Like, endpoint A needs MOD to run and endpoint B needs 100 to run, if you take the mod the max will be B, but the real max is A. |
|
+16
D — Test case 6 is this test really right ? M = 11511 but there is only 1875 lines |
|
+8
I didn't pass the problem yet (seems like there is a index out of bound in my code), but I passed the case 5, seems like the statement is incorrect, link in this line you are comparing $$$a \lt = b$$$, but the statement says it should be $$$a \lt = b'$$$ right ? |
|
+13
What is the case 5 of D ? |
|
+12
I will give a few hints. |
|
+33
Good luck Emiso ❤️ |
|
+8
I realized that in the D is necessary to consider the cases where there is a 0 in the range, but didn't corrected my code correctly, wasted a big chance :( |
|
+50
20 minutes of penalty is too much. |
|
+13
I used the same strategy and only passed my C++ problem in the last 24 seconds |
|
+14
I used javascript, C#, PHP, Ruby, Python 2, D, Java, C and C++ . It was fun like last year. |
|
0
K: You can do with the same complexity but with trie and kmp, you build a trie for every word in the set that has length smaller than |
 for every node in the trie you keep the the current answer and the last index last of the occurrence then updates this values running in the substrings of size smaller than
for every node in the trie you keep the the current answer and the last index last of the occurrence then updates this values running in the substrings of size smaller than |
+9
Use another sqrt decomposition to know the mex value, you do updates in constant time and query in |
 , since you make only
, since you make only 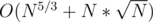
|
0
Can you explain the reasons or at least a idea about this formula ? |
|
+15
How to solve G and D? |
|
+35
Instituto Militar de Engenharia: |
|
+14
Universidade Federal de Campina Grande: |
|
0
The last year magic was canceled in the scoreboard UPD: It's fixed |
|
0
You end up in fourth in the contest and then the contest was declared unrated, so sad |
|
+10
Wow, nice tutorial. |
|
0
The vector just keeps a pointer, so no . |
|
+8
For E, let's solve a simpler problem, suppose you just have to change the root and query the sum in a subtree, if we preprocess the sum of subtrees with the tree rooted at X, there's only three cases to handle when answering queries to a vertex V, To process the updates you have to find the lca(u,v) considering the tree rooted in current_root, the vertex is one of the nodes in {lca(u,v), lca(u, current_root), lca(v, current_root)} and then you process the update similar to the queries, to update a subtree and to query the sum in a subtree, you just need a bit and euler tour. |
|
+8
For D, you can use a implicit persistent segment tree to keep the values of the words and another to keep the amount of words with value equals to X. |
|
0
Why "Idleness limit exceeded on pretest 1" in http://mirror.codeforces.com/contest/916/submission/34316902 ? UPD: This happens because I am trying to read an integer in queries and removes |
|
+8
My code for D didn't passed the examples during the contest and now it's is AC, amazing. |
|
0
Will the problems be moved to practice ? |
|
0
|
|
+9
Really bad issue with test cases, hoping for rejudging. First time that I won a contest. : ) |
|
+119
" Brazil broke into the top! ... ". In this moment, I realized that I visited too much codeforces . |
|
+5
Is F an analysis of various cases ? |
|
+32
Good luck to you, I also wanna thanks to chessmaster , this was one of my motivations in the year, happily I achieved the objective before my regionals |
|
0
Can you link one of this submissions ? |
|
+11
https://www.hackerearth.com/practice/data-structures/advanced-data-structures/segment-trees/practice-problems/algorithm/replace-27c5286c/ . This is a harder version of problem G. Also the editorial explains the complexity. My implementation http://mirror.codeforces.com/contest/911/submission/33747581 . |
|
0
That was what I tried too, I tried to use block-cut tree to check if it is possible to reach but, unhappily I received MLE (Maybe the implementation was wrong) |
|
+10
How to solve Plat. 2 ? |
|
0
What's the pretest 3 on C ? |
|
0
I get the ideia now, interesting solution |
|
+1
https://imgur.com/a/rR4vK That was the answer that I received |
|
+1
This will create a discussion about the advantages that you get based on CF color |
|
+24
What you have done to being not affected ? |
|
+65
Probably the queue worked |
|
0
9 ? |
|
+56
He is not a burden to me, ordan thinks the same, I don't know about the previous team. Why he would be embarrassed ? He has his religion and we can't do nothing about it. This team wasn't decided a day before the competition, we discussed the whole situation, the whole team accepted it. I am happy that I had the necessary to qualify to world finals and take ME_AJUUUUUDAAA to his second worlds. You don't know how we respect him, so your text offended me a bit. |
|
+19
In the world finals he will participate |
|
+15
It was the whole contest with two people, ME_AJUUUUUDAAA stayed with us, but didn't worked in the problems, because that day the sunset was after the end of competition, one of the rules says that an incomplete team will be disqualified so it was necessary. For who are in the same situation, one option is to use the reserve, we didn't choose this for especif reasons. |
|
0
D? |
|
+1
Ignore ... |
|
On
MikeMirzayanov →
Codeforces Round 440 Div.1+Div.2 (and Technocup 2018 — Elimination Round 2), 9 years ago
+110
Clash with OpenCup. ;( |
|
+3
Is this a plug-in ? |
|
+1
When you use the second option, an element with key a1 is inserted on the map, so the runtime will be slower since you gonna have more values in your map |
|
0
It's not impossible http://mirror.codeforces.com/contest/869/submission/31077410 , there are others, you can see it on http://mirror.codeforces.com/contest/869/status/C , just set the language to Java ... I don't think there is suck lack, look to the top ones in the rating and you gonna see that some of them use Java |
|
0
Had you slept during the contest ? That was not a good decision |
|
+3
Well, I didn't understand your case, so I will explain the main idea in this problem, first we reduce the problem to: So, to solve this with the idea of the segment tree, we gonna keep for every segment what is the biggest element in that segment, how much times the biggest element appears on the segment , the second biggest segment on segment, the sum of the segment and a variable to indicate the lazy propagation If we gonna query, we just do the normal of the segment tree, taking the sum value of each node If I would say the complexity it would be in O(QN) in a trivial analise, but my intuition say that it's faster. My code is 30763830 . Can you say what is the complexity ? |
|
+6
Well, the construction of the segment tree is in O(N) and solve every query in O(logN), in the sparse table the construction is in O(NlogN) and every query in O(1) supposing that you find the log2 in constant time but the complexity of the function log2 of C++ is not constant, so in your code every query is solved in O(logN), you can try to use : |
|
+11
Looks like yes, in the tutorial in chinese they link this problem http://mirror.codeforces.com/contest/444/problem/C also, that can be solved with this trick |
|
+3
Think about divide and after join Spoiler |
|
+3
Probably yes, try to optimize the query in the range and how you find the index of some string, I used a trie for example. |
|
+8
If you will solve a problem and know that your idea is right by a formal reason you gonna probably receive AC, but if you use pure intuition ( what I am doing in everything) you can receive a lot of verdicts and waste a lot of time coding for nothing. Also this can be just something that I thought to accept my rating. :) |
|
+3
Wow, I always thought that to get the red color you should prove the algorithms before writing and do a lot of things that I don't do, maybe I have a chance of get the color. |
|
+3
Well, it's better to use sparse table and unordered_map in your code, but you would receive wrong answer because what calculate the length of a C string is strlen, since you are using sizeof, it's the same as to add the same thing for all values of strings. And you have to treat the case when l > r. |
|
+4
https://ideone.com/U1GmWp |
|
+1
Yes, it runs fine, in case my solution passed in 1746 ms. |
|
0
Basically, you have to see that some number may be 'lost', what I mean is that when we are compressing we are not considering the elements l[e] < X < r[e], for every e, so we can create a case were there is more that an range loses one of it's elements and after this our algorithm gives the wrong answer, but actually we don't have to take exactly all the X, if this situation gonna happen is because of there is two ranges with some intersection, so the values that matters are the borders of the ranges, it's not a good answer, but if it's not clear I can try to explain in a better way |
|
+3
My solution is: |
|
+22
If you are compressing the values, you should add (r[e] + 1) to the values to compress, at least I did this and passed |
|
+8
Was just me or someone else didn't know what is 'expected score' ? |
|
0
I also thought it should have passed, was nothing big, just optimizations. When I have time, I will recalculate everything, the constant factor shiuld be small. |
|
+13
Think in the following way: |
|
0
How to solve D? |
|
0
I solved with DP, but there was people that solved in 11 minutes, maybe there is an easier solution. My idea, lets consider every prefix of all strings and build an graph, where exists an edge between the prefix and the prefix without the first letter. It will be a forest. No two adjacent vertex can be at the set and just the vertexes that are prefix can be choose. Since you have to find maximun, you can apply dp. |
|
+48
:( . I hope you have another chance to hack me. |
|
+71
Waiting Petr screencast to see myself being hacked. :) |
|
+1
should be 4 |
|
+19
Google translate, I have a very poor english |
|
+1
Same thing, do you know if they can make the contest unrated for who was injured due to issue? I made a comment asking to admin during the contest, but I had no response until now. |
|
+22
too |
|
0
You can use persistent segment tree to this. I couldn't see the idea of the xor, instead I used persistent segment tree to hash(multiplying) and binary search, in a brief description, inserting the elements in the tree from the smaller to large in value, will make possible have the hash of a ordered segment of the queries, you can find the first element that mismatch in the binary search, if exists, after you can use another binary search for find the second, to see if they are the same, is just multiply the element that mismatch in the first with the hash of the interval of the second and the element that mismatch in the second with the hash of the interval of the first. https://www.codechef.com/viewsolution/14056539 |
|
0
My solution is O(n2 * 2n) how do you take off one of the n's of the complexity? Also how to put complexity right in the comments? Thanks in advance |
|
0
Contest is over, so let's discuss the problems, what is the solution for EvenOdd and Global Warning? I solved Global Warning, with dynamic programming, but it's certainly not the intended solution I had to made a lot of optimizations and it passed with 1.93s. |
|
+5
Your program fails in this case |
|
+3
In similar triangles, we have that the ratio of base/height has to be the same, so you can find the base for a height doing, heightX/heightB, where heightX is the height that you wanna know the base, and heightB is the full base height(the value of the height of the complete triangle). |
|
+11
This is a fake account, real account is ordan , he don't want to get downvotes. |
|
0
In the first operation p = 1 p = p + a[p] + k p = 1 + 3 + 1 p = 5 In the second operation p = 5 p = 5 + 7 + 1 p = 13 p > 10 |
|
0
How to solve A? |
|
0
Same problem here |
|
+3
I am in. |
