


Hello Humans,
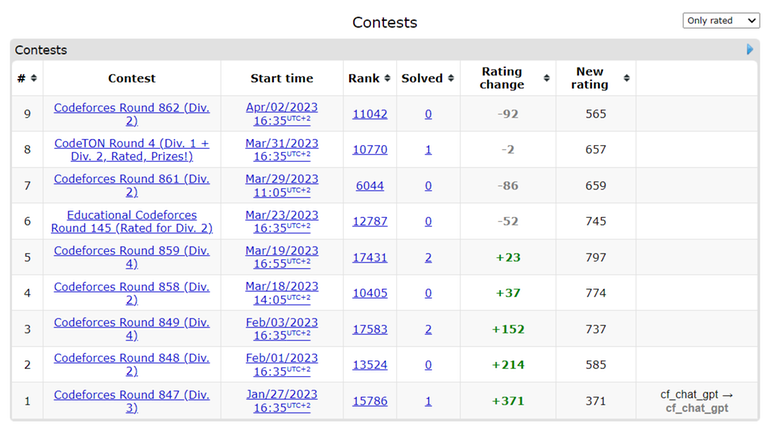
Find below the GPT-4 Rating (also check my profile), after 9 rated contests (first 3 contests were with the use of GPT-3/-3.5 though).
--> Maximum Rating: 797.
Contests distribution:
6 div-2 contests (where only 1 problem was solved)
1 div-3 contest (where 1 problem is solved)
2 div-4 contests (where 4 problems are solved)
Number of passed solutions: 6
Number of solutions which finally got TLE (passing the first pretests however): 9
General methodology:
the submitted code is purely the output of GPT, without any change.
no solution hints are provided to GPT.
4, 5 retries (in avg) are requested per problem. (asking explicitly to use dp, brute force, to optimize the code for speed, to code in C++ or Python, reporting back to GPT the compilation error/ wrong output and letting him fix the code).
Observations:
When asked to use brute force, GPT is almost providing a functionally correct solution, which will TLE. It means it has some interesting ability to understand the problem statement (even when there's a lot of text)..
The generated Python code was slightly better than the C++ code (i.e. passing more pretests)..
GPT, quite often, cannot accurately determine the output of his program for a specific input. It means it has no access to a compiler for correction feedback. It would be much interesting if GPT can test his code on the test samples before providing a solution, but he doesn't :(
Weak logic ability on div-2 problem A. Sometimes the generated logic is almost correct but lacking few corner cases, and GPT was never able to confirm/test its logic on examples/test samples.. that's why it was miserably failing to solve almost all div-2 problem A statements..
See You, when GPT-5 is out..
BR,

