


Segment Tree is a powerful data structure in programming, that is why it can still be optimized way more. In this blog I will explain one optimization that can make a basic segment tree slightly faster and easier to write. (idea and the code by me)
This does not work on range update range query segment trees.
Introduction:
Let's consider a point update range query segment tree, while querying we visit many of useless Nodes along the way in order to answer the query moving from the root downwards.
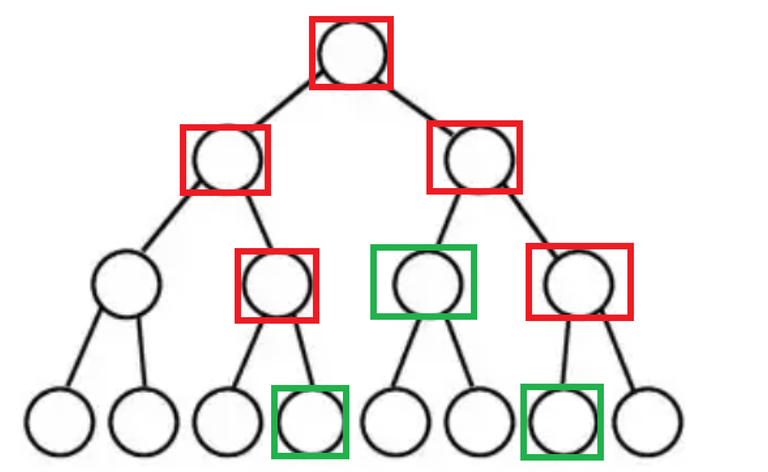
As you can see, there are nodes (marked in red) that are not needed during the recursion, and we only need to visit the important nodes (marked in green).
This is only true when querying in a point update segment tree or updating in a point query segment tree.
Main Idea:
We can solve a query range $$$[l, r]$$$ by noticing we can make it a smaller range $$$[l + X , r]$$$, where $$$X$$$ is any power of two but we need it to be maximum (in order to reduce the time complexity) and these two conditions should be true:
- $$$l + X - 1 \le r$$$. (We cannot go out of the range)
- $$$[l, l + X - 1]$$$ is a valid node in the segment tree.
At the end, we can solve it now because $$$X$$$ is $$$2$$$ power the minimum between $$$log_2(r-l+1)$$$ and $$$log_2( M \& -M )$$$ because it satisfies the first and second conditions and is the maximum value possible.
C++ Code:
We can preprocess $$$log_2(K)$$$ for each $$$1 \le K \le N$$$ in an array.
Note that this only works when $$$N$$$ (the number of leaves) is a power of 2.
At each step we calculate the size of the movement $$$X$$$ which is equal to $$$2^K$$$
The following codes calculate sum in the range $$$L$$$ to $$$R$$$, assuming the segment tree is built after possibly several update queries.
Recursive:
long long query(int l, int r){
if(l > r)return 0;
int node = N + l - 1;
int K = min(logs[node & -node], logs[r - l + 1]);
return (query(l + (1 << K), r) + seg[node >> K]);
}
Iterative:
long long query(int l, int r){
long long ret = 0;
while(l<=r){
int node = N + l - 1;
int K = min(logs[node & -node], logs[r - l + 1]);
ret = (ret + seg[node >> K]);
l += (1 << K);
}
return ret;
}
This can also be applied to range update point query segment trees:
void update(int l, int r, int val){
while(l<=r){
int node = N + l - 1;
int K = min(logs[node & -node], logs[r - l + 1]);
seg[node >> K] += val;
lazy[node >> K] += val;
l += (1 << K);
}
}
Benchmark:
| Size of the array and the number of queries | Time of SD-Segment-Tree /S | Time of Recursive-Segment-Tree /S | Time of Iterative-Segment-Tree /S |
| $$$N,Q = 2^{16}$$$ | 00.2847 | 00.3163 | 00.2292 |
| $$$N,Q = 2^{17}$$$ | 00.4311 | 00.5335 | 00.4414 |
| $$$N,Q = 2^{18}$$$ | 00.8322 | 00.9534 | 00.9729 |
| $$$N,Q = 2^{19}$$$ | 01.9915 | 02.1086 | 01.6837 |
| $$$N,Q = 2^{20}$$$ | 03.6747 | 04.4253 | 03.7347 |
| $$$N,Q = 2^{21}$$$ | 08.0204 | 08.6896 | 07.7844 |
| $$$N,Q = 2^{22}$$$ | 20.9266 | 27.0589 | 24.3542 |
| $$$N,Q = 2^{23}$$$ | 50.0656 | 61.9385 | 49.8065 |
Conclusion:
This variation has the same time complexity as the normal segment tree $$$O(log(N))$$$ per query, but might need more memory if you preprocess Logs array.
The constant factor is smaller because of the unnecessary nodes we don't visit but in practice the time it takes is not significant than the normal segment tree for smaller array sizes.
This can only be useful for squeezing in time limits or for becoming an easier way to implement segment trees because it is shorter.

