


Hello,
I created a project for training and analyzing your performance during contests: cp-trainer.com. I believe it has some unique features non-existent in competitive platforms and can provide as a more sensible tool for training, especially for more experienced users, who have participated already in a bunch of contests. Below I will briefly discuss its functionalities:
Problem recommender
In this section, we will discuss the heuristics used for problem recommender, the system offers for the user 10 problems with the highest value of this heuristics. First we need to introduce a couple of metrics:
- get_dict_accuracy — Dictionary of form (tag : average number of submissions to accept problem with this tag during contest)
- ratings_average_time_diffs — Dictionary of form (rating : average time in seconds to solve the problem with this rating during contest)
- tags_average_time_diffs — Dictionary of form (rating : average time in seconds to solve the problem with this tag during contest)
- problem_freshness — calculates the freshness of a problem by taking the contest in which it occurred (values normalized between 0,5 and 1)
- compute_tag_rating — Dictionary of form (tag : predicted user rating for this specific tag)
Now it is time to describe the heuristics:
- Let $$$r$$$ denote the rating of a problem, and let $$$\mathcal{T}$$$ denote the set of tags of that problem.
- Let
$$$A := \texttt{tags_average_time_diffs},\qquad Q := \texttt{get_dict_accuracy}$$$ be the dictionaries defined in the metrics. - Define:
$$$\sigma_{[L,H]} := \frac{H-L}{6},\qquad w_{[L,H]}(R,v) := \exp\!\left(-\tfrac{1}{2}\left(\frac{v-R}{\sigma_{[L,H]}}\right)^{2}\right).$$$ Where L and H are 800 and 3500 respectively (rating bounds). - Let
$$$\mathcal{M} := \texttt{compute_tag_rating}$$$ be the dictionary defined in the metrics, and let$$$\mathcal{T}' := \mathcal{T}\cap\operatorname{dom}(\mathcal{M}).$$$ Then define $$$h_1$$$ as$$$h_1 = \begin{cases} \dfrac{1}{|\mathcal{T}'|}\displaystyle\sum\limits_{t\in\mathcal{T}'} w_{[L,H]}\big(\mathcal{M}[t]+G,\, r\big), & \text{if } \mathcal{T}'\neq\varnothing, \\[1.2em] w_{[L,H]}(R_{\max}+G,\, r), & \text{otherwise.} \end{cases}$$$ where G is a constant set to 200 and $$$R_{\max}$$$ is the maximum rating of the user. - Let
$$$T := \mathcal{T}\cap\operatorname{dom}(A),\qquad S := \mathcal{T}\cap\operatorname{dom}(Q).$$$ - Let
$$$m_T := \frac{1}{|T|}\sum_{t\in T} A[t].$$$ For dictionary $$$A$$$ define normalization bounds$$$(\ell_A,u_A) := \big(\min_{x\in\operatorname{dom}(A)} A[x],\ \max_{x\in\operatorname{dom}(A)} A[x]\big).$$$ - Let
$$$m_Q := \frac{1}{|S|}\sum_{t\in S} Q[t],$$$ and for $$$Q$$$ define normalization bounds$$$(\ell_Q,u_Q) := \big(\min_{x\in\operatorname{dom}(Q)} Q[x],\ \max_{x\in\operatorname{dom}(Q)} Q[x]\big).$$$ - Define a normalization function (for $$$a\neq b$$$ and $$$x\in[a,b]$$$):
$$$\mathrm{Normalize}(a,b,x) := \frac{x-a}{\,b-a\,}.$$$ - Define
$$$h_2 := \mathrm{Normalize}(\ell_A,u_A,m_T),\qquad h_3 := \mathrm{Normalize}(\ell_Q,u_Q,m_Q).$$$
Intuitively, we want to recommend problems that reflect the user’s weaknesses, so $$$h_2$$$ and $$$h_3$$$ are larger, when problems with those tags typically take the user more time, and when the number of submissions required before accepting a problem for those tags is higher. - Let $$$c$$$ be the contest id. Define $$$\mathrm{fresh}(c)$$$ as the metric problem_freshness.
- Define
$$$\kappa(c) := \begin{cases} 0.4, & \text{if the contest is Div.4}, \\[4pt] 0.7, & \text{if the contest is Div.3}, \\[4pt] 1, & \text{otherwise.} \end{cases}$$$ Div.3 and Div.4 problems are treated as less interesting. - Let $$$U\sim\mathrm{Uniform}(0.3,0.4)$$$ be a random component introduced to diversify recommendations.
- The final heuristic $$$H(r)$$$ is
$$$H(r) = \kappa(c)\Big( h_1 * 3 + h_2 + h_3 + U + 1.5\cdot\mathrm{fresh}(c)\Big).$$$ (We add $$$1.5\cdot\mathrm{fresh}(c)$$$ rather than multiplying by $$$\mathrm{fresh}(c)$$$ to avoid giving very fresh contests an overwhelming advantage.)
Contest training picker
In this module user can choose one of the 4 contest modes depending on what he wants to train:
- Speed — The contest consists of 5 easy-medium problems. The problems' ratings are based on expected time to solve them i.e. the system expects the user to solve them in about 2000 seconds. The tags are chosen based on the weaknesses of the user (i.e. the tags, which take him more time on average). The idea is that the contestant during such contests will practice solving faster the easy-medium problems, so that will allow him to have more time on the harder ones.
- Hard problems — The contest consists of 3 problems from the list of 10 in the problem recommender.
- Weaknesses — The contest consists of 3 problems, all from topics, that user is weak at. The rough idea was to take the random 3 out of 5 tags with lowest value from the metrics compute_tag_rating and for each tag take the problem with rating as close as predicted rating on that tag + 200. In practice some comparator was used, which also takes into the account the freshness of the contest the problem comes from. (We rather want to solve the problems from fresher contests, since problems have changed a lot in past years).
- Upsolve — The contest consists of 3 problems, that contestant didn't solve during past contests (he either had rejected submissions on them or they were the first problems during the contest that he didn't get accepted) with the best quality according to problem recommender.
Note : The duration of the contest (never greater than 5 hours) is calculated automatically based on the expected time to solve the problems (user should solve some problems to not get discouraged, but of course not all). The contestant can limit this time by setting the max duration (he doesn't have to), however it is not very recommended, because the system will just discard some problems from the problemset to adjust the time.
User stats
In this mode there are presented plots, that show mainly different statistics about user's performance during the contests. Below we can see the sample statistic showing my average time to solve a problem during contest with specific tag. One can deduce that I have the most difficulties with problems including probabilities and schedules. What's important to mention is that it would be best to include this based on rating, however the data is too small, so we rely on the fact that it will average out across all ratings. Unfortunately with tags like flows, where problems mainly don't have low ratings, this won't be consistent, however with the most popular tags this should show good trends.

The included interesting statistics are (the time unit is measured in seconds):
- Average time to solve a problem by rating
- Average time to solve a problem by tag
- Average nr of attemps to solve a problem with specific tag — This is especially useful when we want to check on which problems we have difficulties with implementation/handling edge cases.
- User rating on a tag — For each tag we calculate the rating of a user on this type of problems based on the performance during contests.
- Average rating of solved/unsolved problems — This shows, what is the average highest solved problem during contests and the average lowest rating of the problem that user did not solve. It is useful e.g. when you want to check the rating of the average problem you're stuck on during contests and helps you to pick problems with appropriate rating during practice.
- Average rating change, when doing problems in order/not in order — This calculates the average rating change, when you do either the problems in order or not (e.g. you skip some problems etc.).
Compare yourself against the others
The idea for this section was to analyze for the user, how much he is worse than the average contestant with some specific rank. It was realized by taking statistics for 40 average random users across that specific rank , who participated in >=50 contests and were registered min 3 years ago. (that should approximate well the random user with some rank.)
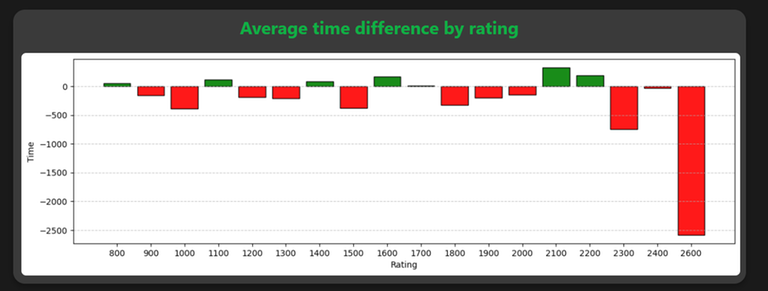
We can see in the picture above the sample statistic of me compared with the average grandmaster, telling, what is the average time difference (in seconds) of solving problem with some specifing rating. As we can see, I am slower on the most of the ratings, especially on the hardest ones.
The included statistics are almost the same like in the user stats section, here we just take difference between the contestant and average user of some rank.
Note: The green bars mean there is contestant's advantage, red otherwise.
Summary
The goal was to create the tool which will analyze user's performance during live contests and then based on that recommends adequate problems for training. Most apps focus on the stats of the user also during practice, which in my opinion doesn't provide the best insight e.g. because outside the contest you have unlimited time and also you can look at editorial.
If you find any bugs, please let me know and I will try to fix them as soon as possible. Any constructive criticism is also appreciated. Thanks for checking out the platform.

