


A
Idea: wakanda-forever Preparation: wakanda-forever
Let's say we have a sequence of numbers with an average equal to $$$k$$$.
Adding a number greater than $$$k$$$ increases the average, while adding a smaller one decreases it.
Therefore, the maximum average subarray is formed by taking the maximum element, since including anything smaller would only lower the average.
Hence, the final answer is the maximum element of the given array.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
vector<int> a(n);
for(int i = 0; i < n; i++) cin >> a[i];
cout << *max_element(a.begin(), a.end()) << endl;
}
return 0;
}
B
Idea: wakanda-forever Preparation: tridipta2806
We need to find a non-decreasing subsequence $$$p$$$ such that, after removing its characters from the string $$$s$$$, the remaining string $$$x$$$ is a palindrome.
Notice that if we take $$$p$$$ as all $$$0$$$s in $$$s$$$, then $$$x$$$ will contain only $$$1$$$s, which is always a palindrome. Similarly, if we take $$$p$$$ as all $$$1$$$s, $$$x$$$ will contain only $0$s, also a palindrome.
Both these choices give a valid non-decreasing subsequence (since all characters are equal).
Hence, a valid answer always exists — we can simply print all indices of either all $0$s or all $1$s in the string.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
string s;
cin >> s;
vector<int> pos;
for(int i = 0; i < n; i++) if(s[i] == '0') pos.push_back(i + 1);
cout << (int)pos.size() << '\n';
for(auto& z : pos) cout << z << ' ';
cout << '\n';
}
return 0;
}
C
Idea: wakanda-forever Preparation: wakanda-forever
We are allowed to choose any $$$x$$$ such that $$$0 \le x \le a$$$ and set $$$a := a \oplus x$$$. Our goal is to make $$$a$$$ equal to $$$b$$$.
Let's think of the binary representation of $$$a$$$. Consider the highest set bit (most significant bit) of $$$a$$$ and let's assume its position is $$$\operatorname{msb}(a)$$$.
At each operation, we are choosing $$$x \le a$$$, which implies that $$$\operatorname{msb}(x) \le \operatorname{msb}(a)$$$ (otherwise, we have $$$x \gt a$$$).
Now, we can surely say that $$$\operatorname{msb}(a \oplus x) \le \operatorname{msb}(a)$$$.
Thus, by performing the given operation, $$$\operatorname{msb}(a)$$$ will never increase. So, if $$$\operatorname{msb}(b) \gt \operatorname{msb}(a)$$$, the answer is $$$-1$$$.
Otherwise, we can always transform $$$a$$$ into $$$b$$$ in a constructive manner.
First, we set all bits below $$$\operatorname{msb}(a)$$$ one by one to ensure that every required bit can be manipulated. Then, for each bit that is $$$0$$$ in $$$b$$$, we unset it using an appropriate XOR operation.
By following this process, we can reach $$$b$$$ from $$$a$$$ in less than $$$60$$$ operations.
Time Complexity: $$$O(\log_2(a))$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int a, b;
cin >> a >> b;
if(__builtin_clz(a) > __builtin_clz(b)) cout << "-1\n";
else if(a == b) cout << "0\n";
else{
vector<int> val;
for(int i = 0; i < 31; i++){
int x = (1 << i);
if(x <= a && (a & x) == 0) a += x, val.push_back(x);
}
for(int i = 0; i < 31; i++){
int x = (1 << i);
if(x <= a && (b & x) == 0) val.push_back(x);
}
cout << val.size() << '\n';
for(auto z : val) cout << z << ' ';
cout << '\n';
}
}
}
D
Idea: wakanda-forever Preparation: wakanda-forever
We denote
Now, let us try to find $$$l$$$ first.
Consider two additional arrays representing the prefix sums of the arrays $$$p$$$ and $$$a$$$, defined as follows:
Analysing these, we can say that $$$\text{pref_sum_a}[i] \ge \text{pref_sum_p}[i]$$$ for all $$$i$$$. In fact, the inequality holds true only when $$$l \le i \le n$$$.
Thus, we can binary search for $$$l$$$.
At each stage, we make $$$2$$$ queries $$$\operatorname{query}(1, 1, \text{mid})$$$ and $$$\operatorname{query}(2, 1, \text{mid})$$$, and by comparing these, we can adjust $$$\text{left}$$$ and $$$\text{right}$$$ in binary search.
We can also find $$$r$$$ by querying suffixes in a similar way, but that would take a total of $$$4 \cdot \lceil \log_2(n) \rceil$$$ queries. This exceeds the query limit.
Instead, we can query the whole array once and find $$$r$$$. In other words,
So, after finding $$$l$$$, we can find $$$r$$$ in $$$2$$$ queries. Total queries will be equal to $$$2 \cdot \lceil \log_2(n) \rceil + 2$$$ ($$$ \lt 40$$$).
Time Complexity: $$$O(\log_2(n))$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
ll query(int type, int l, int r){
ll x;
cout << type << ' ' << l << ' ' << r << flush << endl;
cin >> x;
return x;
}
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
ll sum = query(2, 1, n);
sum -= ((n * (n + 1)) / 2);
ll diff = sum - 1;
int l = 1, r = n;
while(l < r){
int md = (l + r) / 2;
ll val1 = query(1, 1, md);
ll val2 = query(2, 1, md);
if(val1 < val2) r = md;
else l = md + 1;
}
cout << "!" << ' ' << l << ' ' << diff + l << flush << endl;
}
}
E
Idea: wuhudsm Preparation: wakanda-forever
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int n, k;
cin >> n >> k;
vector<int> a(n), cnt(n + 1, 0);
for(int i = 0; i < n; i++) cin >> a[i], cnt[a[i]]++;
int x = -1;
for(int i = 1; i <= n; i++) if(cnt[i] == 0){
x = i;
break;
}
if(x == -1){
for(int i = 0; i < k; i++) cout << a[n - 3 + (i % 3)] << ' ';
cout << '\n';
}
else{
int y = -1;
for(int i = 1; i <= n; i++) if(i != x && i != a[n - 1]){
y = i;
break;
}
vector<int> v = {x, y, a[n - 1]};
for(int i = 0; i < k; i++) cout << v[i % 3] << ' ';
cout << '\n';
}
}
}
F
Idea: Preparation: wakanda-forever
Note that if $$$[0,2,1]$$$ is a subsequence of permutation $$$p$$$, any interval that includes $$$0$$$ and $$$1$$$ must also include $$$2$$$. This implies that $$$\operatorname{mex}$$$ of any interval will not be equal to $$$2$$$. So, $$$2 \notin M$$$. Hence, $$$\operatorname{mex}(M) \le 2$$$.
Thus, we can always ensure that $$$\operatorname{mex}(M) \le 2$$$. Now, we only need to check when $$$\operatorname{mex}(M) = 0$$$ and $$$\operatorname{mex}(M) = 1$$$ are possible.
For $$$\operatorname{mex}(M)$$$ to be equal to $$$0$$$, $$$\operatorname{mex}$$$ of every interval must be positive. So, every interval must include $$$0$$$. This is possible only when all intervals intersect at a common point — that is, there exists at least one point that lies within every interval. Then we place $$$0$$$ at some common point and fill the remaining permutation.
Otherwise, for $$$\operatorname{mex}(M)$$$ to be equal to $$$1$$$, $$$\operatorname{mex}$$$ of each interval must not be equal to $$$1$$$. To ensure this, we have to place $$$0$$$ and $$$1$$$ in such a way that if an interval includes $$$0$$$, it must also include $$$1$$$. This is possible if there exists a point that is not simultaneously the starting point of one interval and the ending point of another. In other words, we should be able to find a position that does not act as both a left and a right boundary. Then we place $$$0$$$ at such a point and $$$1$$$ adjacent to it.
Else, we place $$$[0,2,1]$$$ as a subsequence first and then build the remaining permutation.
Time Complexity: $$$O(n + m)$$$ per testcase.
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define INF (int)1e18
void Solve()
{
int n, m; cin >> n >> m;
vector <int> l(m), r(m), f(n + 1), st(n + 1, 0), en(n + 1);
for (int i = 0; i < m; i++){
cin >> l[i] >> r[i];
st[l[i]] = 1;
en[r[i]] = 1;
for (int j = l[i]; j <= r[i]; j++){
f[j]++;
}
}
vector <int> ans(n + 1, -1);
auto fill = [&](){
vector <bool> used(n, false);
for (int i = 1; i <= n; i++) if (ans[i] != -1) used[ans[i]] = true;
int p = 0;
for (int i = 1; i <= n; i++){
if (ans[i] == -1){
while (used[p]) p++;
ans[i] = p;
used[p] = true;
}
}
for (int i = 1; i <= n; i++){
cout << ans[i] << " \n"[i == n];
}
};
for (int i = 1; i <= n; i++){
if (f[i] == m){
int ptr = 1;
ans[i] = 0;
fill();
return;
}
}
for (int i = 1; i < n; i++){
if (en[i] == 0){
ans[i] = 0;
ans[i + 1] = 1;
fill();
return;
}
if (st[i + 1] == 0){
ans[i] = 1;
ans[i + 1] = 0;
fill();
return;
}
}
assert(n >= 3);
ans[1] = 0;
ans[2] = 2;
ans[3] = 1;
fill();
}
int32_t main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
int t = 1;
cin >> t;
for(int i = 1; i <= t; i++)
{
Solve();
}
return 0;
}
G
Idea: wakanda-forever Preparation: wakanda-forever
We have to construct a tree with $$$n$$$ vertices such that $$$S = \sum_{{u, v} \in E} (u \cdot v)$$$ is a perfect square.
Instead of making it any random perfect square, let's try to make $$$S = (f(n))^2$$$ where $$$f(n)$$$ is an integer function of $$$n$$$.
Now, let's check if we can make $$$f(n) = n$$$. For $$$n = 5$$$, we can consider the following tree
where $$$S = 25 = (5)^2$$$.
Now that we know we have a tree $$$T$$$ with $$$n$$$ ($$$=5$$$) vertices having $$$S = n^2$$$. Using this, let's try to make a tree $$$T'$$$ with $$$n + 1$$$ vertices such that $$$S' = (n + 1)^2$$$. Note that $$$S' - S = 2n + 1$$$. So, while constructing $$$T'$$$, we have to add a new vertex $$$(n + 1)$$$ and also adjust this extra sum $$$2n + 1$$$.
We can achieve this in the following manner:
- add an edge between $$$1$$$ and $$$n + 1$$$,
- remove the edge between $$$1$$$ and $$$n$$$,
- add an edge between $$$2$$$ and $$$n$$$.
Such trees have the following structure:
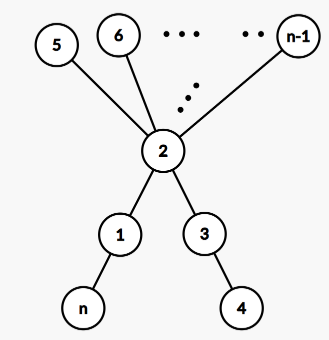
So, we can always make $$$S = n^2$$$ for all $$$n \ge 5$$$. For $$$n \lt 5$$$, we can just print sample outputs.
One can also assume $$$f(n) = n + 1$$$ and construct a similar solution with $$$S = (n + 1)^2$$$.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
if(n == 2){
cout << -1 << '\n';
continue;
}
if(n == 3){
cout << "1 3\n2 3\n";
continue;
}
if(n == 4){
cout << "1 2\n3 1\n4 1\n";
continue;
}
cout << "1 2\n";
cout << "2 3\n";
cout << "3 4\n";
cout << "1 " << n << '\n';
for(int i = 5; i < n; i++) cout << 2 << ' ' << i << '\n';
}
}
H
Idea: wuhudsm Preparation: wuhudsm

