


Доброго времени суток!
Предлагаю обсудить задачи прошедшей олимпиады. По ходу буду добавлять разборы.
Разбор задач.
Задача A.
Разбор от Alex_2oo8.
Всегда существует оптимальное решение следующего вида — разобьем всю последовательность на отрезочки и сначала заберем все числа из первого отрезочка (внутри отрезочка берем числа в обратном порядке), потом из второго отрезочка и так далее. К примеру, если мы разбили последовательность на отрезки вот так: [a1 a2 a3][a4 a5][a6 a7 a8 a9], то забирать числа будем в порядке a3, a2, a1, a5, a4, a9, a8, a7, a6. Доказывать это сейчас не буду.
Дальше получается довольно простое ДП: f(k) - - максимальная сумма, которую можно получить убрав префикс длины k. Переход будет такой:
f(k) = f(k - 1) + ak + 1, если последний отрезочек будет длины 1;
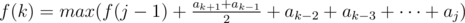 , если последний отрезочек — [j, k].
, если последний отрезочек — [j, k].Замечаем, что второй переход можно записать вот так:
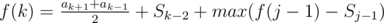 , где S — префиксные суммы и получаем константный переход.
, где S — префиксные суммы и получаем константный переход.
Задача C.
Решение от Azret.
После долгих размышлений я увидел закономерность. Итог:
int s[][5] = {
{1, 2, 3, 4, 5},
{4, 5, 1, 2, 3},
{2, 3, 4, 5, 1},
{5, 1, 2, 3, 4},
{3, 4, 5, 1, 2},
};
int main() {
freopen(NAME".in", "r", stdin);
freopen(NAME".out", "w", stdout);
int n, i, j, m, a[111][111];
scanf("%d%d", &n, &m);
for(i = 0; i < n; i ++)
for(j = 0; j < m; j ++)
a[i][j] = s[i % 5][j % 5];
for(i = 0; i < n; i ++){
for(j = 0; j < m; j ++)
printf("%d ", a[i][j]);
printf("\n");
}
return 0;
}
Задача D.
Разбор от heavenly_phoenix.
Код.
Задача E.
Разбор от SEFI2.
Простая динамика, не требует объяснения.
int main(){
cnt [0] = 1;
for (i = 1; n >= i ; i++){
cnt[i] += cnt[i - 1];cnt[i]%=md;
for (j = i - 1; j>=1 ; j--){if(a[j] > a[j + 1])break;cnt[i] += cnt[j - 1];cnt[i]%=md;}
for (j = i - 1; j>=1 ; j--){if(a[j] < a[j + 1])break;cnt[i] += cnt[j - 1];cnt[i]%=md;}
long long inter = 0;
for (j = i - 1; j>=1 ; j--){
if(a[j] != a[j + 1])break;
inter += cnt[j - 1];
}
cnt [i] -= inter;
cnt [i] = (cnt[i] + md) % md;
}
cout << cnt[ n ] << endl;
return 0;
}
Задача G.
Разбор от Azret.
Простой жадный алгоритм. На каждом этапе будем уравнивать предыдущий уровень с текущим пока это возможно. Если в конце остались лишние кубики (обозначим их как OST), то ответом будет текущая высота стены + OST / N.
Для лучшего понимания выкладываю код.
Задача I.
Разбор от heavenly_phoenix.
Код.
Задача L.
Разбор от pva701.
Первый факт — рассмотрим два возможных отрезка (произвольных длин), кандидатов на ответ, для которых выполнено условие, они либо не пересекаются, либо один вкладывается в другой, потому что если они как-то пересекаются, то у этих отрезков концевые элементы равны — поэтому можем просто взять один отрезок большей длины, таким образом увеличив длину.
Т.е. можем разбить весь массив на непересекающиеся подряд идущие отрезки. если запрос был просто на массиве — нам нужно было выбрать максимальный из этих отрезков.
Посчитаем для каждого i, такой максимальный индекс f[i] (f[i] >= i), что отрезок [i..f[i]] удовлетворяет условию.
Теперь, когда приходит запрос, начнем в l, перейдем в f[l] + 1, затем в f[f[l] + 1] + 1, и т.д, т.е будем прыгать на элемент после правой границы отрезка [i..f[i]], сохраняя максимум среди длин всех отрезков, по которым прошли. рано или поздно наступит следующее: либо мы просто придем в r (вернее, на следующий после r) — тогда все, максимум найден, либо следующий прыжок из i будет за правую границу, т.е f[i] > r, отметим, что в этом случае a[i] будет больше либо равен всех элементов на суффиксе [i..r]. тогда начнем ту же самую процедуру с r (мы так же заранее для всех j посчитали массив g[j] — минимальный индекс, такой что [g[j]..j] удовлетворяет условию). рано или поздно, g[j] станет меньше, чем l. тогда a[j] = a[i], т.к. если бы они были неравны, то мы могли перейти из j не за l (g[j] был бы больше l), т.к. a[i] был бы больше a[j] (как мы ранее отметили). Т.е. остается один отрезок, который нельзя никак уже разбить [i..j], учитываем его в нашем ответе.
Последний шаг — все вот эти переходы (f[i], g[j]) предподсчитаем в массив двоичных подъемов, и будем делать наши прыжки за log N.
Асимптотика — 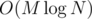
Задача J.
Разбор от netman.
Сначала очень просто можно узнать, какое максимальное число вхождений у нас может быть. Просто возьмем и посчитаем, какое максимальное кол-во вхождений какой-нибудь буквы мы имеем. Назовем это кол-во вхождений need.
Давайте научимся проверять какую-нибудь длину len. Проверять длину len — значит узнать, есть ли у нас такая подстрока длины len, что она имеет need непересекающихся вхождений.
Это можно делать за используя полиноминальные хэши. Посчитаем хэш всех подстрок длины len. Выпишем такие пары (hash, position) — хэш подстроки и позиция подстроки. Теперь давайте для каждого уникального hash выпишем все его position в возрастающем порядке. Теперь, зная все position для фиксированного hash не составляет труда посчитать максимальную подпоследовательность из этих позиций, что разница между соседними элементами подпоследовательности больше либо равна len (это условие нужно, потому что мы ищем непересекающиеся вхождения). Это можно легко подсчитать используя ДП:
Пусть a — это подпоследовательность, в которой нужно найти максимальную подпоследовательность, чтобы соседние элементы различались не меньше чем на len. Напоминаю, что все числа в этой последовательности в возрастающем порядке.
Теперь можно просто считать следующее ДП:
fi — максимальная длина подпоследовательности из префикса a длины i. Понятно, что f0 = 0.
Подсчет данного ДП ведется так:
fi = max(fj, f0) + 1, где j — такая максимальная позиция, что ai - aj ≥ len. Если такой позиции нет, то j = 0. Найти такое j можно бинарным поиском.
Как говорилось выше: давайте для каждого уникального hash выпишем все его позиции и запустим на них вышеописанное ДП. И возьмем максимум среди всех результатов запуска ДП. Это и будет максимальное кол-во непересекающихся вхождений строки, имеющей длину len. Теперь легко проверить подходит длина len или нет.
Также надо заметить, что если подходит длина len, то и длина len — 1 тоже подходит, значит можно использовать бинарный поиск, чтобы найти максимальное len, которое подходит.
Итоговая асимптотика решения: 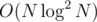
Для лучшего понимания выкладываю код.
Решение от izban.
Есть решение проще.
Сначала найдем need. Теперь фиксируем первую букву ответа (26 вариантов), и перебираем длину ответа, добавляя новый символ — суммарно будет сделано не больше n операций для каждой буквы. Итого, решение за 26n. Код.


