


Hello, Codeforces!
Some time ago I invented an interesting data structure and I'd like to share it with the community. Maybe, it was known before, and if you knew about it before my blog post, please share the link to the source.
What can the data structure do?
Given an array a that contains n elements and the operation op that satisfies some properties:
- Associative property: (x op y)op z = x op(y op z).
- Commutative property (optional, not required): x op y = y op x.
So, such operations as gcd, min, max, sum, multiplication, and, or, xor, etc. satisfy these conditions.
Also we have some queries l, r. For each query, we need to find al op al + 1 op ... op ar. Let's call such queries q(l, r).
My data structure can process such queries in O(1) time with 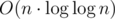 preprocessing time and memory.
preprocessing time and memory.
How it works?
1. Sqrt
Let's do a sqrt-decomposition. We divide our array in  blocks, each block has size . For each block, we compute:
blocks, each block has size . For each block, we compute:
- Answers to the queries that lie in the block and begin at the beginning of the block (prefix-op)
- Answers to the queries that lie in the block and end at the end of the block (suffix-op)
And we'll calculate another one thing:
between[i, j]i ≤ j -- answer to the query that begins at the start of block i and ends at the end of block j. Note that we have blocks, so the size of this array will be 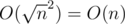 .
.
Let's see the example.
Let op be + (we calculate sum on the segment) and we have the following array a:
1 2 3 4 5 6 7 8 9
It will be divided onto three blocks: 1 2 3, 4 5 6 and 7 8 9.
For first block prefix-op is 1 3 6 and suffix-op is 6 5 3.
For second block prefix-op is 4 9 15 and suffix-op is 15 11 6.
For third block prefix-op is 7 15 24 and suffix-op is 24 17 9.
between array is:
6 21 45
- 15 39
- - 24
It's obvious to see that these arrays can be easily calculated in O(n) time and memory.
We already can answer some queries using these arrays. If the query doesn't fit into one block, we can divide it onto three parts: suffix of a block, then some segment of contiguous blocks and then prefix of some block. We can answer a query by dividing it into three parts and taking op of some value from suffix-op, then some value from between, then some value from prefix-op.
But if we have queries that entirely fit into one block, we cannot process them using these three arrays. So, we need to do something.
2. Tree
We cannot answer only the queries that entirely fit in one block. But what if we build the same structure as described above for each block? Yes, we can do it. And we do it recursively, until we reach the block size of 1 or 2. Answers for such blocks can be calculated easily in O(1).
So, we get a tree. Each node of the tree represents some segment of the array. Node that represents array segment with size k has 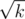 children -- for each block. Also each node contains the three arrays described above for the segment it contains. The root of the tree represents the entire array. Nodes with segment lengths 1 or 2 are leaves.
children -- for each block. Also each node contains the three arrays described above for the segment it contains. The root of the tree represents the entire array. Nodes with segment lengths 1 or 2 are leaves.
Also it's obvious that the radius of this tree is 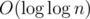 , because if some vertex of the tree represents an array with length k, then its children have length .
, because if some vertex of the tree represents an array with length k, then its children have length . 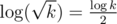 , so
, so 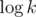 decreases two times every layer of the tree and so its height is . The time for building and memory usage will be , because every element of the array appears exactly once on each layer of the tree.
decreases two times every layer of the tree and so its height is . The time for building and memory usage will be , because every element of the array appears exactly once on each layer of the tree.
Now we can answer the queries in . We can go down on the tree until we meet a segment with length 1 or 2 (answer for it can be calculated in O(1) time) or meet the first segment in which our query doesn't fit entirely into one block. See the first section on how to answer the query in this case.
OK, now we can do per query. Can it be done faster?
3. Optimizing the query complexity
One of the most obvious optimization is to binary search the tree node we need. Using binary search, we can reach the 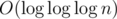 complexity per query. Can we do it even faster?
complexity per query. Can we do it even faster?
The answer is yes. Let's assume the following two things:
- Each block size is a power of two.
- All the blocks are equal on each layer.
To reach this, we can add some zero elements to our array so that its size becomes a power of two.
When we use this, some block sizes may become twice larger to be a power of two, but it still be 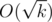 in size and we keep linear complexity for building the arrays in a segment.
in size and we keep linear complexity for building the arrays in a segment.
Now, we can easily check if the query fits entirely into a block with size 2k. Let's write the ranges of the query, l and r (we use 0-indexation) in binary form. For instance, let's assume k = 4, l = 39, r = 46. The binary representation of l and r is:
l = 39(10) = 100111(2)
r = 46(10) = 101110(2)
Remember that one layer contains segments of the equal size, and the block on one layer have also equal size (in our case, their size is 2k = 24 = 16. The blocks cover the array entirely, so the first block covers elements (0 - 15) (000000 - 001111 in binary), the second one covers elements (16 - 31) (010000 - 011111 in binary) and so on. We see that the indices of the positions covered by one block may differ only in k (in our case, 4) last bits. In our case l and r have equal bits except four lowest, so they lie in one block.
So, we need to check if nothing more that k smallest bits differ (or l xor r doesn't exceed 2k - 1).
Using this observation, we can find a layer that is suitable to answer the query quickly. How to do this:
For each i that doesn't exceed the array size, we find the highest bit that is equal to 1. To do this quickly, we use DP and a precalculated array.
Now, for each q(l, r) we find the highest bit of l xor r and, using this information, it's easy to choose the layer on which we can process the query easily. We can also use a precalculated array here.
For more details, see the code below.
So, using this, we can answer the queries in O(1) each. Hooray! :)
Conclusion
We have a data structure that asymptotically answers the queries on a segment very fast. But, the constant of this data structures is big enough. Also it doesn't support changing the elements. But it can be modified to perform modification queries in something about  for modifying a single element. But in this case, query complexity becomes . You can think how to do this as an exercise.
for modifying a single element. But in this case, query complexity becomes . You can think how to do this as an exercise.
Problems
https://www.codechef.com/NOV17/problems/SEGPROD
Code
If you have some suggestions on how to improve this data structure or how to modify it, or something is written unclear and needs more explanation, feel free to write in the comments.
UPD: As it's noticed in the comment, this algorithm (and some more optimal ones) can be found in this article (thanks Rafbill).
UPD2: As geniucos described in the comment, we can improve the time complexity to O(nα(n)) for preprocessing if x op x applies. Let the block size is  , not . We use a sparse table instead of between array. We will have
, not . We use a sparse table instead of between array. We will have 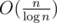 blocks and time complexity for building a sparse table will still be
blocks and time complexity for building a sparse table will still be 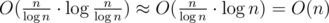 . The tree will have much smaller layers and we still have O(1) per query.
. The tree will have much smaller layers and we still have O(1) per query.


