


Hello Codeforces,
Just wanted to leave this explanation here in case anyone needs one for the Hunt-Szymanski algorithm; I wasn't able to find a good explanation online and mostly figured it out by reading through a github file here, where you can find the implementation.
The Hunt-Szymanski Algorithm is an algorithm that finds the LCS in O((N + K) log N) time complexity, where N is the maximum length of a string and K is the number of matches between the two strings. This is especially useful when the number of occurrences of each letter is bounded, like if each letter is guaranteed to appear at most twice or thrice in each string.
For example, if the two strings are "abbcd" and "cdea", the matches would be (0, 3), (3, 0), and (4, 1) where the indices are zero-based. Then K would be 3 since there are 3 pairs where the characters of each string are the same. Clearly, K = N^2 at worst.
The usual LCS algorithm figures out the LCS of every pair of prefixes of the two strings: you should know this algorithm before learning this one. This has O(N^2) runtime.
However, we can do better by noting that the only pairs of indices that really matter are the ones where the two strings match. For example if our strings are "acbdd" (str1) and "cabad" (str2), we can mark the matching indices as follows:
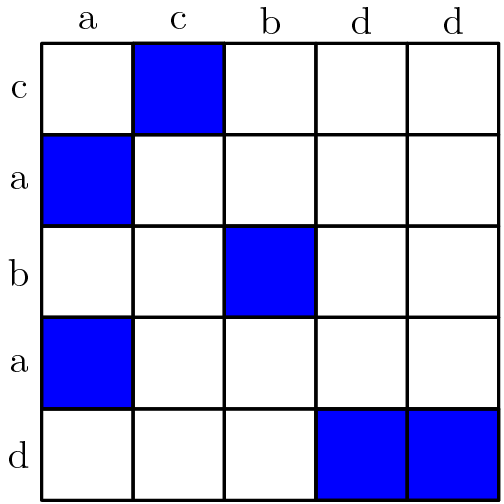
Now, our problem is reduced to finding a sequence of blue squares such that their x-coordinates are strictly increasing, while their y-coordinates are strictly decreasing. In the above diagram there are 4 such possible LCS's with length 3.
How do we find this maximum length?
First, we can "reverse" our second string such that every character maps to a vector of indices where that character appears in the second string. This allows us to quickly find matches by searching through the first string. Call this array rev, so for example rev['a'] returns the vector {1, 3}.
Then, we initialize a vector dp, such that dp[i] is the minimum prefix length of y we must use to make an LCS of length i. dp should start by having a length of 1 with only value -1 (since we don't need any matching pairs to have an LCS length 0).
We can loop through the first string's indices in order (call the index i), and use the reverse array to loop through the second string's indices in reverse order (call the index j), so we are basically iterating through the grid column by column from left to right, and within each column bottom to top.
Now, let y be rev[str1[i]][j], so that y is the second string's index of the blue cell we are visiting. (Called "x" in implementation, not sure why) Now, notice that since we are iterating from left to right, every cell we visited is to the left of this cell unless it is in the same column. Now, we can update dp using this information.
If the last value of dp is less than the value of y, we can push back y into the vector denoting that y is now the minimum possible index to attain an LCS with length equal to the index.
Otherwise, we can reduce a distance using this new pair. For example, say we previously set dp[2] = 3 and dp[3] = 5, and a new match appears at (4, 4). Since we are able to attain an LCS of length 2 with the first 4 letters of str2, we can simply append this match to attain an LCS of length 3 using the first 5 letters of str2. Now dp[3] = 4, reduced from 5.
Generally, we find the first value of dp greater than our index and set it to the index. The smallest such index can be found using binary search.
By repeating this for each of the blue squares we can eventually attain the maximum LCS length, which is the length of dp.
Since it's a bit hard to explain this with words, here's a walk-through of the algorithm with the strings "acbdd" and "cabad" (Tracing through with a diagram should be helpful.)
First we initialize rev:
rev['a'] = {0}; rev['b'] = {2}; rev['c'] = {1}; rev['d'] = {3, 4};
Now we loop through the matches.
Column 0: Our first match is at (0, 3). Now by using the first 4 indices of str2, we can attain an LCS of 1. Thus, dp[1] = 3. Now, our second match is at (0, 1). Instead of using 4 indices of str2, we can use 2 to make an LCS of 1 instead so we set dp[1] = 1.
Column 1: Another match is at (1, 0). We reduce dp[1] again since we only need 1 index of str2 to make an LCS of 1. dp[1] = 0.
Column 2: If we append this match (2, 2) to our first matches at dp[1], we can create an LCS of 2. Thus we set dp[2] = 2.
Column 3: We have a new match (3, 4) that we can append to our previous string, so we set dp[3] = 4.
Column 4: Another match is at (4, 4), but that doesn't help since appending this to (2, 2) still requires the first 5 characters of str2.
Now, our answer is the length of dp = 3.
I hope you found this useful; please put anything that should be clarified in the comments.

