164A - Переменная, или Туда и обратно
Кратко о решении — dfs, O(E).
Пустим поиск в глубину из всех вершин, где переменная присваивается. Пометим все посещенные.
Пустим поиск в глубину по обратным ребрам из всех вершин, где переменная используется. Запретим ему проходить по вершинам, где переменная присваивается. Пометим все посещенные.
Вершины помеченные оба раза — это и есть те вершины, где состояние Васи кого-то волнует
164B - Древние берляндские иероглифы
Кратко о решении — метод двух указателей, O(N).
Давайте для удобства предположим, что каждый символ в каждой строке встречается ровно один раз.
Тогда у нас есть перестановка pi (позиция во второй строке i-го символа первой строки)
Решение за квадрат теперь такое: фиксируем начало подстроки и идем по ней вперед, при этом параллельно идем по подпоследовательности и следим, что и там, и там мы не прошли больше круга.
Решение за линию.
Будем теперь идти двумя указателями "начало подстроки" и "конец подстроки". Параллельно будем хранить очередь — текущая парная подпоследовательность. В очереди все pi обязательно возрастают (этого не сложно достичь, т.к. можно прибавлять к pi число n столько раз, сколько нужно. То что подпоследовательность не зациклилась проверяется так queue.first - queue.last < n. Значит, мы можем двигать конец подстроки вперед, пока это неравенство выполнено. Как только конец подстроки нельзя увеличить, увеличиваем начало. Заметим, что начало и конец подстроки также двигаются по кругу.
Альтернативное решение:
После того, как мы увидели перестановку p, можно воспользоваться методом двоичных подъемов и получить решение за O(NlogN), которое тоже получало Accepted.
164C - Автоматное программирование
Кратко о решении — MinCost flow, O(N2 K) или O(NlogN K).
Самое главное было — увидеть граф, где вершины = задания, множества заданий, выполняемые автоматами = вершиннонепересекающиеся пути, а ребра можно было строить двумя способами (см. ниже).
Как сделать пути вершиннонепересекающимися? Раздвоить вершины.
Как добавить стоимость? Между двумя половинками вершины должна быть стоимость - ci.
Первый способ, граф G1 : вершины A, B соединены ребром, если после задания A можно успеть выполнить задание B тем же автоматом. Тогда ребер O(N2).
Второй способ, граф G2 : все вершины упорядочены по si из вершины i ведут два ребра — в i + 1 (не берем i задание, пробуем взять следующее) и в вершину с минимальным j : sj ≥ si + ti (берем задание, переходим к минимальному из возможных следующих). Тогда ребер O(N).
Если вы пользовались первым способом и для поиска пути реализовали одну из вариаций алгоритма Форда-Беллмана, то вы могли получить TL. Собственно пока из-за того, что на java все медленно, TL не подняли, все Форд-Беллманы кроме одного особенного получали заслуженный TL.
Чтобы в G1 использовать Дейкстру с потенциалами, удобнее всего было заметить, что граф ацикличен и первый раз расстояния посчитать за O(E).
164D - Минимальный диаметр
Кратко о решении — бинпоиск по ответу, а внутри перебор за O(Fib(K)).
Правильное решение состояло из четырех несложных идей:
1) Нужно из N2 ребер покрыть удаленными вершинами сколько то максимальных. Когда мы покрываем еще не покрытое ребро, у нас 2 варианта это сделать — выбрать 1 конец, выбрать второй конец. Эта идея сама по себе давала асимптотику O(2K * N).
2) Если сделать бинпоиск по ответу, то мы решаем более простую задачу: можно ли покрыть первые X ребер K вершинами? Т.е. правда ли, что размер контролирующего множества в таком графе не более K.
3) Если мы теперь внутри бинпоиска не берем какую-то вершину, то мы должны брать всех ее соседей в уменьшенном графе. Из этого можно сделать 2 вывода: во-первых, если есть вершина степени больше чем K, ее брать обязательно, во-вторых, не выгодно брать вершину степени 1.
4) Теперь решение работает за log * Fib(K) * K, где log — константа от бинпоиска, Fib(K) — K-е число Фибоначчи, K --- максимальная степень вершины в уменьшенном графе.
Почему Fib(K)? Теперь, когда мы делаем выбор, в одной ветке рекурсии K уменьшается на 1, а в другой хотя бы на 2... На лицо числа Фибоначчи.
P.S. Из похожих задач я знаю вот эту: задача 2 с РОИ 2009-2010
164E - Поликарп и работы
Кратко о решении — жадность + куча запросов на отрезке, асимптотика = O(NlogN).
В этой задаче так и не получилось написать очевидное условие...
Расскажу некоторую легенду, чтобы дать понять, что задачка не искусственна, взята из "реальной жизни".
Все вы читали задачу C. Давайте чуть поменяем ее, скажем, что автомат у нас один, а работа должна начаться не раньше li, закончиться на позже ri, а времени на нее уйдет ti. Рассмотрим случай, когда li и ri возрастают.
Попробуем придумать жадное решение: отсортируем все работы по li и будем пытаться "брать". Если можно взять, то выполнять работу будем в минимально возможный момент времени.
Это жадное решение не сложно завалить тестом (L=1, R=10, T=10), (L=2,R=11,T=5), (L=3,R=12,T=5).
Поэтому давайте жадность улучшим, попробуем, если добавить в конец не получается менять на кого-нибудь так, чтобы правый конец (последний использованный момент времени) максимально уменьшился.
Собственно задача E состояла в моделировании процесса. В том, чтобы запрограммировать эту жадность.
Итак, решение:
Для каждого отрезка определим величину shifti = si — li (насколько можно отрезок подвинуть влево).
У нас уже есть k отрезков. Добавляем k + 1-й, не получается. Пробуем сделать замену. Перебираем все отрезки в порядке уменьшения индекса, смотрим, насколько уменьшится правый конец.
Это min(ti, min по j=i+1..k (shiftj)).
Т.е. ни один из отрезков из 1..i уже не даст ответ лучше, чем min(max по j=i+1..k (tj), min по j=i+1..k (shiftj)).
Зачем я выдумал этот максимум? Дело в том, что под минимумом теперь две функции, убывающая и возрастающая. Значит, максимум можно искать бинарным или троичным поиском.
Следующая идея заключается в том, что когда мы нашли оптимальную замену besti, то чтобы пересчитать все shiftj, достаточно сделать вычитание на отрезке besti+1..k
Полученное решение имеет асимптотику O(Nlog2N). Его можно улучшить до O(NlogN), заменив бинпоиск, а внутри него обращение к дереву поиска или дереву отрезков на один спуск по дереву.
UPD:
По просьбам участников выкладываю "разбор" задач A,B,C второго дивизиона.
Задачи второго дивизиона я не готовил, не читал, не решал. Но вроде бы, если почитать, они решаются так, как описано ниже. Так что разбор второго дивизиона не стоит воспринимать как авторский, это просто рассказ "как бы я решал эти задачки". Надеюсь, нигде не наврал.
Задача A
X = (a1 + a2 + ... + an + b) / n.
Если X меньше максимального ai, то нельзя сделать так, как просят. Иначе нужно вывести числа X — ai.
Задача B
Решение #1, жадное:
Если между двумя точками больше 11 или меньше 2 символов, то нельзя так разрезать.
Если перед первой точкой больше 8 символов, то нельзя так разрезать.
Если между после последней точки больше 3 символов, то нельзя так разрезать.
А иначе режем жадно :-) Если количество символов между двумя точками равно X, то разрез проводится в позиции min(8,X-1).
Решение #2, DP:
is[i] — можем ли мы разрезать префикс длины i.
Изначально is[0] = 1, остальные нули.
Теперь перебираем i в порядке возрастания и если is[i] = 1, пытаемся сделать переход в i + 1..i + 12.
Задача C
Основная идея — жадность.
Если минимум на всем массиве равен нулю, то задача естественным образом распадается на подзадачи, а иначе нужно уменьшить весь отрезок на 1.
Решение #1, ищем минимум
Ищем минимум в массиве, вычитаем 1 из всего массива min раз, задача распадается на несколько (т.е. в каждый момент времени, задача = отрезок исходного массива). Минимум на отрезке нужно искать быстро, за O(logN), например.
Решение #2, простое
Будем идти слева направо и хранить, сколько у нас отрезков уже начато торчит налево, пусть это X. Если X < ai, то нужно начать несколько новых отрезков, если же X > ai, то несколько уже начатых нужно закончить в позиции i - 1. Начатые отрезки можно хранить в стэке. Хранить, конечно, нужно только позицию начала. Новый X будет равен ai.
Конец.









 -- сканирующая прямая с деревом Фенвика.
-- сканирующая прямая с деревом Фенвика. на get-запрос. Если да, пожалуйста, ссылку в студию. Если нет, докажите (опровергните), пожалуйста, идею кэширования (ниже подробно описана).
на get-запрос. Если да, пожалуйста, ссылку в студию. Если нет, докажите (опровергните), пожалуйста, идею кэширования (ниже подробно описана).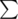 f[i,0]
f[i,0]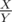 , где
, где 