


490A - Командная олимпиада
Будем формировать команды жадно. То есть, если у нас есть по одному школьнику каждого из трёх типов, которые ещё не относятся ни к какой команде, то из них можно сформировать новую команду. И так делее, пока достигнется ситуация, когда мы не сможем сформировать команду. Таким образом, общее число команд — это минимум из количеcтва школьников каждого из трёх типов. Решение получается за O(N), если сложить индексы школьников каждого типа в три отдельных массива. Можно решать и за O(N2), если каждый раз пробегаться по всему массиву в поисках школьника конкретного типа для очередной команды.
490B - Очередь
Эту задачу будем решать конструктивно. Определим, кто находится на первом месте — это студент с таким номером, который встречается среди чисел ai, но не встречается среди чисел bi (потому, что ни для кого из остальных он не находится позади). Определим, кто находится на втором месте — это студент, который стоит позади первого, а поскольку у первого студента число ai равно 0, то соответствующее ему число bi и будет его номером (то есть число из пары [0, bi]).
Теперь будем определять остальных, начиная с третьего. Это делается очень просто по предпоследнему уже определенному номеру студента. Номер очередного студента, это число bi в некоторой паре, где число ai, это номер предпоследнего уже найденного номера студента (то есть число из пары [ans[i - 2], bi]. Решение достаточно просто осознать, разбирая пример из условия.
490C - Взлом шифра
Будем решать эту задачу следующим образом. Сначала проверим все префиксы заданного числа — делятся ли они на число a. Это можно сделать за O(N), где N — это длина заданного числа C. Зная остаток от деления префикса, заканчивающегося в позиции pos, можно пересчитать остаток для позиции pos + 1 следующим образом: rema[pos + 1] = (rema[pos] * 10 + C[pos + 1]) % a.
Затем нужно проверить все суффиксы числа C — делятся ли они на число b. Зная остаток от деления суффикса, начинающегося в позиции pos, можно пересчитать остаток для позиции pos - 1 следующим образом: remb[pos - 1] = (C[pos - 1] * P + remb[pos]) % b, где P — это 10^(L - 1) по модулю b, L — это длина суффикса (величину P можно вычислять параллельно).
Теперь нужно перебрать все позиции pos и проверить, можно ли сделать разрез числа C после этой позиции. Для этого необходимо выполнение четырех условий: префикс числа C, заканчивающийся в позиции pos, делится на число a; суффикс числа C, начинающийся в позиции pos + 1, делится на число b; длины префикса и суффикса ненулевые; суффикс не может начинаться с цифры 0. Если все эти условия выполняются, то после позиции pos можно сделать разрез. Если же все позиции не подходят, то решения не существует и следует вывести NO.
490D - Шоколадки
Заметим, что мы можем преобразовывать число следующим образом, либо делить на два либо делить на три и домножать на два. Изначально уберём из чисел все степени двоек и троек. После этого проверим, возможно ли удалив все эти степени добиться равенства площадей, если нет, то ответа не существует. Посмотрим на разность количества троек в факторизации шоколадок. Понятно, что именно на такое число нужно сократить одну из шоколадок, в зависимости от знака. Выполним данную операцию, пересчитывая количество двоек, и после сделаем то же самое для них.
490E - Восстановление возрастающей последовательности
Будем решать данную задачу жадным образом. Будем перебирать заданные числа сначала и пытаться сделать из текущего числа минимальное, но большее предыдущего. Обозначим текущее число — cur, а предыдущее число — prev.
Если длина числа cur меньше длины числа prev — следует вывести NO, задача не имеет решения.
Если длина числа cur больше длины числа prev — заменим все знаки ? в числе cur на цифру 0, за исключением случая, когда знак ? стоит в первой позиции — заменим его на цифру 1, так как числа в ответе не могут иметь лидирующих нулей.
Остался случай, когда длины чисел cur и prev равны. По условию задачи, каждое число в ответе должно быть строго больше предыдущего. Переберем позицию pos, в которой префикс числа cur больше чем префикс числа prev. Теперь попробуем для этой позиции сделать минимально возможное число, большее prev. Во всех позициях posi в которых стоит знак ? и меньших pos, поставим цифру, которая стоит в соответствующей позиции числа cur. А во всех позициях posi в которых стоит знак ? и больших pos, поставим цифру 0. Если в числе cur в позиции pos стоит знак ?, то поставим в эту позиции цифру на 1 большую, чем prev[pos]. Если в prev[pos] стоит цифра 9, то данная позиция pos не подходит для рассмотрения.
Если полученное число меньше либо равно предыдущему, то данная позиция pos не подходит. Из всех подходящих позиций pos выберем минимальное число, полученное в результате описанных выше действий, присвоим ему число cur и продолжим восстановление ответа. Если подходящих позиций pos на каком-то шаге не нашлось — следует вывести NO.
490F - Турне по Древляндии
Задача является обобщением нахождения наибольшей возрастающей подпоследовательности в массиве, поэтому наверняка решается диначеским программированием. Будем делать динамику d[(u, v)], в которой состоянием является ориентированное ребро в графе (u, v). В динамике будем хранить максимальное число вершин, где группа могла дать концерты на каком-то простом пути, заканчивающемся в вершине v и проходящем через вершину u. Причём в вершине v точно будет концерт.
Чтобы посчитать значение для ребра (u, v) нужно посчитать значение для всех рёбер (x, y) таких, что существует простой путь, начинающийся в вершине x, проходящий через вершины y и u и заканчивающийся в вершине v.Чтобы найти все рёбра (x, y), удовлетворяющие этому условию, нужно просто запустить обход в глубину из вершины u, которому будет запрещено заходить за вершину v. Тогда все ребра, которые он обойдёт, нужно просто взять с обратной ориентацией. Таким образом если r[y] < r[v], то d[(u, v)] = max(d[(u, v)], d[(x, y)] + 1). В итоге получется решение за O(N2) и (O(N2)) памяти. Память можно сократить до линейной если научиться получать индексы ориентированных рёбер без обращения к двумерному массиву.







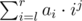 . Вам же нужно посчитать
. Вам же нужно посчитать 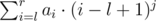 , можно записать как
, можно записать как 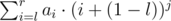 . Теперь нужно расписать на листочке последнюю сумму для первых степеней, хотя бы до трех, и отнять из первой суммы (ответ на запрос дерева) вторую (то что нужно получить). Получится выражение, которое нужно вычесть из числа запроса для получения ответа на задачу. Это просто бином Ньютона без старшей степени.
. Теперь нужно расписать на листочке последнюю сумму для первых степеней, хотя бы до трех, и отнять из первой суммы (ответ на запрос дерева) вторую (то что нужно получить). Получится выражение, которое нужно вычесть из числа запроса для получения ответа на задачу. Это просто бином Ньютона без старшей степени. 
