


Hello everyone! :)
In case you missed our e-mail, we inform you that the second round of the Yandex.Algorithm Optimization track has been started today at 10:00 UTC +3. Like the first round, it will last for 7 days. There is one task which does not have the complete solution that can be found in a few seconds, but you can try different approaches to score as many points as possible. According to the results of the two rounds (see section 3 in https://contest.yandex.com/algorithm2018/rules/ — rules of combining results are the same for algorithmic and optimization tracks) we will determine the winners of the Optimization track and 128 future owners of the t-shirts with the logo of the competition.
We have prepared for you a task that simulates the web crawling performed by the search robot. We offer you to experience the complexity of indexing sites and try to optimize the crawling of the Internet — this is just one of the problems that software engineer solve at Yandex. Of course, the task was quite simplified, because you have only a week to solve it, but can you come up with good solution how to assign sites to robots optimally?
Registration for the contest is still open, so you can join at any time — good luck!







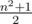 . It's easy to see that it's possible to lay out
. It's easy to see that it's possible to lay out 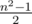 "domino pieces"
"domino pieces" 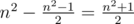 .
.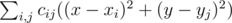 is minimum possible. This expression can be rewritten as
is minimum possible. This expression can be rewritten as 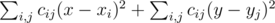 . Note that the first part doesn't depend on
. Note that the first part doesn't depend on 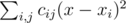 , the second part is minimized similarly. As the expression in the brackets doesn't depend on
, the second part is minimized similarly. As the expression in the brackets doesn't depend on 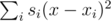 , where
, where 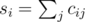 . Now it's enough to calculate the required value for all possible values of
. Now it's enough to calculate the required value for all possible values of 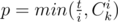 strings containing
strings containing 