


Problem Statement:
Yes, you are developing a 'Love calculator'. The software would be quite complex such that nobody could crack the exact behavior of the software.
So, given two names your software will generate the percentage of their 'love' according to their names. The software requires the following things:
- The length of the shortest string that contains the names as subsequence.
- Total number of unique shortest strings which contain the names as subsequence.
Now your task is to find these parts.
Input Input starts with an integer T (≤ 125), denoting the number of test cases.
Each of the test cases consists of two lines each containing a name. The names will contain no more than 30 capital letters.
Output For each of the test cases, you need to print one line of output. The output for each test case starts with the test case number, followed by the shortest length of the string and the number of unique strings that satisfies the given conditions.
You can assume that the number of unique strings will always be less than 263. Look at the sample output for the exact format.
Sample Input:
3
USA USSR
LAILI MAJNU
SHAHJAHAN MOMTAJ
Sample Output:
Case 1: 5 3
Case 2: 9 40
Case 3: 13 15
How to solve the second part of the problem? I mean how can I find "Total number of unique shortest strings which contain the names as subsequence."?







Suppose that we have solved the first part by constructing the DP table for LCS. Now we can backtrack to obtain indices of common characters for both strings that form this LCS.
Let's define them as {a1, a2, ..., ak} for the first string A, and {b1, b2, ..., bk} for the second string B.
Of course, all unique shortest strings will contain these common characters, and the rest of A and B between these characters could be shuffled in all possible ways mantaining the relative order.
For example, consider the case LAILI and MAJNU where a1 = b1 = 2 (the A character).
Before these indices there are only L and M letters which can be ordered as LM or ML (2 combinations in total).
Next char will be A, and the rest (ILI and JNU) can be ordered in many ways such as ILIJNU, ILJNUI, ILJNIU etc.
There are 20 such combinations in total. We multiply all combinations together and obtain the answer 40.
Thus, we should calculate the number of shuffles for every substring between common LCS characters (ai... ai + 1) and (bi... bi + 1) — let's call them si and ti — and multiply the results.
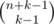 and is explained here.
and is explained here.
For calculating the number of shuffles we possibly can iterate through all of them using recursion since the problem statement says total number won't exceed 263.
But in fact, if we look deeper it's exactly the number of compositions of |si| as (|ti| + 1) non-negative integer terms. You can write it down and see by yourself. The direct formula is