



Добро пожаловать на 2014-2015 CT S02E07: Codeforces Trainings Season 2 Episode 7. Продолжительность тренировки — 5 часов. Тренировка открыта как для команд, так и для индивидуальных участников. После ее окончания вы можете дорешивать задачи тренировки или поучаствовать в ней виртуально, если не смогли принять участие одновременно со всеми. Пожалуйста, участвуйте в тренировке честно.
Так как это тренировка, то возможно набор задач будет расширен, если для значительного количества участников он окажется простым.
Условия задач будут на английском языке, ведь мы же готовимся к ACM-ICPC!
Удачи!







don't know why, but I am not able to submit. Every time I submit, I am redirected to the page again.
Answered you in usertalks.
Thanks for the reply sir.Mistake was from my side.The issue is resolved now.
DELETED
Code-duplication meme XD
Will you publish an editorial after the training session is over?
Yes.
Edutorial in Polish =)
Guess I'll just have to learn Polish, then. :)
Please don't look at my previous comment . I copy pasted the whole editorial from the pdf here so that you can use google translate but it looks very bad .
That's why there's the "preview" feature.
My codes: A C E F H I J K
I looked at ur code, ur code is amazing!
In problem "Laundry" , what this statement actually meant :- clothes belonging to different persons may not be fastened with clothespins of the same color ??
Does this mean that we cannot assign same color clothespins to different persons ??
Yes, we cannot.
Thanks.
the problem statement was not clear :(
Sounds clear enough to me.
I guess, "may not be" and "can not be" are two different things.
Not really. The differences are very subtle, maybe I'd use "can not" as "it's impossible" and "may not" as "it's not allowed" — but it all amounts to the same thing here.
But what else can it mean in a non-probabilistic problem statement? You either can use different colours for different people, or can't, and in the first case, that sentence makes no sense, so it's the second one.
it seems codeforces is improving my english too.
Xellos thanks for the reply :)
Xellos is too mainstream, if you know what I mean.
Can you explain your E? I get that it's an sparse segment tree, but I don't get how the updates are done. my team thought it was just like this problem, so we went for an sqrt-decomposition approach, but it TLE'd (test case 4 ran for ~20min in my computer, lol).
PS: for a team that has no other help around but the internet, you are one of the most helpful guys for our preparation to ICPC Regionals, so thanks a lot for your contribution here!
It's not a sparse segment tree (the one where you don't have some subtrees in memory at all), but there are some similarities.
In each node, you count the number of intervals that cover it fully; that number can be "normalized" so that if 2 sons of a node are both fully covered by two intervals, we can view it as the whole node being covered by one, and split one interval into its sons similarly (lazy propagation).
You also need to know how many leaves in a subtree aren't covered by anything. If there's an interval covering the whole thing, it's 0; otherwise, it's the sum of its sons (or 1 for leaves).
The rest is just drilling it into standard segment tree implementation.
The whole contest has some crazy limits (O(N4 / 3)? ok, let's set N = 3000000). I'm not surprised that sqrt-decomposition fails.
"The whole contest has some crazy limits (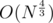 ? ok, let's set N = 3000000)." — fact that you didn't solve it in a better complexity doesn't mean that there is no better solution -_-... In fact J could be solved in
? ok, let's set N = 3000000)." — fact that you didn't solve it in a better complexity doesn't mean that there is no better solution -_-... In fact J could be solved in 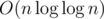 complexity (and this
complexity (and this 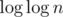 simply pops out of Erathostenes sieve)
simply pops out of Erathostenes sieve)
Okay, I didn't see that one :D
But the limits are still tighter than in most contests. In this case, my point is that it completely nukes sqrt-solutions of E.
http://petr-mitrichev.blogspot.com/2013/05/ural-championship-day-1-russia-vs-china.html — "13:23 — This problem shows the “Polish flavor” of the problem statements today (they were prepared by Jakub Pachocki, also known as meret): whenever a nlogn solution is expected, n will be at least a million. If there was a linear-time solution in mind, n would be at least 10 million :) In Russian contests, nlogn is usually tested via n equal to about hundred thousand." :P
But wouldn't that result in O(N * log(N)) per query in worst case? For example, in a testcase where L = 1 and 500000 evenly spaced gophers/cd players, so that the segment tree's leafs would be like this: "01010101010...."
Of course it's , what else could it be?
, what else could it be?
per query? I was expecting an O(logN) per query w/ segtree+lazy update
Shitty reading, my fault. Notice that I don't have a get() function in my segtree at all; how do I get the result, then?
(Hint: read the 3rd paragraph of my explanation again.)
hmm, now I got it, thanks!
Hello, I want to Know can the Problem e be solved by Segment Tree?
If you actually read the comments above, you'd see that my solution is a segment tree.
"It is possible that the problems will be too easy for some participants, it is possible that we will add some problems." — lol. Indeed one team participating in that training did 11 problems (though ended 5 minutes before the end) and one ghost team also got all of them, but AMPPZs (at least those organized by UW, I don't know problems from others) contain really challenging and interesting problems :). I hope you enjoyed problems :).
I actually solved some of them in an older, Slovak training. I even remembered how I solved some of them, although my solutions this time were often a lot simpler idea-wise...
Did anyone solved E using sqrt-decomposition? We've tried it, but got TLE on test case 4 ):
Is there anyone who solved G with the idea of using string matching on graph? All the solutions I have checked so far are based on hash.
When I solved this problem a long time ago, I used it. It took me one night (it was quite long and I had trouble debugging it)...