


Idea: wakanda-forever Preparation: wakanda-forever
Let's say we have a sequence of numbers with an average equal to $$$k$$$.
Adding a number greater than $$$k$$$ increases the average, while adding a smaller one decreases it.
Therefore, the maximum average subarray is formed by taking the maximum element, since including anything smaller would only lower the average.
Hence, the final answer is the maximum element of the given array.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
vector<int> a(n);
for(int i = 0; i < n; i++) cin >> a[i];
cout << *max_element(a.begin(), a.end()) << endl;
}
return 0;
}
Idea: wakanda-forever Preparation: tridipta2806
We need to find a non-decreasing subsequence $$$p$$$ such that, after removing its characters from the string $$$s$$$, the remaining string $$$x$$$ becomes a palindrome.
Observe that if we choose $$$p$$$ to consist of all the $$$0$$$'s in $$$s$$$, then $$$x$$$ will contain only $$$1$$$'s, which always forms a palindrome. Similarly, if we take $$$p$$$ as all the $$$1$$$'s, then $$$x$$$ will contain only $$$0$$$'s, which is also a palindrome.
In both cases, $$$p$$$ is clearly a non-decreasing subsequence (since all its elements are equal).
Therefore, a valid solution always exists — we can simply output the indices of either all $$$0$$$'s or all $$$1$$$'s in the string.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
string s;
cin >> s;
vector<int> pos;
for(int i = 0; i < n; i++) if(s[i] == '0') pos.push_back(i + 1);
cout << (int)pos.size() << '\n';
for(auto& z : pos) cout << z << ' ';
cout << '\n';
}
return 0;
}
Idea: wakanda-forever Preparation: wakanda-forever
We are allowed to choose any $$$x$$$ such that $$$0 \le x \le a$$$ and set $$$a := a \oplus x$$$. Our goal is to make $$$a$$$ equal to $$$b$$$.
Let's think of the binary representation of $$$a$$$. Consider the highest set bit (most significant bit) of $$$a$$$ and let's assume its position is $$$\operatorname{msb}(a)$$$.
At each operation, we are choosing $$$x \le a$$$, which implies that $$$\operatorname{msb}(x) \le \operatorname{msb}(a)$$$ (otherwise, we have $$$x \gt a$$$).
Now, we can surely say that $$$\operatorname{msb}(a \oplus x) \le \operatorname{msb}(a)$$$.
Thus, by performing the given operation, $$$\operatorname{msb}(a)$$$ will never increase. So, if $$$\operatorname{msb}(b) \gt \operatorname{msb}(a)$$$, the answer is $$$-1$$$.
Otherwise, we can always transform $$$a$$$ into $$$b$$$ in a constructive manner.
First, we set all bits below $$$\operatorname{msb}(a)$$$ one by one to ensure that every required bit can be manipulated. Then, for each bit that is $$$0$$$ in $$$b$$$, we unset it using an appropriate XOR operation.
By following this process, we can reach $$$b$$$ from $$$a$$$ in less than $$$60$$$ operations.
Time Complexity: $$$O(\log_2(a))$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int a, b;
cin >> a >> b;
if(__builtin_clz(a) > __builtin_clz(b)) cout << "-1\n";
else if(a == b) cout << "0\n";
else{
vector<int> val;
for(int i = 0; i < 31; i++){
int x = (1 << i);
if(x <= a && (a & x) == 0) a += x, val.push_back(x);
}
for(int i = 0; i < 31; i++){
int x = (1 << i);
if(x <= a && (b & x) == 0) val.push_back(x);
}
cout << val.size() << '\n';
for(auto z : val) cout << z << ' ';
cout << '\n';
}
}
}
Idea: wakanda-forever Preparation: wakanda-forever
We denote
Now, let us try to find $$$l$$$ first.
Consider two additional arrays representing the prefix sums of the arrays $$$p$$$ and $$$a$$$, defined as follows:
Analysing these, we can say that $$$\text{pref_sum_a}[i] \ge \text{pref_sum_p}[i]$$$ for all $$$i$$$. In fact, the inequality holds true only when $$$l \le i \le n$$$.
Thus, we can binary search for $$$l$$$.
At each stage, we make $$$2$$$ queries $$$\operatorname{query}(1, 1, \text{mid})$$$ and $$$\operatorname{query}(2, 1, \text{mid})$$$, and by comparing these, we can adjust $$$\text{left}$$$ and $$$\text{right}$$$ in binary search.
We can also find $$$r$$$ by querying suffixes in a similar way, but that would take a total of $$$4 \cdot \lceil \log_2(n) \rceil$$$ queries. This exceeds the query limit.
Instead, we can query the whole array once and find $$$r$$$. In other words,
So, after finding $$$l$$$, we can find $$$r$$$ in $$$2$$$ queries. Total queries will be equal to $$$2 \cdot \lceil \log_2(n) \rceil + 2$$$ ($$$ \lt 40$$$).
Time Complexity: $$$O(\log_2(n))$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
ll query(int type, int l, int r){
ll x;
cout << type << ' ' << l << ' ' << r << flush << endl;
cin >> x;
return x;
}
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
ll sum = query(2, 1, n);
sum -= ((n * (n + 1)) / 2);
ll diff = sum - 1;
int l = 1, r = n;
while(l < r){
int md = (l + r) / 2;
ll val1 = query(1, 1, md);
ll val2 = query(2, 1, md);
if(val1 < val2) r = md;
else l = md + 1;
}
cout << "!" << ' ' << l << ' ' << diff + l << flush << endl;
}
}
Idea: wuhudsm Preparation: wakanda-forever
Instead of carefully choosing all $$$k$$$ elements individually, it is sufficient to pick three distinct integers $$$x$$$, $$$y$$$, and $$$z$$$ and repeat them cyclically — that is, append
until we perform $$$k$$$ operations. For $$$n \ge 3$$$, we can always find such $$$x$$$, $$$y$$$, $$$z$$$ that add no extra palindromic subarrays.
Now let's try to find such integers $$$x$$$, $$$y$$$, $$$z$$$. There will be two cases.
Case 1: $$$a$$$ is a permutation of $$${1,2,3, \dots ,n}$$$.
If the array $$$a$$$ is a permutation, we can simply choose the first three elements of $$$a$$$ for the construction. That is, let $$$x = a_1$$$, $$$y = a_2$$$, and $$$z = a_3$$$. Since all elements in a permutation are distinct, these choices guarantee that $$$x$$$, $$$y$$$, and $$$z$$$ are distinct and add no extra palindromic subarrays.
Case 2: $$$a$$$ is not a permutation of $$${1,2,3, \dots ,n}$$$.
If the array $$$a$$$ is not a permutation, we can choose $$$x$$$ to be any integer that does not appear in $$$a$$$. Let $$$z$$$ be the last element of the array, and choose $$$y$$$ as any integer different from both $$$x$$$ and $$$z$$$. These three numbers will always be distinct and add no extra palindromic subarrays.
Time Complexity: $$$O(n + k)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int n, k;
cin >> n >> k;
vector<int> a(n), cnt(n + 1, 0);
for(int i = 0; i < n; i++) cin >> a[i], cnt[a[i]]++;
int x = -1;
for(int i = 1; i <= n; i++) if(cnt[i] == 0){
x = i;
break;
}
if(x == -1){
for(int i = 0; i < k; i++) cout << a[n - 3 + (i % 3)] << ' ';
cout << '\n';
}
else{
int y = -1;
for(int i = 1; i <= n; i++) if(i != x && i != a[n - 1]){
y = i;
break;
}
vector<int> v = {x, y, a[n - 1]};
for(int i = 0; i < k; i++) cout << v[i % 3] << ' ';
cout << '\n';
}
}
}
Idea: frostcat, wuhudsm, wakanda-forever Preparation: wakanda-forever
Note that if $$$[0,2,1]$$$ is a subsequence of permutation $$$p$$$, any interval that includes $$$0$$$ and $$$1$$$ must also include $$$2$$$. This implies that $$$\operatorname{mex}$$$ of any interval will not be equal to $$$2$$$. So, $$$2 \notin M$$$. Hence, $$$\operatorname{mex}(M) \le 2$$$.
Thus, we can always ensure that $$$\operatorname{mex}(M) \le 2$$$. Now, we only need to check when $$$\operatorname{mex}(M) = 0$$$ and $$$\operatorname{mex}(M) = 1$$$ are possible.
For $$$\operatorname{mex}(M)$$$ to be equal to $$$0$$$, $$$\operatorname{mex}$$$ of every interval must be positive. So, every interval must include $$$0$$$. This is possible only when all intervals intersect at a common point — that is, there exists at least one point that lies within every interval. Then we place $$$0$$$ at some common point and fill the remaining permutation.
Otherwise, for $$$\operatorname{mex}(M)$$$ to be equal to $$$1$$$, $$$\operatorname{mex}$$$ of each interval must not be equal to $$$1$$$. To ensure this, we have to place $$$0$$$ and $$$1$$$ in such a way that if an interval includes $$$0$$$, it must also include $$$1$$$. This is possible if there exists a point that is not simultaneously the starting point of one interval and the ending point of another. In other words, we should be able to find a position that does not act as both a left and a right boundary. Then we place $$$0$$$ at such a point and $$$1$$$ adjacent to it.
Else, we place $$$[0,2,1]$$$ as a subsequence first and then build the remaining permutation.
Time Complexity: $$$O(n + m)$$$ per testcase.
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define INF (int)1e18
void Solve()
{
int n, m; cin >> n >> m;
vector <int> l(m), r(m), f(n + 1), st(n + 1, 0), en(n + 1);
for (int i = 0; i < m; i++){
cin >> l[i] >> r[i];
st[l[i]] = 1;
en[r[i]] = 1;
for (int j = l[i]; j <= r[i]; j++){
f[j]++;
}
}
vector <int> ans(n + 1, -1);
auto fill = [&](){
vector <bool> used(n, false);
for (int i = 1; i <= n; i++) if (ans[i] != -1) used[ans[i]] = true;
int p = 0;
for (int i = 1; i <= n; i++){
if (ans[i] == -1){
while (used[p]) p++;
ans[i] = p;
used[p] = true;
}
}
for (int i = 1; i <= n; i++){
cout << ans[i] << " \n"[i == n];
}
};
for (int i = 1; i <= n; i++){
if (f[i] == m){
int ptr = 1;
ans[i] = 0;
fill();
return;
}
}
for (int i = 1; i < n; i++){
if (en[i] == 0){
ans[i] = 0;
ans[i + 1] = 1;
fill();
return;
}
if (st[i + 1] == 0){
ans[i] = 1;
ans[i + 1] = 0;
fill();
return;
}
}
assert(n >= 3);
ans[1] = 0;
ans[2] = 2;
ans[3] = 1;
fill();
}
int32_t main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
int t = 1;
cin >> t;
for(int i = 1; i <= t; i++)
{
Solve();
}
return 0;
}
Idea: wakanda-forever Preparation: wakanda-forever
We have to construct a tree with $$$n$$$ vertices such that $$$S = \sum_{{u, v} \in E} (u \cdot v)$$$ is a perfect square.
Instead of making it any random perfect square, let's try to make $$$S = (f(n))^2$$$ where $$$f(n)$$$ is an integer function of $$$n$$$.
Now, let's check if we can make $$$f(n) = n$$$. For $$$n = 5$$$, we can consider the following tree
where $$$S = 25 = (5)^2$$$.
Now that we know we have a tree $$$T$$$ with $$$n$$$ ($$$=5$$$) vertices having $$$S = n^2$$$. Using this, let's try to make a tree $$$T'$$$ with $$$n + 1$$$ vertices such that $$$S' = (n + 1)^2$$$. Note that $$$S' - S = 2n + 1$$$. So, while constructing $$$T'$$$, we have to add a new vertex $$$(n + 1)$$$ and also adjust this extra sum $$$2n + 1$$$.
We can achieve this in the following manner:
- add an edge between $$$1$$$ and $$$n + 1$$$,
- remove the edge between $$$1$$$ and $$$n$$$,
- add an edge between $$$2$$$ and $$$n$$$.
This analogy can be extended for all $$$n \ge 5$$$. Such trees have the following structure:
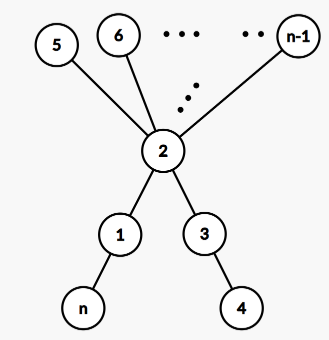
So, we can always make $$$S = n^2$$$ for all $$$n \ge 5$$$. For $$$n \lt 5$$$, we can just print sample outputs.
One can also assume $$$f(n) = n + 1$$$ and construct a similar solution with $$$S = (n + 1)^2$$$.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
if(n == 2){
cout << -1 << '\n';
continue;
}
if(n == 3){
cout << "1 3\n2 3\n";
continue;
}
if(n == 4){
cout << "1 2\n3 1\n4 1\n";
continue;
}
cout << "1 2\n";
cout << "2 3\n";
cout << "3 4\n";
cout << "1 " << n << '\n';
for(int i = 5; i < n; i++) cout << 2 << ' ' << i << '\n';
}
}
Idea: wuhudsm Preparation: wuhudsm

When the value of $$$f$$$ is 1 for $$$[l_i, r_i]$$$, all numbers in $$$[l_i, r_i]$$$ are either $$$\leq x$$$ or $$$\geq x$$$.
We observe that for each interval, we need to divide the intervals into S-intervals (smaller) and B-intervals (bigger). S-intervals can only contain numbers $$$\leq x$$$, and B-intervals can only contain numbers $$$\geq x$$$.
Assuming we have fixed the S-intervals and B-intervals. For each index $$$i$$$, there are 4 types:
- Type 1: $$$i$$$ is covered only by S-intervals;
- Type 2: $$$i$$$ is covered only by B-intervals;
- Type 3: $$$i$$$ is covered by both S-intervals and B-intervals;
- Type 4: $$$i$$$ is covered by neither S-intervals nor B-intervals.
Let $$$cnt_s$$$ be the number of values $$$ \lt x$$$, and $$$cnt_b$$$ be the number of values $$$ \gt x$$$.
When there are no type 4 indices, we only need to check whether:
$$$cnt_s \leq$$$ (total number of type 1 indices)
$$$cnt_b \leq$$$ (total number of type 2 indices)
When type 4 indices exist, we only need to make a slight modification to the condition (this modification is left to the reader).
Consider a simpler case: all intervals are non-overlapping. In this case, the problem reduces to a classic knapsack problem, where each interval becomes an independent item. We consider extending the idea of DP to the original problem.
We find that intervals that are contained within others are useless and can be removed. Then, the intervals can be sorted by their left endpoints. This way, for $$$i \lt j$$$, we can ensure $$$l_i \lt l_j$$$ and $$$r_i \lt r_j$$$. Then, we perform DP based on the order of the intervals.
We define:
$$$dp[i][j][k = 0 \text{ or } 1]$$$: For the first $$$i$$$ intervals, the total number of type 1 indices is $$$j$$$, and the last interval is an S-interval ($$$k = 0$$$) or a B-interval ($$$k = 1$$$), the maximum total number of type 2 indices obtained.
Let $$$inslen[i]$$$ be the length of the intersection between the $$$i$$$-th interval and the $$$(i-1)$$$-th interval.
Transitions:
- $$$dp[i][j][0] = \max(dp[i-1][j - inslen[i]][0], dp[i-1][j - inslen[i]][1] - inslen[i])$$$
- $$$dp[i][j][1] = \max(dp[i-1][j][1] + inslen[i], dp[i-1][j + inslen[i]][1] + inslen[i])$$$
Note: For intervals $$$(i-2)$$$, $$$(i-1)$$$, $$$i$$$, if the type of interval $$$(i-1)$$$ is different from both $$$(i-2)$$$ and $$$i$$$, and $$$r[i-2] \geq l[i]$$$, some overlapping parts may be subtracted repeatedly. However, we find that this does not affect the final answer because it is not better than the answer when all three intervals are of the same type. Here, a common DP idea is applied: if "incorrect" states are recorded but they cannot be optimal, the DP transitions can remain unchanged (a similar idea is used in: https://mirror.codeforces.com/contest/1859/problem/E).
| State 1 | State 2 |
|---|---|
 ) ) |  |
| Some overlapping parts (in the middle) are subtracted repeatedly. | Better because the value range of the middle positions is strictly larger. |
Afterward, answering queries using the DP array is trivial. The time complexity is $$$O(n^2)$$$.
There is another DP approach. Let $$$b[i]$$$ be the smallest $$$j \leq i$$$ such that $$$j$$$ and $$$i$$$ are covered by the same interval. Then, if position $$$i$$$ is filled with a number $$$ \lt x$$$, we can deduce that all numbers in $$$a'[b[i], \ldots, i]$$$ must be $$$ \lt x$$$, and so on. This way, we can write a DP that transitions position by position, without pre-processing each interval.
For details, refer to Dominater069 's code.
#include <map>
#include <set>
#include <cmath>
#include <ctime>
#include <queue>
#include <stack>
#include <cstdio>
#include <cstdlib>
#include <vector>
#include <cstring>
#include <algorithm>
#include <iostream>
#include <bitset>
#include <unordered_map>
#define fastio ios_base::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef double db;
typedef long long ll;
typedef unsigned long long ull;
const int N=3010;
const int LOGN=28;
const ll TMD=0;
const ll INF=100000000;
int T,n,m;
int a[N],cnt[N],mxr[N];
int dp[N][N][2];
/*
* stuff you should look for
* [Before Submission]
* array bounds, initialization, int overflow, special cases (like n=1), typo
* [Still WA]
* check typo carefully
* casework mistake
* special bug
* stress test
*/
//--------------------------------------------------------------------------
struct seg
{
int l,r;
seg() {}
seg(int l,int r):l(l),r(r){}
int len()
{
return r-l+1;
}
};
seg getins(seg x,seg y)
{
if(x.l>y.l) swap(x,y);
if(x.r<y.l) return seg(INF,INF);
if(x.r<y.r) return seg(y.l,x.r);
else return seg(y.l,y.r);
}
//--------------------------------------------------------------------------
void init()
{
cin>>n>>m;
for(int i=0;i<=n;i++)
mxr[i]=0;
for(int i=1;i<=n;i++)
cin>>a[i];
for(int i=1;i<=m;i++)
{
int l,r;
cin>>l>>r;
mxr[l]=max(mxr[l],r);
}
for(int i=0;i<=n+4;i++)
for(int j=0;j<=n+4;j++)
dp[i][j][0]=dp[i][j][1]=-INF;
}
void solve()
{
int sz,cfree=0;
vector<int> tag(n+4);
vector<seg> vs;
for(int i=1;i<=n;i++)
{
if(!mxr[i]) continue;
if(vs.empty()||vs.back().r<mxr[i])
vs.push_back(seg(i,mxr[i]));
}
sz=vs.size();
dp[1][0][0]=vs[0].len();
dp[1][vs[0].len()][1]=0;
for(int i=2;i<=sz;i++)
{
seg cur=vs[i-1],ins=getins(vs[i-2],vs[i-1]);
int len_ins=(ins.l==INF?0:ins.len());
for(int j=0;j<=n;j++)
{
dp[i][j][0]=max(dp[i][j][0],dp[i-1][j][0]+cur.len()-len_ins);
if(j+len_ins<=n)
dp[i][j][0]=max(dp[i][j][0],dp[i-1][j+len_ins][1]+cur.len()-len_ins);
if(j-(cur.len()-len_ins)>=0)
{
dp[i][j][1]=max(dp[i][j][1],dp[i-1][j-(cur.len()-len_ins)][1]);
dp[i][j][1]=max(dp[i][j][1],dp[i-1][j-(cur.len()-len_ins)][0]-len_ins);
}
}
}
for(int i=0;i<vs.size();i++)
for(int j=vs[i].l;j<=vs[i].r;j++)
tag[j]=1;
for(int i=1;i<=n;i++)
if(!tag[i]) cfree++;
for(int i=1;i<=n;i++)
{
int s=0,b=0;
for(int j=1;j<=n;j++)
{
if(a[j]<i) s++;
else if(a[j]>i) b++;
}
int flg=0;
for(int j=0;j<=n;j++)
{
int need1=max(0,s-j),need2=max(0,b-max(dp[sz][j][0],dp[sz][j][1]));
flg|=(cfree>=need1+need2);
}
cout<<flg;
}
cout<<"\n";
}
//-------------------------------------------------------
void gen_data()
{
srand(time(NULL));
}
int bruteforce()
{
return 0;
}
//-------------------------------------------------------
int main()
{
fastio;
cin>>T;
while(T--)
{
init();
solve();
/*
//Stress Test
gen_data();
auto ans1=solve(),ans2=bruteforce();
if(ans1==ans2) printf("OK!\n");
else
{
//Output Data
}
*/
}
return 0;
}
#include <bits/stdc++.h>
using namespace std;
#define INF (int)1e9
mt19937_64 RNG(chrono::steady_clock::now().time_since_epoch().count());
void Solve()
{
// x <= min or x >= max
// min < x < max is bad
// => in range if both smaller and larger exists, cooked
// just spam smaller at one end, and larger at other end?
// i <-> j if there exists interval covering both
// if i <-> j, cannot have diff type on i and j
// dp[i][number of 0s] = max number of 1s, but also need to know what is the last 0 / 1 position
// we can extend last character always
// we can extend other character only after some gap
// prefmax?
int n, m; cin >> n >> m;
vector <int> a(n + 1), f(n + 1);
for (int i = 1; i <= n; i++){
cin >> a[i];
f[a[i]]++;
}
vector <int> b(n + 1), c(n + 1);
for (int i = 1; i <= n; i++){
b[i] = c[i] = i;
}
for (int i = 1; i <= m; i++){
int l, r; cin >> l >> r;
for (int j = l; j <= r; j++){
b[j] = min(b[j], l);
c[j] = max(c[j], r);
}
}
// vector dp(n + 1, vector(n + 1, vector <int>(2, -INF)));
// vector pref(n + 1, vector(n + 1, vector <int>(2, -INF)));
int dp[n + 1][n + 1][2];
int pref[n + 1][n + 1][2];
for (int i = 0; i <= n; i++){
for (int j = 0; j <= n; j++){
for (int k = 0; k < 2; k++){
dp[i][j][k] = -INF;
pref[i][j][k] = -INF;
}
}
}
dp[0][0][0] = dp[0][0][1] = 0;
pref[0][0][0] = pref[0][0][1] = 0;
for (int i = 1; i <= n; i++){
for (int x = 0; x <= n; x++){
for (int y = 0; y < 2; y++){
for (int z = 0; z < 2; z++){
if (y == z){
int px = x - (y == 0);
if (px >= 0){
dp[i][x][y] = max(dp[i][x][y], pref[i - 1][px][z] + (y == 1));
}
} else {
int px = x - (y == 0);
int lim = b[i] - 1;
if (px >= 0){
dp[i][x][y] = max(dp[i][x][y], pref[lim][px][z] + (y == 1));
}
}
}
pref[i][x][y] = max(pref[i - 1][x][y], dp[i][x][y]);
}
}
}
for (int i = 1; i <= n; i++){
int lower = 0;
int upper = 0;
for (int j = 1; j < i; j++) lower += f[j];
for (int j = i + 1; j <= n; j++) upper += f[j];
if (pref[n][lower][0] >= upper || pref[n][lower][1] >= upper){
cout << "1";
} else {
cout << "0";
}
}
cout << "\n";
}
int32_t main()
{
auto begin = std::chrono::high_resolution_clock::now();
ios_base::sync_with_stdio(0);
cin.tie(0);
int t = 1;
// freopen("in", "r", stdin);
// freopen("out", "w", stdout);
cin >> t;
for(int i = 1; i <= t; i++)
{
//cout << "Case #" << i << ": ";
Solve();
}
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::nanoseconds>(end - begin);
cerr << "Time measured: " << elapsed.count() * 1e-9 << " seconds.\n";
return 0;
}






Auto comment: topic has been updated by wakanda-forever (previous revision, new revision, compare).
As a participant, I liked the contest.
Thanks.
this div3 is so tricky
Fast Editorial! could have solved 'E' but couldn't know its failing tc :(
Fast Tutorial!!!!!
Nice Problem Set
Thanks for problem F.
Please provide editorial of H.
will be added shortly
Then please give some hint. I think the solution should be to iterate on each $$$x$$$ abd somehow calculate the answer in $$$O(max(n, m) * log(max(n, m)))$$$ but unable to come up with a solution.
The editorial of H has been added.
I feel like my code is correct. Can anybody help me to point out why it is wrong? ~~~~~ // this is code
include <bits/stdc++.h>
using namespace std;
int t, n; int a,b;
int main(int argc, char const *argv[]) { ios_base::sync_with_stdio(false); cin.tie(0); cin >> t; for(int q=0;q<t;++q){ cin>>a>>b; if(b==0){ cout<<1<<"\n"<<"0\n"; continue; } if(a<b) { cout<<"-1\n"; continue; } if(a==b){ cout<<"0\n"; continue; } int kq=a^b; if(kq<=a) cout<<1<<"\n"<<kq<<"\n"; else{ int k1=kq^a; int k2=k1^b; cout<<2<<"\n"<<b<<" "<<a<<"\n"; } } return 0; } ~~~~~
format your message please. it is not readable.
JUST ADD ONE CONDITION IN : if(a<b && (a^b) > a) then its impossible (-1).
Tell us the problem you want us to help you with.pigk
D was really fun! I was so close to solving E but couldn’t find the bug. Anyway, it was a good problem set.
can E be solved using rolling hash to get dp[i] which returns true if [i..n] is palindromic?
yeah i think it can be solved using rolling hash. my idea was similar to it but i used manachar algorithm to check pailindromic suffixes my code:- https://mirror.codeforces.com/contest/2162/submission/344333062
what's wrong in my solution
Well for starters, your code simply removes all 0's when the problem states to find any non-decreasing subsequence whose removal leaves a palindrome. Also, your code never even checks to see if the removal leaves a palindrome.
Empty string is palindrome and a string consisting of all ones is also palindrome
That is my bad, I mis-read the problem. The code should get accepted, unsure on where the issue is then.
Bro use "super complicated" code then got AC ;)) (cause your expert)
i just submitted you code to the system.this code is correct.
EFG are such cool problems. Def one of the best div-3 this year for me
Agreed, this div3 certainly's got high quality problems. I think it's a little bit close to Edu div2 in fact. Really cool tasks.
Any intuition behind problem E solution?
my intuition was, i cannot do anything about palindromes occurring within the vector, what i can do is create a boundary beyond which no palindrome is possible, for that i need asymmetry at the border, that asymmetry can be constructed following approach in edu
If you have three missing numbers you can add them like a,b,c,a,b,c then handle when you have only 0 missing, only 1 missing, and 2 missing
If $$$a_i \neq a_{i-1} \text{ && } a_i \neq a_{i-2}$$$ for all i, then the array is guaranteed to not contains palindromes of length > 1. Proof: palindromes 2 and 3 do not exist by condition. Others palindromes contain palindromes 2 or 3.
my intuition for E was trying not to add number that can create palindrome of length 2 or length 3 (when we append a[x], try to make a[x] != a[x — 1] and a[x] != a[x — 2]). The code was:
int v1 = a[x — 1], v2 = a[x — 2];
int v3 = v1;
while (v3 == v1 || v3 == v2) v3 = v3 % n + 1;
But then i realized that my solution failed to this testcase : 4 1 4 3 2 3 (my code will output 4, which will make a palindrome of length 5). So to avoid this i will try to add number that hasn't appear in original array, then follow the above algorithm.
Auto comment: topic has been updated by wakanda-forever (previous revision, new revision, compare).
Thanks for the quick editorial! As a participant, I found problem C to be a nice bit manipulation challenge
BRUH I GOT THE OBSERVATION IN E ABOUT REPEATING 3 NUMBERS BUT IDK HOW TO FIND THEM :((
I literally took 1hr to find them lol
The sample has constructions for $$$n \leq 4$$$, so assume $$$n \gt 4$$$. Start by constructing a star where all nodes are connected to node $$$1$$$. This tree has a value of $$$S=2+3+...+n$$$. Let $$$x$$$ be the smallest number such that $$$x^2 \geq S$$$ and $$$d=x^2-S$$$. If $$$d \gt 2$$$, we can detach some nodes from $$$1$$$ and connect them to a greater node to increase the tree's value to $$$x^2$$$. For $$$x=1,2$$$, we can instead form a sum of $$$(x+1)^2$$$.
Seems we can't construct an answer for $$$n = 5$$$ with this method.
$$$S = 2 + 3 + 4 + 5 = 14$$$. $$$d = 16 - 14 = 2$$$.
I assume you mean $$$d \gt 2$$$ by "If $$$x \gt 2$$$". Since $$$d = 2$$$, we fall back to $$$d = 25 - 14 = 11$$$. But $$${3, 4, 5}$$$ can't add up to 11.
You don't have to attach them to $$$2$$$, like for $$$n=5$$$ you attach $$$3$$$ to $$$2$$$ and then $$$4$$$ to $$$3$$$, which results in
1 2
1 5
2 3
3 4
but how would you find this construction of where to add which node
I think comment below explains it well
It's a good solution indeed. Hopefully not just for myself, the crucial part feels a little vague.
My attempt to explain it more elaborately.
$$$S = 2 + 3 + 4 + \cdots + n = \frac{n(n+1)}{2} - 1$$$ .
The first inequality $$$n \gt x $$$ can be proven via proof by contradiction and, showing it's only possible for $$$n \lt 4$$$. Lets say $$$x=n$$$, which means $$$x^2 \geq S $$$ and $$$(x-1)^2 \lt S$$$.
I can break $$$n (n-1)$$$ into parts since it's an even integer; I need to be careful when dealing with integers.
Since $$$n \gt 1$$$, we can cancel on both sides, which yields the result that $$$n$$$ must be less than $$$4$$$ and leads to a contradiction. The upper bound is quite loose. For the trivial case where $$$x^2=S$$$ (as with $$$n=4$$$), we've already found our answer. The only case remaining is $$$n \geq 5$$$, and we now just need to prove that $$$x^2 - S \gt 0$$$.
We will use two properties of the ceiling function:
1. If $$$x_1 \leq x_2$$$, then $$$\lceil x_1 \rceil \leq \lceil x_2 \rceil$$$.
2. $$$\lceil x_1 \cdot x_2 \rceil \leq \lceil x_1 \rceil \cdot \lceil x_2 \rceil$$$.
Using the first ceiling property, we can say that the first ceiling term is at least as big as the second term. Therefore, we can see that the LHS is at least $$$1$$$ integer larger.
It feels like I have overcomplicated things very much. Sorry.
Corollary: Taking $$$d = x^2 - S$$$, then $$$2 \sqrt S \gt d$$$ must be true.
If $$$x^2 \geq S$$$, then $$$(x-1)^2 \lt S$$$. This implies that $$$x \leq \lceil \sqrt S \rceil + 1$$$.
From the Ceiling property, we can say the remaining terms are greater than 0. Therefore, $$$d \lt 2 \lceil \sqrt S \rceil$$$. This is approximately $$$d \approx \sqrt 2 n$$$. In practice, its $$$d/n$$$ ratio is $$$\approx 1.45455$$$.
Now, our initial tree is rooted at $$$1$$$, and all other nodes are directly connected to $$$1$$$ as leaves. Now I want to rearrange the leaves such that my sum is increased by $$$d(=x^2-S)$$$.
Let's say we pluck the leaf $$$v$$$ and attach it to $$$u$$$. Then our new sum, $$$S_{\text{new}}$$$, is calculated as:
If the required increment satisfies $d \leq n$, we can choose the parent $$$u=2$$$ and the leaf $$$v=d$$$. Our job will be done in a single step. If $$$d \gt n$$$, we need a multi-step approach. We claim that we can always find $$$v_1$$$ and $$$v_2$$$ such that $$$n \geq v_1, v_2 \gt 2$$$ and their sum is $$$d$$$.
One possible method for partitioning $$$d$$$ into two parts (given $$$d \gt n$$$):
If $$$d$$$ is odd: Choose $$$v_1 = \lfloor d/2 \rfloor$$$ and $$$v_2 = \lfloor d/2 \rfloor + 1$$$.
If $$$d$$$ is even: Choose $$$v_1 = d/2 - 1$$$ and $$$v_2 = d/2 + 1$$$.
For $$$n \geq 5$$$, these vertices $$$v_1$$$ and $$$v_2$$$ will be $$$\geq 3$$$ in both cases.
But if $$$d=1$$$ or $$$d=2$$$, we need to be a little careful.
Case 1: If $$$d=2$$$, then $$$2 = x^2 - S$$$. We can rewrite this as $$$2 + 2x + 1 = (x+1)^2 - S $$$. Let's break the LHS into 2 parts, $$$3 + 2x$$$. We need to achieve a $$$2x$$$ and a $$$3$$$ increment. We can get that easily in 2 steps: plucking $$$x$$$ and attaching it to $$$3$$$ (which will give a $$$2x$$$ increment), and then joining $$$3$$$ to $$$2$$$ (which will give a $$$3$$$ increment).
Case 2: If $$$d=1$$$, then $$$1 + 2x + 1 = (x+1)^2 - S$$$. Let's make the LHS into $$$2(x+1)$$$. Then we can always pluck $$$x+1$$$ and attach it to $$$3$$$, giving us a $$$2x+2$$$ increment. This is a legal move since $$$x+1 \leq n$$$ .
Submission link 344535551
Edit1:
Mistake: In calculating $$$x^2$$$ and in using the Ceiling property $$$\lceil x_1 \cdot x_2 \rceil \leq \lceil x_1 \rceil \cdot \lceil x_2 \rceil $$$, I mistakenly took the lower bound of this product when determining the upper bound. That was a stupid mistake.
The following edits are made:
In the Proof section, it is acceptable to take the lower bound when proving that $$$x$$$ indeed follows this inequality: $$$ \lceil (n+1)/ \sqrt 2 \rceil \geq x $$$.
In the Corollary Proof, a much easier and tighter bound to prove is $$$2 \sqrt S \gt d$$$.
Handling the case when $$$d \gt 2$$$: Since $$$d$$$ is the required increment, we can always find $$$v_1$$$ and $$$v_2$$$ such that $$$n \geq v_1,v_2 \gt 2$$$ and their sum is $$$d$$$.
I think d<=n is not correct.
For n = 7,
The value of S is 27 and x^2 is 36
So d = 9 , which is greater than 7 ...
It's not, $$$d \leq 2n$$$
I guess my O(n^3) solution for H that leaves less than 1MB memory free was not the intended one
I'm getting wrong output / not working properly. Can someone please help me find the issue in my code?
Here’s my code:
Please tell me what’s wrong or how to fix it. Thanks!
my solution for problem c
I thought about it too.
could you please explain for me it from math perspectives?
why not use only n^m?
we cant directly use n^m because for cases where the MSB of m is less than n, n^m can be greater than n which will violate the codition
Example n = 1000, m = 0001
then xor will be 1001
for this reason we can do it by first taking it to the largest possible value that is 1111 then going to 0001'
in this way we will always be able to do it in 2 steps
See in this problem as they have explained in the editorial it is not possible to convert a to b if b has a bigger MSB than a, otherwise it is always solvable.
What is being done in this solution is that first we are finding the biggest number x that is possible which will be having all ones till the MSB of a. To find that we are first just finding the first power of two which is bigger than a and then when we subtract one from it we will turn the only bit of that power of two to zero and all other smaller bits to one.
For example:
Lets say a is 1010
And b is 0100
Now as b is smaller than 1111 it is clearly reachable
So with the while loop we get 10000 which is the first square bigger than 1010
Then we subtract one getting 1111.
We did all this because we want to find a number x1 which on doing xor with 1010 will give us 1111 To find that we can now just simply xor 1010 with 1111 which will give us 0101 as the first number that we want to print.
It is true because for three numbers x,y,z if x xor y equals z then you can interchange there positions in any way and it will always be true.
So instead of doing a xor x1 to get 1111
We did a xor 1111 to get x1
Now from 1111 we have to get to 0100
So essentially 1111 xor x2 equals 0100
This can similarly also be done as 1111 xor 0100 to get x2.
So x2 will be 1011
And in this way x1 and x2 will be our solution.
Hope this helped.
How is checker implemented for E
click
I'm getting wrong output / not working properly. Can someone please help me find the issue in my code?
Here’s my code:
Please tell me what’s wrong or how to fix it. Thanks!
In problem B, a solution always exists, then what is the point of:
"If no such subsequence exists, output −1"
to fk u over
lol
interactive D and construction EFG, definitely top5 scariest div3 OAT
For 2162G - Beautiful Tree I had a different construction, which works for $$$n \gt 5$$$. For smaller $$$n$$$ you can just brute force solutions by trying all trees, or hardcoding the solutions (the first four cases are already given in the sample input).
The minimum value tree has all vertices $$$v \gt 2$$$ connected to vertex 1, with a sum $$$s = 2 + 3 + 4 + .. + n = n(n + 1)/2 - 1$$$
When $$$s$$$ happens to be square, you are done. Otherwise, let $$$s'$$$ be the smallest square greater than $$$s$$$. We need to increase the value of the tree by $$$x = s' - s$$$. It can be shown that $$$x \lt 2n$$$.
To increase the value of the tree, we can take a vertex $$$v$$$ ($$$2 \lt v ≤ n$$$) and change its parent from 1 to 2 to increase the sum by exactly $$$v$$$.
So when $$$2 \lt x ≤ n$$$ we can simply reparent vertex $$$x$$$. If $$$n \lt x \lt 2n$$$ we need to reparent a pair of elements that sum to $$$x$$$, subject to the constraints the they must be different and both are between $$$3$$$ and $$$n$$$. A simple solution is to pick vertex $$$x/2-1$$$ and $$$x/2+1$$$ if $$$x$$$ is even, or $$$(x-1)/2$$$ and $$$(x+1)/2$$$ if $$$x$$$ is odd.
The only tricky case is when $$$0 \lt x ≤ 2$$$ because the vertices to be moved must be greater than 2. In that case, we simply use the next square after $$$s'$$$ instead; it can be shown that this is still less than $$$2n$$$ away so we still only need to move 2 vertices.
For n=5, s is 14, s' is 16 so x=2, which falls in your last case, so for next s' you will try s'=25, but here x becomes 25-14=11, which is greater than 2*n (10), so that contradicts your explanation for the last case right? Although we can still make 25 using some arrangement.
That's why I wrote $$$n \gt 5$$$ and not $$$n ≥ 5$$$ ;-)
Oops, missed that :(
Randomised solution for G:
Separate 1 from other vertices. Generate a random tree on vertices (I didn't even do some uniform distribution of trees, just generate the parent and then relabel the vertices randomly), and then try to connect 1 to some vertex.
Very nice solution!
To clarify, like implementation-wise, does this mean that you permute 2..n randomly, attach them into a star, then try to attach 1 somewhere?
Also did you prove it or was it intuitively obvious that it would work within TL?
I didn't attach 2..n in a star. I created a random tree where $$$parent_v \lt v$$$ and then relabeled the vertices. As for why it should work within TL I don't really have a proof (and my first implementation barely passed), but the amount we need to add for a number to be a perfect square is up to $$$2n$$$ and we can add up to $$$n$$$, so it seems like we only need a small number of checks
Your solution actually gave me the intuition of how to get a deterministic solution, so thank you for that.
We try to form some tree without 1 and add something from 2 to n using the edge with 1 to get to a perfect square.
If we use a star tree with 2 in the center we get the sum 2*(3+n)(n-2)/2=n+n^2-6. It's greater than n^2 in most cases, so let's try (n+1)^2:
(n+1)^2-n-n^2+6=n+7 > n, so let's try to increase the sum of the star tree by something >= 7, for example by connecting 5 to 4 instead of 2.
Then the sum will increase by 5*4-5*2=10, so we'll need to add n+7-10=n-3. So the construction for n>=5 is:
1 n-3
2 3
2 4
2 i, 6 <= i <= n
4 5
Auto comment: topic has been updated by wuhudsm (previous revision, new revision, compare).
not my dumb ahh used binary search to find l and r and went to sleep
all tasks were pretty cool, like D and E was so fun to solve read F too its pretty nice I will upsolve it
hi everyone, everyone let me ask about problem E. With test case 5, why is the answer I printed 1 4 5 worse than the answer of the question? I tried to count why when I combined the 2 arrays, I saw that both results were the same 10
It's not...
First of all i appreciate the time and efforts made to make this contest, this was very good and easy contest. I am no one to argue for this small mistake. But i want to share something that i face.
In question B, which is now changed, took me more time only because of this test case explanation, i could have accepted this in under 2 min, but took me total 20 min with 2 WA, :(
In the fourth test case, we remove p=010 (indices 3, 4, 6), resulting in x=110011, which is a palindrome. which should be---- In the fourth test case, we remove p=01 (indices 3, 4), resulting in x=110011, which is a palindrome.
it took me so much time that this is a mistake from your side, because i thought above is written non dec , so how could 010 is removed, i was so frustrated.
But overall i am very happy to solve 5 problems , as all were very straight forward to me.
Too hard!
D is rubbish.
Nope,just study bin search.
I know,I have solved it.But I really dislike it.
I got it from 2'nd try,solved same as you. Very nice problem, but harder than usually.
Why?
Second question can also be solve like this right?
I was trying this approach but it failed don't know why please give some advice
I think you missed that p the subsequence does not need to be contiguous.
Will this code for E pass, as the system testing is going on i cannot check this and i didn't want to see the editorial section.
Logic: So the question has asked us to minimize the number of palindromic subarray. So to do that we can just append the maximum element in the array + 1 to the end and then increase this variable by 1 every time so that it will not form any palindromic subarray with the previous ones.
I think the elements have a boundary of
1 <= x <= n.ok thanks.
stupid me!
An easier sol'n to C would be, if highest set bit of B exceeds A, cout -1. else set all the bit of A to 1 using its compliment then converting A to B by A xor compliment of B.
C has another neat solution. If $$$ a \oplus b \le a $$$, we just print $$$ a \oplus b $$$. Else if $$$ b \le a $$$, print $$$ b $$$ then $$$ a $$$. (Otherwise its $$$ -1 $$$).
Same solution I did, it was fun to do this way
I could not implement solution of Beautiful strings due to Skill issue. (TT) I read the problem wrong everytime and interpreted the subsequece requirement to be contiguous. ALWAYS READ THE FINE PRINT THRICE!!
As a contestant, the problems were amazing!
Hi folks,
I tried solving E, but got WA on test 2(pretest 53) — solution
I tried finding out what's wrong, but no luck!
My solution:
If I just keep adding 'x' to the end, then it won't contribute to a new palindrome substring.
x: A number chosen such that it differs from the last two distinct numbers. I just keep track of the last two distinct numbers.
Example:
n=4 k=2
array = 2 2 3 3
last two distinct numbers — 2,3 -> so we can place 1 at the end => 2 2 3 3 1
last two distinct numbers — 1,3 -> so we can place 2 at the end => 2 2 3 3 1 2
Any help will be much appreciated!
For example when n = 4
array = 1 3 2 3
You can only add 4 but not 1, which your algorithm can’t determine.
Thank you very much! Much appreciated!!
For problem C beautiful XOR, we can do the conversion in two steps max, if the msb of b and a are opposite, we can take the safe route and XOR a with a number which will result in all set bits as b excluding msb, and then XOR with log2(a) to set msb of a to zero, further if the msb bits are set, we can directly take the XOR a^b, it'll always be less than a.
Problem statements of A and B looked intimidating but the solutions are very simple.
OMG I'm such an idiot! I just realized we need to minimize palindromic SUBARRAYS, not SUBSEQUENCES!!! I've been struggling with this for a whole day now. Could anyone point me in the right direction? Any suggestions would be greatly appreciated!
For Problem C, I used the relationships a ^ b = c and a ^ c = b. The solution runs in O(1) time per test case.
https://mirror.codeforces.com/contest/2162/submission/344334659
~~~~~~~~~~~~~~~~~~~~~~~~~~
include<bits/stdc++.h>
using namespace std;
int main() { int t; cin >> t;
while (t--) { int a , b; cin >> a >> b; int x = a^b; if(x == 0) cout << 0 << endl; else if(a < b && x > a) cout << -1 << endl; else { if(x<=a) { cout << 1 << endl; cout << x << endl; } else { cout << 2 << endl; cout << b << " " << a << endl; } } } return 0;}
Nice problems!
In fact, this was a very good competition, but I'm not very good at it, I don't understand why the output of index 0 in question B was fine (the first group in input 1 had 0 but there was no output), I don't quite understand, hope someone can help me explain!
The output is: the length of the sequence of indices and the sequence of indices in the next line.
If the length is 0 the sequence is empty, so we don't remove anything, and it's fine because in that case the string was already palindromic, and the empty sequence is considered non-decreasing as stated in the problem.
I understand, but in the solution '010' from the problem, the first and second '0's in the code are placed into the pos array, yet they are not output when printed. I don't see any palindrome checking logic in the code either
I see your confusion. So the samples are there to provide some valid answers, to help you understand the problem, but not necessarily the answers that would be generated by the author's solution, usually when there are multiple possible answers they pick something different to not give additional hints for the solution
Oh I should have realized: this problem only needs a method to make a string a palindrome, not a fixed method (so does this problem have a Special Judge?)
yes
wakanda-forever goddddd
I'm getting wrong output / not working properly. Can someone please help me find the issue in my code?
Here’s my code:
Please tell me what’s wrong or how to fix it. Thanks!
C's solution is overcomplicated, probably because you wanted to keep it concise, B is formable from A in 2 operations max if it is possible
if MSB(B) > MSB(A) then obviously B cannot be formed from A -> -1, if MSB(B) == MSB(A) then we can just compare their bits and get the required x -> 1 operation if MSB(B) < MSB(A) then first we compare all the bits that are right of A's MSB, and in the 2nd operation we XOR the MSB of A as well -> 2 operations, and all of these x's are guaranteed to be less than A.
The solution for problem G is amazing! I don't think I not have came up with that even if I had two more hours. For those who have solved the problem, would you mind sharing a little bit about your mindset while encountering this kind of construction problems? Thank you!
Here was my thought process for G:
After trying some random methods out, we find the iterative 'add-remove-add' method as specified in the official solution. This proves our hypothesis and solves the problem.
Hope this helps!
Thanks a lot!
Randomized solution for G
I learn a lot from F.
W contest, L cheaters
344611157 submission number. for the code of C, am really stuck and not able to understand where my code is going wrong
Basically what i am doing is, if the msb of b > msb of a , then printing -1, if they are same printing , 0, other wise creating a string of the integers, both of equal lenght (appending 0s to b if b is smaller by if statement thing), then the logic i am using pushing the indices where bits are not same into vectors, first the vector v, will store all idx of a that are not equal to b(where b[i] ==0), and the u vector will store all idx of a where they are unequal but here b[i] == 1), the logic behind it would be to xor a with all that power 2 where its bit is 1 but b's bit is not 1, and xor a again with 1 where b's bit is 1 but a's bit is not one, i am getting this error "wrong answer Integer parameter [name=x] equals to 4, violates the range [0, 0] (test case 1)" and no clue why, please help me out, sorry if the explanation might not be clear, im not very good at explaining things.
Just curious, why were the constraints on n, m so low for F? Is it because the complexity of the verifier is higher?
Yeah.
wakanda-forever Can’t we achieve O(n sqrt(n) logn) using Mo’s (maintaining a frequency array and set of numbers not present in current range, shifting l or r should take O(logn), answer in O(1) ) ? And for 10^5 it should be around 5 sec.
Yeah, we can.
In fact, we can do it in $$$O((n + m)\log(n))$$$. See this. And there is no big reason for setting constraints low, maybe to allow visiting all points for each interval, instead of using the difference array trick.
I think the time complexity for solution F is written wrong by mistake. It is written as O(n+m) per testcase but I think it is O(n * m) per testcase.
See the above code it is running for O(m * Interval Size) in the worst case all the interval sizes are n so the effective time complexity becomes O(m * n).
Was wondering why pref max was needed for Dominator's solution of problem H, although we're doing something similar to open/close interval DP. Turns out it isnt
My solution for problem $$$E$$$:
Submission
I wrote an O(1) solution for G
345123116
just using the observation that we can always make the sum of product equal to n^2 and starting from the tree where all are connected to 1. Let diff be the increase in sum required ie. n^2-(n(n+1)/2-1). Now adjust n to a place such that diff comes between n and 2n-1. now it can simply be achieved by one or two place changed. Ive proved that it will always work for n>5.
Actually, it's still O(N) xD
I used the right logic for problem E, but was updating the array (adding at the end) instead of printing directly and printing the whole array at last. This solution passed all the pretests in the contest but showed memory limit exceeded afterwards in the final standing. How to know when the memory limit will get exceed and when it will not? because in this problem I was using O(n) space only, still it gave MLE.
why i always get Idleness limit exceeded.I have used ffulsh for my cout.
wuhudsm Is your implementation correct for this problem? Because it doesn’t print any binary string. Also, I think it’s a bit hard to understand why the second state is better. If I understand correctly, you’re saying:
In the first state, we get
$$$r[2]-l[0]+1-(r[0]-l[1]+1)-(r[1]-l[2]+1)$$$ indices of type 1,
$$$0$$$ indices of type 2, and
$$$(r[0]-l[1]+1)+(r[1]-l[2]+1)$$$ indices of type 3.
In the second state, we get
$$$r[2]-l[0]+1$$$ indices of type 1, and
$$$0$$$ of type 2 and type 3.
Therefore, we can say that it is always optimal to have fewer type 3 indices when we use the same number of indices for type 1 or type 2.
Bruh, I just copied the wrong code. Fixed now.
I think your understand is correct. Because $$$x+y$$$ indices of type 1 is always not worse than $$$x$$$ indices of type 1 and $$$y$$$ indices of type 3.
What's the reasoning for the smaller constraints on F? I wrote an O(n * m) solution for it without thinking of trying to optimize it due to the constraints, but after reading the editorial I'm wondering if this was done on purpose to allow these less optimal solutions to pass.
Hi there, I still could not figure out how to come up with the solution for the D T T
Problem E:
If you will check only last 2 different values then this case might fail. t=1 n=5,k=1 input 3 1 2 2 1
I have a weird solution for problem G: 347103995
I find the minimum x such that $$$S = 1 \cdot 2 + 2 \cdot 3 + $$$ ... $$$ + (n - 1)\cdot n \leq x^2$$$. Then I greedily increase $$$S$$$ until $$$S = x$$$. And somehow it worked xD
I really liked problem F. Thanks!
My dumbass cant think of using binary search in D..I dont know what to do now