


Each problem comes with a challenge — a bonus task somehow related to the problem; you may tackle at the challenges for fun and practice, also feel free to discuss them at the comments. =)
For every option of removing an element we run through the remaining elements and find the maximal difference between adjacent ones; print the smallest found answer. The solution has complexity O(n2). It can be noticed that after removing an element the difficulty either stays the same or becomes equal to the difference between the neighbours of the removed element (whatever is larger); thus, the difficulty for every option of removing an element can be found in O(1), for the total complexity of O(n). Any of these solutions (or even less efficient ones) could pass the tests.
Challenge: suppose we now have to remove exactly k arbitrary elements (but the first and the last elements have to stay in their places). How small the maximal difference between adjacent elements can become? Solve this problem assuming the limitations are as follows: 1 ≤ k ≤ n - 2, n ≤ 105, ai ≤ 109.
We observe that the order of operations is not important: we may first perform all the shifts, and after that all the additions. Note that after n shifts the sequence returns to its original state, therefore it is sufficient to consider only the options with less than n shifts. Also, after 10 times of adding 1 to all digits the sequence does not change; we may consider only options with less than 10 additions. Thus, there are overall 10n reasonable options for performing the operations; for every option perform the operations and find the smallest answer among all the options. As performing the operations for every option and comparing two answers to choose the best takes O(n) operations, this solution performs about 10n2 elementary operations. The multiple of 10 can be get rid of, if we note that after all shifts are made the best choice is to make the first digit equal to zero, and this leaves us but a single option for the number of additions. However, implementing this optimization is not necessary to get accepted.
Challenge: can you solve the problem in  time? in O(n) time?
time? in O(n) time?
496C - Removing Columns/497A - Removing Columns
Let's look at the first column of the table. If its letters are not sorted alphabetically, then in any valid choice of removing some columns it has to be removed. However, if its letters are sorted, then for every valid choice that has this column removed it can be restored back to the table; it is clear that the new choice is valid (that is, the rows of the new table are sorted lexicographically) and the answer (that is, the number of removed columns) has just became smaller.
Consider all columns from left to right. We have already chosen which columns to remove among all the columns to the left of the current one; if leaving the current column in place breaks the lexicographical order of rows, then we have to remove it; otherwise, we may leave it in place to no harm. Arguing in the way of the previous paragraph we can prove that this greedy method yields an optimal (moreover, the only optimal) solution. The complexity is O(n2).
Challenge: compute how many (say, modulo 109 + 7) n × m tables are there for which the answer for this problem is k? The more efficient solution you come up with, the better.
496D - Tennis Game/497B - Tennis Game
Choose some t; now emulate how the match will go, ensure that the record is valid for this t and by the way find the corresponding value of s. Print all valid options for s and t. This solution works in O(n2) time, which is not good enough, but we will try to optimize it.
Suppose the current set if finished and we have processed k serves by now. Let us process the next set as follows: find t-th 1 and t-th 2 after position k. If t-th 1 occurs earlier, then the first player wins the set, and the set concludes right after the t-th 1; the other case is handled symmetrically. If the match is not over yet, and in the rest of the record there are no t ones nor t twos, then the record is clearly invalid. This way, every single set in the record can be processed in  time using binary search, or O(1) time using precomputed arrays of positions for each player.
time using binary search, or O(1) time using precomputed arrays of positions for each player.
Now observe that for any t a match of n serves can not contain more than n / t sets, as each set contains at least t serves. If we sum up the upper limits for the number of sets for each t, we obtain the total upper limit for the number of sets we may need to process: 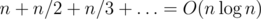 (which is the famous harmonic sum). Using one of the approaches discussed above, one obtains a solution with complexity of
(which is the famous harmonic sum). Using one of the approaches discussed above, one obtains a solution with complexity of  or ; each of these solutions fits the limit nicely.
or ; each of these solutions fits the limit nicely.
Obviously, for every t there is no more than one valid choice for s; however, maybe a bit unexpected, for a given s there may exist more than one valid choice of t. The first test where this takes place is pretest 12. The statement requires that the pairs are printed lexicographically ordered; it is possible to make a mistake here and print the pairs with equal s by descending t (if we fill the array by increasing t and then simply reverse the array).
Challenge: while preparing this problem I discovered that it's quite hard to find a test such that the number of pairs in the answer is large; in the actual tests the maximal number is 128, which is the number of divisors of the number 83160. Can you beat this record? If you have a test with n ≤ 105 that has larger number of pairs in the answer, feel free to brag in the comments; also don't hesitate to share any insights on how one could bound the maximal number analytically.
496E - Distributing Parts /497C - Distributing Parts
Sort all the parts and actors altogether by increasing lower bounds (if equal, actors precede parts); process all the enitities in this order. We maintain a set of actors which have already occured in the order; if we meet an entry for an actor, add it to the set. If we currently process a part, we have to assign it to an actor; from the current set of actors we have to choose one such that his di ≥ bj (the ci ≤ aj constraint is provided by the fact that the i-th actor has occured earlier than the j-th part); if there are no such actors in the set, no answer can be obtained; if there are several actors satisftying this requirement, we should choose one with minimal di (intuitively, he will be less useful in the future). Assign the chosen actor with the current part and decrement his ki; if ki is now zero, the actor can not be used anymore, thus we remove him from the set.
To fit the limits we should implement the set of current actors as some efficient data structure (e.g., an std::set or a treap). The resulting complexity is 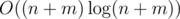 .
.
Challenge: suppose that now there are qj copies of the j-th part (1 ≤ qj ≤ 109), and each copy must be separately assigned with an actor in a valid way. Can you solve this new problem with all the old constraints (as the actual distribution now has too much entries, it is sufficient to check whether an answer exists)?
When a collision happens, a vertex of one polygon lands on a side of the other polygon. Consider a reference system such that the polygon A is not moving. In this system the polygon B preserves its orientation (that is, does not rotate), and each of its vertices moves on some circle. Intersect all the circles for vertices of B with all the sides of A; if any of them intersect, then some vertex of B collides with a side of A. Symmetrically, take a reference system associated with B and check whether some vertex of A collides with a side of B. The constraints for the points' coordinates are small enough for a solution with absolute precision to be possible (using built-in integer types).
Another approach (which is, in fact, basically the same) is such: suppose there is a collision in a reference system associated with A. Then the following equality for vectors holds: x + y = z; here z is a vector that starts at P and ends somewhere on the bound of A, x is a vector that starts at Q and ends somewhere on the bound of B, y is a vector that starts at P and ends somewhere on the circle centered at P that passes through Q. Rewrite the equality as y = z - x; now observe that the set of all possible values of z - x forms the Minkowski sum of A and reflection of B (up to some shift), and the set of all possible values of y is a circle with known parameters. The Minkowski sum can be represented as a union of nm parallelograms, each of which is the Minkowski sum of a pair of sides of different polygons; finally, intersect all parallelograms with the circle.
Both solutions have complexity O(nm). As noted above, it is possible to solve the problem using integer arithemetics (that is, with absolute precision); however, the fact that the points' coordinates are small lets most of the solutions with floating point arithmetics pass. It was tempting to write an approximate numerical solution; we struggled hard not to let such solutions pass, and eventually none of them did. =)
Many participants had troubles with pretest 8. It looks as follows (the left spiral revolves around the left point, and the right spiral revolves around the right point):
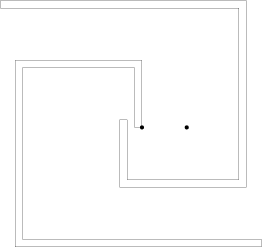
Challenge: suppose we want a solution that uses floating point arithmetics to fail. In order to do that, we want to construct a test such that the polygons don't collide but pass really close to each other. How small a (positive) distance we can achieve, given the same constraints for the number of points and the points' coordinates?
Consider some string; how does one count the number of its distinct subsequences? Let us append symbols to the string consequently and each time count the number of subsequences that were not present before. Let's append a symbol c to a string s; in the string s + c there are as many subsequences that end in c as there were subsequences in s overall. Add all these subsequences to the number of subsequnces of s; now each subsequence is counted once, except for the subsequences that end in c but were already present in s before; these are counted twice. Thus, the total number of subsequences in the new string is twice the total number of subsequences in the old string minus the number of subsequences in the old string which end in c.
This leads us to the following solution: for each symbol c store how many subsequences end in c, denote cntc. Append symbol c; now cntc becomes equal to the sum of all cnt's plus one (for the empty subsequence), and all the other cnt's do not change.
For example, consider the first few symbols of the Thue-Morse sequence:
ε — (0, 0)
0 — ( 0 + 0 + 1 = 1, 0)
01 — (1, 1 + 0 + 1 = 2)
011 — (1, 1 + 2 + 1 = 4)
0110 — ( 1 + 4 + 1 = 6, 4)
...
Let us put the values of cnt in the coordinates of a vector, and also append a coordinate which is always equal to 1. It is now clear that appending a symbol to the string alters the vector as a multiplication by some matrix. Let us assign a matrix for each symbol, and also for each string as a product of matrices for the symbols of the strings in that order.
Now, consider the prefix of the sequence ai of length km. Divide it into k parts of length km - 1; x-th (0-based) of these parts can be obtained from the 0-th one by adding x modulo k to all elements of the part. Let us count the matrices (see above) for the prefixes of length km, and also for all strings that are obtained by adding x to all of the prefixes' elements; denote such matrix Am, x.
It is easy to see that if m > 0, then 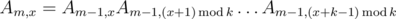 . This formula allows us to count Am, x for all
. This formula allows us to count Am, x for all 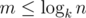 and all x from 0 to k - 1 in
and all x from 0 to k - 1 in 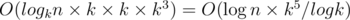 time. Now, upon having all Am, x we can multiply some of them in the right order to obtain the matrix for the prefix of the sequence ai of length n.
time. Now, upon having all Am, x we can multiply some of them in the right order to obtain the matrix for the prefix of the sequence ai of length n.
Unfortunately, this is not quite enough as the solution doesn't fit the time limit yet. Here is one way to speed up sufficiently: note that the product in the formula can be divided as shown: Am - 1, x... Am - 1, k - 1 × Am - 1, 0... Am - 1, x - 1 (if x = 0, take the second part to be empty). Count all the "prefixes" and "suffixes" products of the set Am, x: Pm, x = Am, 0... Am, x - 1, Sm, x = Am, x... Am, k - 1. Now Am, x = Sm - 1, xPm - 1, x. Thus, the computation of Am, x for all x and a given m can be done as computing all Pm - 1, x, Sm - 1, x using O(k) matrix multiplications, and each Am, x is now can be found using one matrix multiplication. Finally, the solution now works in 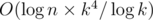 time, which fits the limits by a margin.
time, which fits the limits by a margin.
Challenge: solve the problem for k ≤ 100.






Can you describe how to solve 496B in O(N) or O(nlogn)?
Finding the lexographically smallest rotation of a string using suffix array is O(n).. and one can construct a suffix array in O(n) so it can be done in 10n i.e O(n)
Lyndon decomposition can find smallest rotation of a string in O(n) too, and it's more easy to coding.
Can you give some details? How to construct a suffix array in O(n)? Isn't it O(nlogn)? And how to find the smallest rotation in O(n)?
Same before, I want you to describe more clearly about algorithm to solve in complexity O(n) or O(nlogn). I dont' know how to construct a suffix array :/
For example we can construct suffix automaton on string S + S and then find the smallest substring of length n.
And the complexity is about: O(2*n * 10)?
for problem 496B Secret Combination i got wrong answer on test 11 while it gives me the expected answer on my PC here's the submission 9181590
This is the end of your answer: 00201196. This is the end of right answer: 20201196.
thx i actually solved it. the problem was i thought that the output is the right answer and the answer is the code output :D
Can someone explain Div 2 C in english?
Basically, you have to iterate through collumns from 1 to m, and compare two consecutive elements on the same column. Now, if we have a[row][col]<a[row-1][col], then if we don't have a previous column k in the range [1,col-1] where a[row][k]>a[row-1][k], we must delete the column col and proceed to the next column.
Thanks, what is an efficient way to find that column k though?
First, you can notice than we only need the first k to satisfy this, so if a[row][k]>a[row-1][k] and if we don't delete this column, then we take an array OK[row]=1 , and from now on if a[row][col]<a[row-1][col] it won't matter as long as OK[row] is already 1.
You may translate this in Russian in case you wish that.
P.s. This is my 1st ever so ignore mistakes(not algorithmic ofc)
The problem:: We are given a table of letters and we need to ensure that any row i is NOT lexicographically less than the previous row i-1.
Operation:: We are allowed to delete any column we wish to.
Output
An integer which represents minimum number of columns that will have to be deleted to solve the problem.
STRATEGY=>GREEDY ::
We iterate from 0th column to last , deciding for each column whether it will be removed or included in our final table.
2 variables- prevtaken,prevleft which will store the index of last column which was included,removed respectively.**Both -1 initially.**
answer=number of 0s columns included :P obvio
Say a function f(i)= true if while moving down the ith column the letters are in lexicographic order and FALSE otherwise
Algorithm::start iterating from left
All those columns for which f(i)=>false&&prevtaken=>-1 are to be removed.(why? easy:p )
All those columns for which f(i)=>true are to be included(obvio? easy:P)
Now consider those columns for which f(i)=>false but prevtaken is not -1
As we iterate down this column finding the lexicographic order not satisfied, if for these 2 rows,if the elements in prevtaken column for theese 2 rows are same then we remove this column(why? bcz otherwise the rowwise lexico order that we are interested in would have already been satisfied as prevtaken column is more significant).
Hopeefully you read the hopefully.. xD
P.s. The length is compromised so as to make it comprehensible for even a newbie.:)
http://mirror.codeforces.com/contest/496/submission/9179405
can some one explain 496E distribution of parts in english ?
How to solve the chanllenge of 496A?
Binary search on final difficulty d, then remove as many holds as you can greedily without letting difficulty exceed d.
Answer is smallest d such that you can remove at least k holds.
Um...To check if d can be achieved, can we do this? let i point to the 1st element and j to the 2nd, remove a[j] and inc j by 1 until a[j+1]-a[i] > d, then i=j, j=j+1...
That's it. Can you prove that this always achieves d with the smallest amount of holds left?
When i, j point to the 1st and 2nd hold respectively, we know that replacing j with a hold on its left wont make things better. For if you remove j after that, it is harder to remove next holder because the distance gets larger.And if you dont remove j, the situation becomes the same before replacing. Thank u, ffao, my mind is clear with this greed approach now :)
How to solve challenge problem div 2 c??
what are precomputed arrays of positions of players in 496D/497B Tennis Game Div. 1 B which reduce the complexity to O(nlogn)?
score[i] — the score of a player for the first i serves.
step[i] — how much serves are past until a player reaches the score = i.
s1 [i] = sum of points the player 1 has the index i of the main vector A1 [j] = index in the main vector that player 1 gets j points
There are the same vectors for player 2.
Using only the s1 and binary search is possible complexity n * log ^ 2 (n). Using s1 and a1 is possible complexity n * log (n).
Let a and b be two vectors containing positions in sequence where 1st and 2nd player wins respectively.
The arrays to be precomputed then are ta and tb where:
ta[i]: index in a such that a[ta[i]] > i
tb[j]: index in b such that b[tb[i]] > j
Can anyone explain in
496D - Tennis Gamewhy is itwrongto say thatnumber of valid (s,t) will be 0 if the total number of points of player who won the last point is less than or equal to another player.Because if the game is valid(i.e we have some valid s and t pair) this means the player who won it must have won
strictly moresets than other and hence more points.WA -->9231337
AC after I removed that condition --> 9231351
Not necessarily. Let, s = 2, t = 5 and consider the following score:
A B
0 5
5 4
5 4
In this case, B's total point is 13 while A's is 10, but the winner is A :)
Thnx, never thought of that :)
Div1D, why if we take A as the reference system, then the vertices on B are moving on a circle? I think the vertices on B are moving on a moving circle whose center is moving on a fixed circle. A is like sun, and B is moon, and our earth is reference system? Where am I wrong?497D - Gears
Problem D div 1:
"In this system the polygon B preserves its orientation (that is, does not rotate), and each of its vertices moves on some circle"
What circle? Can anyone give more detailed explanation? Or what should I study to understand this?
Let K be a point in polygon B. In the frame of reference in which A does not rotate, Q rotates around P in a circle (this should be easy to see).
What is a bit difficult to see is that, as the frame of reference is rotating counterclockwise around P and K is rotating clockwise around Q, K doesn't move relative to Q at all. Maybe this is easier to see with a picture:
ETA: I now noticed I accidentally switched the rotations so that Q is rotating clockwise and K is rotating counterclockwise in the picture. The principle still holds, though.
K' is where K would be after the rotation of the frame of reference. K is the final position after accounting for the fact that K is also rotating around Q with the same angular speed. As you can see, K is exactly at the same position relative to Q (directly above) in both pictures.
So K follows the exact same trajectory as Q, but with a constant translation.
Thank you. Your explanation is very clear.
Though only when 2 polygons rotate at the same angular speed, it has this nice property. What if 2 polygons rotate at different speed? How can it be solved?
I have the same approach for problem "496D — Tennis Game" and I still have TLE for test 23. Can anyone tell me why? here is my code 11077258 I have explained some steps in comments there.
How to solve the challenge version for 496E/497C
Maybe you can solve it as the simple version because it's equivalent to the reduction of an actor from 1 to Q!
497D - Gears
The Minkowski sum can be represented as a union of nm parallelograms, each of which is the Minkowski sum of a pair of sides of different polygons;But this slide mentions that to get Minkowski sum of two non-convex polygons $$$P$$$ and $$$Q$$$, at first we need to decompose $$$P$$$ and $$$Q$$$ into convex sub-polygons $$$P_1,...,P_k$$$ and $$$Q_1,...,Q_l$$$
Then we can get $$$P\oplus Q = \bigcup_{i,j}{P_i\oplus Q_j}$$$
In my solution, I triangulate both P and Q, then Minkowski sum over all pair of triangles from different polygons, and then check if the circle intersect the polygon or not, but got WA on 31(162191639).
Can you tell me, what I'm missing?
UPD: typo in the implementation of the
circle_segmentfunction.