


Adiv2
Для решения задачи будем хранить два массива hused[j] и vused[j] размера n, изначально заполненных false. Будем обрабатывать перекрестки в списке от 1-го к n-му, и если для i-го перекрестка оба значения hused[hi] и vused[vi] равны false , i-ый день нужно добавить к ответу и установить значения hused[hi] и vused[vi] в true, означающих, что hi-ая горизонтальная и vi-ая вертикальная теперь заасфальтирована, а в противном случае нужно просто пропустить очередной перекресток.
Такое решение работает за O(n2).
Авторское решение: 13390628
Bdiv2
Чтобы получить оптимальный ответ, роботу нужно двигаться от первого компьютера к последнему, затем от последнего к первому, потом опять от первого к последнему, и т.д., попутно собирая те части информации, которые он может собрать на момент нахождения рядом с компьютером. Таким образом робот будет по максимуму использовать ресурсы, затраченные на смену направления движения. Несмотря на наличие более быстрых решений, от участников требовалось лишь решение с асимптотикой O(n2).
Авторское решение: 13390612
Adiv1
Пусть ответ представляет собой массив a1 ≤ a2 ≤ ... ≤ an. Далее будем пользоваться тем, что gcd(ai, aj) ≤ amin(i, j).
Верно, что gcd(an, an) = an ≥ ai ≥ gcd(ai, aj) для любых 1 ≤ i, j ≤ n. Это значит, что an равен максимальному элементу таблицы. Запишем в ответ an максимальный ответ и удалим его из текущего набора элементов. После удаления gcd(an, an) в наборе будут содержаться gcd(ai, aj) для любых 1 ≤ i, j ≤ n, таких, что 1 ≤ min(i, j) ≤ n - 1.
Из последних двух неравенств следует, что gcd(ai, aj) ≤ amin(i, j) ≤ an - 1 = gcd(an - 1, an - 1). Поскольку в наборе содержится gcd(an - 1, an - 1), максимальный элемент в наборе равен an - 1. Поскольку an уже известен, удалим из набора gcd(an - 1, an - 1), gcd(an - 1, an), gcd(an, an - 1) . Теперь в наборе содержатся gcd(ai, aj), для любых 1 ≤ i, j ≤ n таких, что 1 ≤ min(i, j) ≤ n - 2.
Далее повторим это операцию для каждого k from n - 2 to 1, устанавливая ak равным максимальному элементу в оставшемся наборе и удаляя gcd(ak, ak), gcd(ai, ak), gcd(ak, ai) для всех k < i ≤ n из набора.
С помощью математической индукции нетрудно доказать корректность такого алгоритма. Чтобы быстро выполнять удаление и получение максимального элемента в наборе, можно использовать, например, структуры map или set, что позволит реализовать решение с асимптотикой 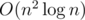 .
.
Авторское решение: 13390679
Bdiv1
Можно посчитать матрицу размера n × n mt[i][j] — длина наибольшей неубывающей подпоследовательности в массиве a1, a2, ..., an, начинающейся с элемента, не меньшего ai и заканчивающейся непосредственно в элементе aj.
Теперь, если мы имеем две матрицы размера n × n A[i][j] (ответ для массива a1, a2, ..., apn начинающегося с элемента, не меньшего ai и заканчивающейся элементом aj в последнем блоке массива (a(p - 1)n + 1, ..., apn) и B[i][j] (ответ для массива a1, a2, ..., aqn ), то произведение этих матриц
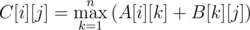
даст подобную матрицу, но для массива из p + q блоков. Так как такое произведение матриц является ассоциативным, воспользуемся быстрым возведением матрицы в степень для подсчета M[i][j] (ответ для массива a1, a2, ..., anT) — матрица mt[i][j] в степени T. Ответ на задачу — максимум матрицы M. Такое решение имеет асимптотику 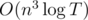 .
.
Авторское решение (с матрицами): 13390660
Существует альтернативное решение. Так как a1, a2, ..., anT содержит максимум n различных элементов, любая его неубывающая подпоследовательность содержит максимум n - 1 последовательных возрастающих соседних элементов. Пользуясь этим фактом, будем считать стандартное динамическое программирование на первых n блоках массива (a1, ..., an2) и на n последних блоках массива (anT - n + 1, ..., anT). Все остальные блоки (а их T - 2n) между ними будут порождать равные элементы в результирующей неубывающей подпоследовательности.
Таким образом, для фиксированного ai, в котором заканчивается неубывающая подпоследовательность длины p массива из первых n блоков, и для фиксированного aj ≥ ai, в котором аналогичная подпоследовательность длины s на последних n блоках массива начинается, нужно обновить ответ величиной p + (T - 2n)count(ai) + s, где count(x) — количество вхождений x в массив a1, ..., an. Получаем решение за  .
.
Авторское решение ( с динамикой): 13390666
Cdiv1
Зафиксируем s и рассмотрим каждую пару (l, s). Тогда, если превосходящий подмассива содержит ai, то ai должен быть не меньше каждого aj такого, что 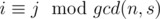 . Будем использовать этот факт и решать задачу для фиксированного g = gcd(n, s) (g|n). Для последующей проверки того, что ai может содержаться в превосходящем подмассиве, посчитаем для каждого 0 ≤ r < g
. Будем использовать этот факт и решать задачу для фиксированного g = gcd(n, s) (g|n). Для последующей проверки того, что ai может содержаться в превосходящем подмассиве, посчитаем для каждого 0 ≤ r < g
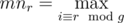 .
.
Каждый периодический подмассив состоит из 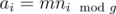 и только из них. Для нахождения количества таких подмассивов будем пользоваться методом двух указателей и для каждого подходящего ai такого, что
и только из них. Для нахождения количества таких подмассивов будем пользоваться методом двух указателей и для каждого подходящего ai такого, что 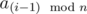 не является подходящим, найдем такое aj, что
не является подходящим, найдем такое aj, что 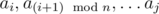 являются подходящими и
являются подходящими и 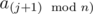 не является подходящим. Пусть представляет подотрезок из k элементов, т.е.
не является подходящим. Пусть представляет подотрезок из k элементов, т.е. 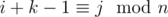 . Любой подотрезок этого подотрезка так же является превосходящим, поэтому к отрезкам длины 1, 2, ..., k мы должны прибавить k, k - 1, ..., 1 соответственно. Так как сумма всех k не превосходит n, можно циклом увеличивать нужные значения. Случай, когда все ai являются подходящими, нужно обрабатывать отдельно. После подсчета всех необходимых величин, мы должны добавить лишь те количества подотрезков длины x, для которых gcd(x, n) = g.
. Любой подотрезок этого подотрезка так же является превосходящим, поэтому к отрезкам длины 1, 2, ..., k мы должны прибавить k, k - 1, ..., 1 соответственно. Так как сумма всех k не превосходит n, можно циклом увеличивать нужные значения. Случай, когда все ai являются подходящими, нужно обрабатывать отдельно. После подсчета всех необходимых величин, мы должны добавить лишь те количества подотрезков длины x, для которых gcd(x, n) = g.
Описанное решение имеет асимптотику O(d(n)n), где d(n) — количество делителей n.
Авторское решение: 13390645
Ddiv1
Известно, что для простого p и натурального n максимальное α такое, что pα|n!, вычисляется по формуле 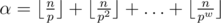 , где pw ≤ n < pw + 1. Так как
, где pw ≤ n < pw + 1. Так как 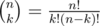 , максимальное α для
, максимальное α для 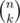 вычисляется по формуле
вычисляется по формуле 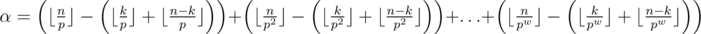 .
.
Примечательно, что если представить n, k и n - k в p-ичной системе счисления, деление числа с округлением вниз на px соответствует отбрасыванию последних x цифр в его p-ичном представлении. Поскольку k + (n - k) = n, i-ое слагаемое в формуле для α соответствует величине переноса разряда с i - 1-ой к i-ой цифре в сложении k и n - k в p-ичной системе счисления и может принимать значения ноль или один.
Переведем A в p-ичную систему счисления и будем далее работать только с этим его представлением. В случае, если α превышает количество цифр в представлении A то, как описано выше, ответ равен 0. Далее будем считать динамическое программирование на представлении числа A.
dp[i][x][e][r] — ответ, если мы рассмотрели первые i цифр числа n и k, при этом эти цифры в n могут равняться первым цифрам A (булева e), x-ая степень p уже была набрана, и величина переноса с текущего в следующий разряд равна r . Переходы будем осуществлять вперед, имея, таким образом, не более p2 вариантов расстановки цифр в n и k. Поскольку перебор всех таких вариантов невозможен, нужно заметить, что для перехода в фиксированное состояние (его первый параметр равен i + 1) количество вариантов расстановки цифр равняется сумме арифметической прогрессии, поэтому переход с помощью умножения на сумму прогрессии можно осуществлять за O(1).
Крайне рекомендуется ознакомиться с авторским решением за O(|A|2 + |A|min(|A|, α)).
Авторское решение: 13390698
Ediv1
Количество бинарных функций на 4 переменных равняется 224, и каждую из них можно закодировать двоичным числом из 24 бит , где значение каждого бита соответствует значению функций в наборе переменных, соответствующему номеру бита. Верно, что если maskf и maskg соответствуют функциям f(A, B, C, D) и g(A, B, C, D), то функции (f|g)(A, B, C, D) соответствует maskf|maskg bitmask.
Построим бинарное дерево разбора выражения. Замечу, что количество нелистовых вершин в нем равно 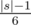 . Будем считать динамическое программирование для каждой вершины v дерева разбора — dp[v][mask] равно количеству способов вставить символы в выражение, образованное поддеревом вершины v так, чтобы оно соответствовало функции, задающейся маской mask. Для листовых вершин значения динамики вычисляются ``в лоб'' перебором каждой из 16 функций и подстановкой переменной в функцию. Для нелистовых вершин существует способ перебирать все пары варинтов функций в сыновьях за 416: dp[v][lmask|rmask] + = dp[l][lmask] * dp[r][rmask].
. Будем считать динамическое программирование для каждой вершины v дерева разбора — dp[v][mask] равно количеству способов вставить символы в выражение, образованное поддеревом вершины v так, чтобы оно соответствовало функции, задающейся маской mask. Для листовых вершин значения динамики вычисляются ``в лоб'' перебором каждой из 16 функций и подстановкой переменной в функцию. Для нелистовых вершин существует способ перебирать все пары варинтов функций в сыновьях за 416: dp[v][lmask|rmask] + = dp[l][lmask] * dp[r][rmask].
Однако вся задача в том, чтобы делать это быстрее. Давайте посчитаем s[mask], где s[mask] равняется сумме ответов динамики для всех подмасок mask (submask&mask = submask) за 24·224 операций с помощью следующего кода:
for (int mask = 0; mask < (1 << 16); ++mask) s[mask] = dp[x][mask];
for (int i = 0; i < 16; ++i)
for (int mask = 0; mask < (1 << 16); ++mask)
if (!(mask & (1 << i))) s[mask ^ (1 << i)] += s[mask];
Посчитаем sl[mask] и sr[mask] для dp[l][mask] и dp[r][mask] соответственно. Если приравнять s[mask] = sl[mask] * sr[mask], s[mask] будет хранить сумму произведений пар значений масок левого и правого сына, таких, что обе эти маски являются подмасками mask. Так как нам нужны пары, побитовый OR которых даст ровно mask, нужно исключить пары, побитовый OR которых дает подмаску mask, не равную mask. Для этого будем пользоваться формулой включений-исключений:
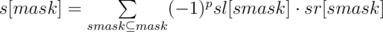 , где p равно количеству единичных бит в mask^submask.
, где p равно количеству единичных бит в mask^submask.
Такую сумму можно посчитать аналогичному выше образом, но используя вычитание вместо сложения:
for (int mask = 0; mask < (1 << 16); ++mask) s[mask] = sl[mask] * sr[mask];
for (int i = 0; i < 16; ++i)
for (int mask = 0; mask < (1 << 16); ++mask)
if (!(mask & (1 << i))) s[mask ^ (1 << i)] -= s[mask];
Таким образом можно пересчитывать значения динамики в вершине за 3·24·216 операций.
Авторское решение: 13390713






Будет русский разбор?
английский учи
I liked the problems, thanks!
Brute force, with a little bit of greedy, also passes for DIV2-C/DIV1-A.
Can someone explain test #5 from Div1 C?
It is said that the answer is 3 but I can only see two good pairs ((0,1) and (2,1)).
There is an another pair (2,2). We don't have a restriction l + s ≤ n
Ohh, thank you! I didn't assume that restriction but somehow missed that case anyway.
Similar problem to Div1 E was given in SRM 518 on Topcoder. The difference is that there was XOR instead of OR in the problem from that SRM. Interestingly enough, the approach from that problem can be used in Div1 E as well with a few modifications. For our problem the solution in terms described on Topcoder forum would be:
For example, if we want to compute
(x[0], x[1], ..., x[7]) @ (y[0], y[1], ..., y[7]) = (z[0], z[1], ..., z[7])Calculate two smaller
@operations:(x[0]+x[4], x[1]+x[5], x[2]+x[6], x[3]+x[7]) @ (y[0]+y[4], y[1]+y[5], y[2]+y[6], y[3]+y[7]) = (a, b, c, d)(x[0], x[1], x[2], x[3]) @ (y[0], y[1], y[2], y[3]) = (e, f, g, h)Then
z[0] = e,z[1] = f,z[2] = g,z[3] = h,z[4] = a - e,z[5] = b - f,z[6] = c - g,z[7] = d - h.I like to describe this approach in terms of formal polynomial multiplication where variables are taken from Z2 and coefficients belong to an arbitrary ring. I never seen a similar approach being described anywhere.
Consider a formal sum from Z2[x, x2, ..., xn] of form P(x1, ..., xn) = c0...00 + c0...01x1 + c0...10x2 + c0...11x1x2 + ... + c1...11x1x2... xn (the indices are binary masks of length n). We'll use the following rules of multiplication: coefficients c * are treated as usual numbers and are multiplied as numbers. Variables xi are multiplied like monomials with an additional rule that xi2 = xi (as if xi belonged to the field Z2).
Now we can multiply such polynomials, for example (3 + 2x1 - 3x2) × (x1 + 4x1x2) = 5x1 + 5x1x2.
Note that when we multiply polynomial P(x1, ..., xn) with coefficients {c0...0, ..., c1...1} by polynomial Q(x1, ..., xn) with coefficients {d0...0, ..., d1...1}, we get a polynomial R(x1, ..., xn) with coefficients {e0...0, ..., e1...1} satisfying the following formula:
It's exactly the formula of convolution we want to calculate, so now we'll understand how to calculate coefficients of product of polynomials $P$ and Q quickly.
Suppose that P(x1, ..., xn) = A(x2, ..., xn) + x1B(x2, ..., xn), Q(x1, ..., xn) = C(x2, ..., xn) + x1D(x2, ..., xn) (i. e. divide both polynomials into two parts, that contains x1 and that doesn't contain). Now let's rewrite the product:
. So, in order to multiply two polynomials of length $2^{n}$, we should perform O(2n) preparation work and then perform two multiplications of polynomials of length 2n - 1: A × C and (A + B) × (C + D). This leads to a recurrence alike to the Karatsuba's algorithm that does not three actions per recursive call but two:
.
That is exactly the same thing as everybody did (and as model solution), but I like this way of thinking since it allows to see the similarity of this algorithm and FFT or Karatsuba multiplication.
Жаль, что макстеста в претестах в Div1 E не было. Асимптотически верное решение не зашло:(
Solution link fr div2c is not working
As soon as a1, a2, ..., anT contains maximum n distinct elements, it's any non-decreasing subsequence has a maximum of n - 1 increasing consequtive element pairs. Using that fact, one could calculate standard longest non-decreasing subsequence dynamic programming on first n array blocks (a1, ..., an2) and longest non-decreasing subsequence DP on the last n array blocks (anT - n + 1, ..., anT).
I just can't catch that, and can you explain more about why we can precompute the first n array blocks and last n array blocks to get the answer? Although I got an AC with this approach just now, but I'm still puzzled, I'll be grateful if you can explain more about this.
If you consider an array from n to 1, you would need to go through the array n times to get the increasing sequence from 1 to n.
In this question, since you can't go through the entire sequence, we apply dp to a small portion of the entire sequence and extrapolate it to get the answer.
If you consider the blocks where you are actually changing the element you are at, you'll see that you're only doing n changes at max. This means that for the T - n blocks, you were stuck at a single element.
In order to bring a little order to this, we push the increments we are making to the beginning and ending, and let the blocks with the same element stay in the middle. A block which has only one element contributes only to its count in the original array, so there's also no point in having multiple elements stay the same in various blocks, one is enough.
Since we're leaving n blocks in the beginning and n blocks in the end, it gives us enough freedom to arrive to whichever element we want in the middle and start and end with whichever element we want.
Consider the example 456712344.
While it would be nice to take all 4s throughout the entire sequence, it would be little more optimal to choose 12344 in the first block, go for all 4s and then come to 4567 in the last block.
You are taking n^2 element at start and n^2 element at end. Calculating Longest non-decreasing subsequence for this alone cost you O(n^4).
But you mentioned overall complexity O(n^2logn). How are you calculating Longest non-decreasing subsequence in less time??
If you use the standard DP algorithm to find longest non-decreasing sub-sequence from n^2 elements then complexity will be O(n^4). By using the given constraints on elements (<=300), and making some changes : In DP part, instead of storing the length of longest non decreasing sub-sequence ending at ith position, you can maintain an array of size 300 and store the longest non decreasing sub-sequence ending at ith number. By doing so, the complexity will become O(300*n^2).
I can't find the solutions for DIV 2 C,D,E
Oh Alright! Its fine, this was my first contest, I didn't know that Div1 and Div2 had common problems, so basically Div2 C == Div1 A
In Bdiv1, C[i][j] = max(A[i][k] + B[k][j])?
I think it is C[i][j] = max(A[i][k] + B[k][j])
For Div2 B Robot's Task, what is the solution for 5 4 3 2 1 0
Isn't the solution 0?
No. You start from 0 position, so you should go all the way right to get the only piece of data you can then reverse and collect others.
Answer is 1
The robot is initially next to computer with number 1 (as the statement mentioned), so the answer will be 1.
I think in problem D, you need to prove the associativity of the operation over matrices!
It is indeed very close to matrix multiplication but it is not exactly matrix multiplication!
Brilliant solution by the way!
Let A be the answer for the first np numbers, B for nq, C for nr. By the definition (A × B) × C is the answer for the first n(p + q + r) numbers. It is obvious that A × (B × C) is also answer for n(p + q + r) numbers, so (A × B) × C = A × (B × C)
https://en.wikipedia.org/wiki/Max-plus_algebra
FYI
In problem Div2-D , second solution :
How we can prove that for middle part ( I mean T-2*n blocks in middle ) best solution is to select a[i]s ? not other selection between numbers a[i]<=x<=a[j].
Bdiv1
It should be max instead of min in the matrix multiplication, shouldn't it? Each sum Ai, k + Bk, j is the length of a possible non-decreasing subsequence of the sequence a1, a2... an(p + q). Why don't we just take the greatest possible length?
EDIT : Found the bug. Unable to find bug in my solution for Div2 C/Div 1 A. Gives WA on Test 23. Can anyone help me ? Solution
For the explanation of Div 1 C, mnr is defined as mini ≡ rmodg, but shouldn't this be the maximum? Since you want your element to be larger than or equal to all other elements it will cover.
fixed, thank you
http://mirror.codeforces.com/contest/582/submission/13403594 I don't know why this code doesn't work.
I was debugging my solution for GCD Table and i found that in test case 23, there is actually no solution. This solution does not get accepted 13406372 while this soltuion gets accepted 13406211. The difference between two is that is of a if condition which will occur only if for some number we don't have i,j gcd(ans[i],ans[j] )=number. Which a case for no possible. Correct me if i am wrong. Also if results, i have got, is correct then please reconsider grading Problem C div2 and Problem A div1 for this contest and update the ratings if possible.
Here's what's going wrong:
You first push a[i] onto ans, and later you remove all gcds between a[i] and numbers in ans, but the last element of ans is a[i], so you end up with two a[i]'s in your priority queue that shouldn't really be there. If you move the push_back behind the for loop it should work.
Honestly, you're lucky that second solution passes. EDIT: On second note, your second solution is correct, I didn't spot the
i++in the if-statement. Still, the first solution is very wrong.EDIT2: Here's a much simpler testcase that also goes wrong:
Your algorithm gives
12 7 5 2 2, where it should be12 7 5 2 1.I am having problem in understanding the approach explained in DIV2 D, can someone explain the solution.
Может кто-нибудь объяснить вот эту часть подробно?
Can anyone suggest further readings or link to understand the theoretic part of the solution in detail for Div 1 prob B using matrix expo? :D :D
could someone explain what's wrong with this solution of Div2-C http://mirror.codeforces.com/contest/583/submission/13487264 ?
For Ddiv1, could someone let me know where I can find more information about "It is a common fact that for a prime p and integer n maximum α, such that p^α|n! is calculated as ..."
So we want to calculate such maximum α that n! is divisible by pα.
Here is a formula for n!. Note that p is prime.
What multipliers are divisible by p? Every p-th multiplier is. There are n div p in total of such multipliers. We found that n! is at least divisible by p(n div p) at this moment.
Some of the multipliers are not only divisible by p, but also by p2. There are n div p2 in total. Each of the multiplier gives 2 to α. We have already considered them once above. To count them we should add n div p2. We found that n! is at least divisible by p(n div p + n div p2) at this moment.
We should continue this process until pw will be greater than n, and n div pw = 0.
Eventually we will receive the formula from the editorials.
Yup, same here. No idea why n segments are needed.
edit: n segments are needed for the case when a[] is a strictly decreasing array.
Oh no. Didn't read the problem statement correctly during the contest. I assumed robot can start from both ends that is from computer 1 and computer n. That's why i was getting WA.
In Bdiv1, I understand the "alternative solution". But I want to know how to access to problem like this at the first time. Please give me some advice.
I would really appreciate if the codes are well commented....
I need a better explanation for D please. I cannot understand last paragraph of D's editorial.
For div1 B / div2 D, I understood the second approach specified in the editorial, but couldn't understand the matrix approach, specifically how we get the relation:
$$$C[i][j] = maxOver(A[i][k]+B[k][j])$$$.
I tried observing the state of the matrix after each line, for various inputs, but still couldn't get the intuition behind this relation. Can someone please explain it?
Could someone help me to figure out why my code gives me WA on 5th test at problem B/div1? I have been thinking all the day but still cannot figure it out. Here is my submission: 213548711
I think test cases for problem Div 1 B.Once Again... is weak. My approach was exactly the same as second approach of the editorial. I used min(2*n, T) copies of the original array to calculate the best answer.
But I saw using 50 copies of the array this one got passed. But using 45 copies this one got failed. At least min(100, T) copies of the original are required to be considered.