


Недавно завершился 7ой этап Открытого кубка. Замечу, что альтернативного времени сегодня нет — задачи уже доступны для дорешивания.
Предлагаю обсудить здесь задачи контеста.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |







Расскажите, пожалуйста, как решать A и C.
А. Я просто выводил 32 буквы a и 32 буквы b в первой строке и 32 буквы c и 32 буквы b по второй строке =)
Корректность доказать можешь?
Да. Просто первые тридцать два слагаемые будут равны нулю (если брать по модулю 2^32). А остальная часть строк совпадает.
A? printf("aaaaaaaaaaaaaaaaaaaaaaa\naaaaaaaaaaaaaaaaaaaaaaaa\n");
а в C нужно для каждого слова составить маску — в какие строки она входит. после этого оставить только пары с уникальными масками, их будет не более 2^12. получается задача проорить минимальное количество чисел, до полной маски 111..111, можно динамикой за квадрат: минимальное количесво для получения маски M из первых N чисел.
В А находим две строки состоящих только из букв 'a' разной длины с одинаковым хешем. Я честно не знаю, почему это правильно. Код
В С для каждого слова посчитаем маску — в каких текстах оно встречается (можно это за O(L*lgL) сделать map'ом, где L — размер ввода). После этого для каждой маски выпишем слово которое ей соответствует, получится не более 2^N слов. Тогда можно посчитать F[i] — минимальное количество слов, чтобы покрыть маску i (те, которые встречаются в тех текстах, где в i единички). Ответ тогда F[2^n-1]. Код
Ну в А же множилка после некоторой степени обнуляется.
Мы просто генерили рендомные строки по 10 символов, пока не нашлись 2 с одинаковым хешом.
Да, на разборе было альтернативное решение — т. к. модуль 2^32 не очень большой, то можно сгенерировать 2^16 различных слов и по парадоксу дней рождения хотя бы у двух из них будут одинаковые хэши. Но, конечно, было проще заметить, что т. к. p — всегда четное, то при строке длиной больше 32 символов множители у первых букв будут делится на 2^32, т. е. давать по модулю 0, чего хватало для того, чтобы вывести две строки формата "одна различающаяся первая буква и еще штучек 40 одинаковых".
можно сгенерировать 2^16 различных слов и по парадоксу дней рождения хотя бы у двух из них будут одинаковые хэши с высокой вероятностью
На самом деле, вы правы, я тут посчитал, вероятность будет всего 39%. Вот если сгенерировать 2^18 строк, то она возрастет до 99.9%, чего, думаю, хватит.
как адекватно решалась D?
Я решал динамикой. [длина][состояние] — кол-во различных различных строк текущей длины и удовлетворяющему текущему состоянию.
Состояний всего 4.
0 — строка является префиксом A и B.
1 — строка является префиксом A и меньше B.
2 — строка является префиксом B и больше A.
3 — строка больше A и меньше B.
Для каждого состояния рассматривается несколько случаев, они довольно очевидны. А дальше собираем ответ из состояний 3. А также из состояний 2, когда префикс еще не является самой строкой B.
извиняюсь за некропост, но:
ведь можно было избавиться от нулевого состояния, удалив общий префикс строк?
и в таком решении нужно опасаться чего-то? переполнения или чего-нибудь? а то такое же решение ва18
и вообще, можете код показать?
Да, можно и так. Переполнение там есть. Если значение в каком-то состоянии динамики стало больше 10^9, то я приравнивал его к 10^9.
На контесте я, чтобы не ошибиться, расписал каждый случай для каждого состояния, поэтому код вышел довольно громоздкий. Код
сразу как написал, понял, что у меня состояние, в котором строка равна префиксу строки А, существует в длине большей длины А =(, исправил, получил ва27, хотя ровным счетом, тоже самое делаю
Мы решали просто перебором по длинам и для каждой длины l смотрели, сколько строк такой длины попадает между первой и второй строкой из инпута. Для этого можно из количества строк длины l, меньших второй, вычесть количество строк длины l, не больших первой. Единственное "но" — сами эти количества могут быть очень большими, поэтому лучше просто пересчитывать разность как diff[l]=diff[l-1]*26+s2[l-1]-s1[l-1].
Можно было сразу считать между двумя строками. Если результат больше 109, то обрезать его до 109. Правда там еще надо аккуратно рассмотреть случай, когда у нас всего одна строка данной длины. У нас подсчет количества строк длины len делался за O(N) и из-за этого ловили ТЛ. Чтобы сильно не модифицировать, мы бинпоиском нашли количество длин для которых возможна всего одна строка, а дальше уже перебирали остальные длины.
Как решать E? WA 21 постоянно.
Тоже был WA #21, если писать dfs. А если писать bfs по обратным ребрам с той же логикой (сначала добавляем выигрышные / проигрышные, и постоянно пополняем вершинами для которых уже становится все очевидно и т.д.), то заходит.
А можно тест, где dfs не работает?
Ну вы рёбра, по которым получился цикл считали за ничейные при рассмотрении некоторых вершин наверняка, а это неверно.
Предположим, у нас есть несколько вершин, между двумя из которых есть цикл, а из первой есть куча ребер в помеченные для любого игрока вершины.
У меня и с DFS AC. Просто считаем, в сколько каких вершин можем пойти из текущей и проверяем на выигрышность для каждого из игроков/ничейность. Единственная проблема которая была — это если ходим туда где сейчас считаем ответ, но тогда просто можно считать что у нас там ничья.
А можешь код показать?
Код
Мы, чтобы не особо париться, прошлись два раза, в итоге не было разбора случая с попаданием в текущую вершину. Как DFS мог TLилться — не понимаю, ведь на жабе наше зашло. Решение у нас было, как на разборе — запускаемся из всех вершин-нулей и для каждой вершины смотрим, сколько у нее переходов в вершины с единичками или двойками, если единичек больше или равно (n + 1)/2, то метим вершину единичкой, а если двоек больше, чем n / 2, то двойкой, где n — количество переходов из вершины. Ну а в конце смотрим, какой цифрой помечена вершина s.
Ну это же неверно.... Если мы прийдем в эту вершину другим способом, то можно было не проходить через вторую в которую приняли за ничью и вполне возможно, что надо будет идти именно туда. Только тестом это фиг завалишь.
емакс
Как решать I?
Мы решали построив суф. дерево по второму набору разделив строки #. Вроде хешами она сдавалась.
А как хешами? Бин. поиском для каждого слова с проверкой хешами?
Хешами — очень просто, Используем примитив "lcp двух подстрок чего-то из того, что дано на вход, за log length", с его помощью умеем сравнивать 2 любых суффикса за log их длины. Дальше сортим все суффиксы 2ого набора и ищем там бинпоиском суффиксы первого набора (наверное, можно было его тоже посортить и merge сделать). Итого n log^2.
Мне гораздо более интересно (в очередной раз :) ), как ее все суфдеревом посдавали. Неужели все настолько круты, что суфдерево с такой скоростью по памяти пишут? Чувствую себя неполноценным олимпиадником :(
Зачем по памяти? Можно же с бумажки перепечатать :-)
И принести с собой бумажку с суфдеревом? :) По правилам распечатывать во время контеста prewritten-code и перебивать его с бумажки нельзя.
Конечно принести! Ну не в наглую же с емакса копипастить) это же запрещено! :-)
А что, распечатывать перед контестом полный архив емакса уже не в моде? :)
Ну у нас в команде 2 человека кто сравнительно быстро пишут суф. дерево. Сегодня само дерево мы написали быстро, только набажили в решении самой задачи :-(
А какая сложность? С хешами я придумал лишь за O(MNlogN), что не должно проходить :)
Для суф. дерева сложность O(n + m). Для хешей точно не знаю мы его не писали.
У нас решение за O(n*log(m) + m) с помощью суффиксного автомата. Сконкатенируем все строки из второго набора через какой нибудь разделитель (я использовал '{' == 'z' + 1) и построим на нем суффиксный автомат. Пусть это будет строка t. Теперь несложно для строки s за O(length(s)) искать наибольшую общую подстроку со вторым набором (http://e-maxx.ru/algo/suffix_automata#26 там описано как это делать). После нахождения мы имеем максимальную длину, позицию в нашей строке s, где закончилось вхождение и состояние автомата в этот момент. Для каждого состояния можно предвычислить какое-нибудь его вхождение в строке t (например расстояния до ближайшего терминального состояния). По этим величинам не сложно определять строку и место вхождения в ней. Можно завести массив pref, pref[0] = 0, pref[i] — это сумма длин строк c 1 по i (в 1 индексации) + i (i добавляется за разделители). Теперь имея вхождение в строке t можно бинпоиском по массиву pref определить номер строки. Код: http://www.everfall.com/paste/id.php?95bwdonzu5su
так ведь можно во время считывания постоить два массива t = "it{is{just{text" номера = 1 1 0 2 2 0 3 3 3 3 0 4 4 4 4 позиции = 1 2 0 1 2 0 1 2 3 4 0 1 2 3 4 и решение становиться короче и линейное)
Да можно так, не подумали =)
А откуда log(m) берется в решении? Я почти такое же писал, но почему-то думаю, что у меня O(N + M).
UPD: не дочитал решение до конца.
У нас решение за линию с помощью автомата. Выше уже описано как это сделать.
Как искать наибольшую общую подстроку двух строк разобрано на http://e-maxx.ru. Осталось заметить, что второй набор можно соединить через доллар, а описанный алгоритм за линию обрабатывает каждый символ первого набора.
Oops, я слоупок.
Вот интересно, правильное решение F или нет. Рассмотрим выпуклую оболочку оппозиционеров. Очевидно, что искомая прямая проходит через какую-то вершину. Будем считать прямую "ориентированной" правым образом. Теперь рассмотрим некоторого нашиста вне этого многоугольника. Найдем область многоугольника, видимую нашистом. Границами ее являются две вершины многоугольника. Направления на эти вершины будут минимальным и максимальным углом прямой, для которой этот нашист будет пойман ОМОНом. Осталось решить задачу "дана окружность и куча отрезков с весом на ней. Найдите точку, покрытую суммарным наибольшим весом".
Как искать область видимости. Возьмем любую точку в выпуклом многоугольнике. Отсортируем по полярному углу все точки многоугольника. Теперь есть какой-то нашист. Найдем пересечение прямой, соединяющей точку и нашиста, с многоугольником (бинарным поиском). Очевидно, что обе границы области видимости по разную сторону от этой прямой и могут быть найдены тернарным поиском на максимум угла "точка — нашист — проверяемая точка" в нужной части многоугольника. При равных надо брать, например, точку, которая ближе к нашисту.
Такое как раз и придумалось. Только не представляю себе, кто сможет реализовать это без багов за разумное время. Там ведь еще отдельные случаи есть — всего один оппозиционер, например.
Кто-то знает, как делать B без linking-cutting tree?
А как делать В с помощью linking-cutting tree?
Идея похожа на решение простого Dynamic-Connectivity при помощи разделяй и властвуй. Только там мы добавляли ребра в DSU, а затем делали откаты, а здесь будем добавлять ребра в лес linking-cutting tree (LCT). Возможны 2 случая:
1) Ребро соединяет 2 компоненты связности. Тогда просто соединяем их и ставим в LCT на ребро метку 0.
2) Ребро соединяет 2 вершины из одной компоненты связности. Тогда увеличим на 1 метки на ребрах на пути между этими двумя вершинами.
Теперь, если заставить LCT хранить количество нулевых ребер в каждой компоненте, то это и будет равно количеству мостов.
Ой, хромающая теория. Я же не знаю, как обычный Dynamic-Connectivity решать :(
Надо применить разделяй и властвуй по запросам. А именно, разделить запросы на 2 части и рекурсивно посчитать для левой. Теперь, если в левой части есть какие-то запросы на добавление ребер, которые уже не будут удаляться в правой, то добавим их в нашу структуру перманентно. Остальные же запросы на удаление передадим вместе с оставшейся правой половиной запросов в рекурсию для второй части. При выходе из рекурсии откатываем все ребра, которые мы добавили на этом уровне.
Сколько раз одно и то же ребро могло быть добавлено в структуру одним и тем же запросом? Нетрудно убедиться, что на одном уровне рекурсии один и тот же запрос не будет обработан более чем 2 раза. Отсюда получаем, что сложность работы O(RKlogK), где O(R) — время выполнения одного запроса с нашей структурой.
Понял, а как откатывать DSU?
Ну как, если мы добавили туда ребро, т.е. объединили 2 множества, то при этом было сделано сколько-то изменений памяти. Запишем все эти изменения в стек. Теперь чтобы откатить объединение, достаточно откатить сделанные изменения в обратном порядке, т.е. в таком, в котором они лежат в стеке.
Разве неправда, что если мы не будем откатываться, а просто сохраним DSU во временном массиве, а потом вернем его назад асимптотика не изменится? Казалось бы на каждом уровне рекурсии мы в сумме сделаем O(n) копирований. И откатов кажется в худшем случае будет O(n) на одном уровне рекурсии. Вроде это одно и то же а первое заметно проще.
Так мы же на уровне k сделаем 2^k копирований, т.е. в сумме квадрат, разве нет?
Да но уровней вроде логарифм. Поэтому O(n * logn).
Уровней-то логарифм, но на каждый уровень мы заходим 2^k раз. А так как мы копируем не O(размера уровня), а O(N), то в сумме выходит квадрат.
Да точно.
А у меня такой вопрос. Доказательство сложности стандартной DSU использует амортизацию. Вроде как, его здесь нельзя применять.
Ну так из-за этого здесь DSU работает за O(logN), а не за O(alpha) на операцию.
Причем, как я понимаю, нельзя не писать ранги, так как без них квадрат?
Ну в общем да.
Да, и еще. Я правильно понял, что все запросы добавить/удалить одно и то же жадно в пары объединены? Т.е. если вход
То первое деление пополам во вторую половину ничего не переносит?
Нужно для каждого запроса на добавление найти следующий после него запрос на удаление этого же ребра.
Да, первое деление во вторую половину ничего не переносит.
Тогда для решаемой задачи возникает примерно такая идея, правда, я в ней ничего пока не понимаю сам %)
Будем хранить дерево компонент двусвязности. Нам нужно научиться добавлять и сразу удалять ребро, т.е. отвечать на "чистый" запрос с одним добавленным, и добавлять ребро постоянно. Проблема в том, что дерево может быть очень сильно перестроено добавленным ребром. Давайте в начале рекурсии сжимать все вершины, не упомянутые в запросах. Тогда на входе на уровень рекурсии размер дерева — O(количества запросов на отрезке), что суммарно по уровню не превосходит общего количества запросов.
Похоже на правду.
Из числа компонент двусявязности не выводится число мостов вроде.
Ну если помнить число компонент двусвязности и просто компонент связности, то вывести можно. Ведь компоненты двусвязности образуют лес.
Разобьем отрезки на блоки длины . Научимся обрабатывать блок за линию прекалка и
. Научимся обрабатывать блок за линию прекалка и 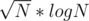 на запрос.
на запрос.
Похоже, что по задача Н все-таки rejudge?
Upd. Кстати, стандартному решению приходилось ставить if на пробный тест. А есть решения, которым это делать не приходилось?
Да. Там не соблюдалось ограничение на угол в тестах. Авторское решение работало настолько хорошо, что ему было пофиг.
После такого надо делать незачетный этап. Мы, например, видели, что у всех по этой задаче минус, и не решали ее. Другие много времени потратили.
snarknews думает что делать с этим.. По его мнению существенно повлияло это все на результат Petr Team и Akai, насколько я понял. Возможно будут деленные места. Еще он думает над вариантом добавить и это и азов и выкидывать два худших, а не один.
Да, это существенно повлияло на действия всех команд, и по-хорошему должен быть незачетный этап. Но тогда в этом сезоне как-то совсем мало этапов получается. Имхо, вариант "добавить и это и Азов" — вполне приемлемый, правда, я бы предложил в этом случае выкидывать 3 худших, а не 2 (1 + 2 полу-незачетных).
Если добавлять Азов — то нам, пожалуйста, с АС по E)
А если серьезно, неправильное авторское решение по задаче, которую активно решали участники — это повод сделать раунд безусловно незачетным. И неважно, как изменился монитор, если добавить/убрать АС.
Не знаю-не знаю, мне кажется, что если учитывать результаты с фейлами как у Азова — то уж точно без задачи, по которой был фейл (т.е. без E). Я конечно понимаю, что сдавшие ее потратили на это какое-то время, но вот многие из несдавших — потратили гораздо больше времени, т.к. писали/дебагали правильное решение.
snarknews сказал, что если и учтут, то после реджаджа.
Это существенно на поведение не менее 14 команд в последние 2-3 часа контеста. Если бы этой задачи не было вообще или если бы по ней были правильные тесты, кто-то бы не отлаживал правильный код, а решал другие задачи. И монитор мог бы быть совсем другим. Это не говоря про такие команды, как мы, кто не стал браться за эту задачу.
Не знаю. Лично я бы не стал ее решать имея достаточно времени на B почти ни при каком мониторе. Те кто отлаживал правильный код это как раз Петя, Akai и Гена. Но Гена и так первый. Ну что многие видя минусы в мониторе взялись за что--то другое это действительно проблема.
Забываешь про нас, мы полтора часа дебагали правильный код ;)
Если вы претендуете решать это задачу, то не надо писать div2.
В div2 была эта задача)
Как сказал мне steiner , если мы претендуем писать div1, не надо просыпать контест на 40 минут.
Кстати, моя универская специализация — обработка изображений ;) Распознать отрезки без шума далеко не самая сложная задача.
А не подкинете какие-нибудь ссылки на статьи хорошие по этой тематике, распознавание образов и кластеризацию?
Akai переживёт если контест будет рейтинговым....
"_snarknews думает что делать с этим.. По его мнению существенно повлияло это все на результат Petr Team и Akai_".
На Гену это тоже немножко повлияло. Во всяком случае в результате перетестирования он получил по этой задаче 21 Aссepted. В каком-то смысле личный рекорд :)
Я не против если Гене дадут 101 балл за этап. С первым местом подавать апелляцию на нерейтинговость раунда странно.
Однако дали всего 90. Так что иногда и первое место бывает заинтересовано в нерейтинговости раунда)
Ну, не совсем. Если бы раунд был не рейтинговым, то у нас было бы 400 очков на лучших 5 этапах, а у Гены 310 на лучших 4х — отрыв 90 очков, а сейчас у нас 480 на лучших 6, а у Гены 400 на лучших 5 — отрыв 80.
А в чем смысл такого сравнения? Вас на N+1 этапе по сравнению с Геной?
Ну, учитываются в общем зачете все этапы, кроме одного. Если мы займем на последнем этапе место не выше третьего, то это наши окончательные очки, а Гена сможет что-то добавить
Про еще один этап я как-то прозевал. Это точно, где-то об этом писали?
Да, насколько я знаю. Вроде бы 20 или 27 числа
На сайте пока еще под вопросом стоит. snarknews на чемпе тоже вроде говорил, что может быть будет. Уже все успело измениться?
Последний раз мне Снарк говорил про "95% что будет"
В расписании он уже не под вопросом. А есть предположения что это? Я вроде что-то слышал про Варшаву.
Мне snarknews сказал сразу после Гран-При СПб, что скорее всего будет называться "Гран-При Северной Америки"
Мое решение могло не опираться на это ограничение, но лучше было опираться.
Можно вместо перепрыгивания на угол PI/8, чтобы избежать повторного нахождения того же отрезка, ввести поиск локальных максимумов на томограмме с последующим выкидыванием отрезков, которые очень сильно похожи на одинаковые (фактически, раствор угла между ними будет порядка 3/длина). Остальные отрезки, как и округление, можно считать практически шумом и просто предварительно смазывать томограмму.
Upd. Более того, если выводить сертификат, можно вообще отказаться от условия по углу (и умный чекер будет засчитывать неразличимые случаи почти касающихся отрезков), правда, это задача для марафона, ибо точное решение практически нереально.
Ответы были правильными на тест. Не соблюдалось только ограничение по углу.
а как можно найти условия прошедших опенкапов?
например gp1: http://opencup.ru/files/ocb/gp1/problems.pdf — на русском http://opencup.ru/files/ocb/gp1/problems-e.pdf — на английском
А можно-ли как то по-быстрому найти оригинальные индексы вершин в изменённом многоугольнике в задаче G? Мы писали КМП на двух массивах из элементов
(длина стороны, следующий угол)(оба многоугольника так закодированы).Мы писали хеши для этого. Точнее Dmitry_Egorov писал. Он вообще хеши любит. Я бы тоже кмп писал. Не думаю, что можно что-то принципиально другое. Разве что привести оба к лексикографически минимальному сдвигу, но это явно не проще.
Небольшой оффтоп
Знавал я человека, который даже КМП/Z-func писал хешами...
Авторские решения тоже с алгоритмами на строках (одно с КМП, другое с хешами).
Странно, что еще никто не написал. На opencup.ru объявление по раунду.
Восьмой гран-при всё-таки перенесли на 27 число? Не очень удачное пересечение с RCC. А потом еще и на codeforces'e раунд.. Насыщенный день :D
...а ещё у некоторых на следующий день ЕГЭ по информатике...