A.Mike and Cellphone
Author:danilka.pro.
Developed:I_Love_Tina,ThatMathGuy
We can try out all of the possible starting digits, seeing if we will go out of bounds by repeating the same movements. If it is valid and different from the correct one, we output "NO", otherwise we just output "YES".
C++ codepair < int , int > s[55][55];
int v[55][55];
pair < int , int > where[55];
int main(void)
{
for (int i = 1;i <= 10;++i)
for (int j = 1;j <= 10;++j)
v[i][j] = -1;
v[1][1] = 1;
v[1][2] = 2;
v[1][3] = 3;
v[2][1] = 4;
v[2][2] = 5;
v[2][3] = 6;
v[3][1] = 7;
v[3][2] = 8;
v[3][3] = 9;
v[4][2] = 0;
for (int k = 0;k <= 9;++k)
for (int i = 1;i <= 4;++i)
for (int j = 1;j <= 4;++j)
if (v[i][j] == k) where[k] = {i,j};
for (int i = 0;i <= 9;++i)
for (int j = 0;j <= 9;++j)
s[i][j] = {where[i].x - where[j].x,where[i].y - where[j].y};
string number;
int len;
fi>>len;
fi>>number;
vector < string > ans;
for (int k = 0;k <= 9;++k)
if (k != number[0] - '0')
{
string cnt = "";
cnt += k + '0';
auto pos = where[k];
for (int i = 0;i < len - 1;++i)
{
pos.x += s[number[i+1] - '0'][number[i] - '0'].x;
pos.y += s[number[i+1] - '0'][number[i] - '0'].y;
if (1 <= pos.x && pos.x <= 4 && 1 <= pos.y && pos.y <= 3 && v[pos.x][pos.y] != -1)
cnt += v[pos.x][pos.y] + '0';
else break;
}
if (cnt.length() == len)
{
fo << "NO\n";
return 0;
}
}
puts("YES");
return 0;
}
Another C++ codepair<int, int> pos[10];
int n;
char a[100]; pair<int, int> v[100];
pair<int, int> operator - (pair<int, int> a, pair<int, int> b){
return mp(a.first - b.first, a.second - b.second);
}
pair<int, int> operator + (pair<int, int> a, pair<int, int> b){
return mp(a.first + b.first, a.second + b.second);
}
bool inside(pair<int, int> pos){
return (pos.first <= 3 && 1 <= pos.first && pos.second <= 3 && pos.second >= 1) || pos == (mp(4, 2));
}
int main(){
int cnt = 0;
FOR(x, 1, 3){
FOR(y, 1, 3){
cnt++;
pos[cnt] = mp(x, y);
}
}
pos[0] = mp(4, 2);
cin >> n;
scanf("%s", a+1);
FOR(i, 1, n-1){
v[i] = pos[a[i+1] - '0'] - pos[a[i] - '0'];
}
if(n == 1) return cout << "NO", 0;
int c = 0;
FOR(i, 0, 9){
bool ok = true;
pair<int, int> curr_pos = pos[i];
FOR(i, 1, n-1){
curr_pos = curr_pos + v[i];
if(!inside(curr_pos)) ok = false;
}
if(ok) c++;
}
if(c == 1) return cout << "YES", 0;
cout << "NO";
}
Another C++ code#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
bool mark[11];
bool flag1,flag2;
int main()
{
ll n;
string s;
cin>>n;
cin>>s;
for(int i=0;i<n;i++){
mark[s[i]-'0']=true;
}
if((mark[1]||mark[2]||mark[3])&&(mark[7]||mark[9]))
flag1=true;
if((mark[1]||mark[4]||mark[7])&&(mark[3]||mark[6]||mark[9]))
flag2=true;
if((mark[1]||mark[2]||mark[3])&&mark[0]){
cout<<"YES";
return 0;
}
if(flag1&&flag2){
cout<<"YES";
return 0;
}
cout<<"NO";
return 0;
}
Python coden = int(raw_input())
s = raw_input()
a = []
for i in range(10):
a.append(True)
for i in range(n):
c = int(s[i])
a[c] = False
inc = 0
if a[1] and a[2] and a[3]:
inc = -3
if a[7] and a[9] and a[0]:
inc = +3
if a[1] and a[4] and a[7] and a[0]:
inc = -1
if a[3] and a[6] and a[9] and a[0]:
inc = +1
if inc == 0:
print("YES")
else:
print("NO")
B. Mike and Shortcuts
Author:danilka.pro,I_Love_Tina
Developed:I_Love_Tina,ThatMathGuy
We can build a complete graph where the cost of going from point i to point j if |i - j| if ai! = j and 1 if ai = j.The we can find the shortest path from point 1 to point i.One optimisation is using the fact that there is no need to go from point i to point j if j ≠ s[i],j ≠ i - 1,j ≠ i + 1 so we can add only edges (i, i + 1),(i, i - 1),(i, s[i]) with cost 1 and then run a bfs to find the shortest path for each point i.
You can also solve the problem by taking the best answer from left and from the right and because ai ≤ ai + 1 then we can just iterate for each i form 1 to n and get the best answer from left and maintain a deque with best answer from right.
Complexity is O(N).
C++ code with queueint d[1 << 20];
int s[1 << 20];
queue < int > Q;
void go(int k,int val)
{
if (d[k]) return;
d[k] = val;
Q.push(k);
}
int main(void)
{
int n;
scan(n);//scan integer
for (int i = 1;i <= n;++i) scan(s[i]);
go(1,1);
while (!Q.empty())
{
int node = Q.front();
Q.pop();
go(s[node],d[node] + 1);
if (node > 1) go(node - 1,d[node] + 1);
if (node < n) go(node + 1,d[node] + 1);
}
for (int i = 1;i <= n;++i) print(d[i] - 1);
eol;
return 0;
}
C++ code with deque#include <bits/stdc++.h>
using namespace std;
const int N = int(1e6) + 5;
int n, d[N], a[N], bd[N];
int main() {
assert(cin >> n);
for (int i = 0; i < n; ++i) {
assert(scanf("%d", &a[i]) == 1);
a[i]--;
d[i] = i;
}
for (int i = 0; i < n; ++i)
bd[i] = int(1e9);
deque <int> st;
for (int i = 0; i < n; ++i) {
if (i)
d[i] = min(d[i], d[i - 1] + 1);
while (!st.empty() && st.front() < i)
st.pop_front();
if (!st.empty())
d[i] = min(d[i], bd[st.front()] - i);
d[a[i]] = min(d[a[i]], d[i] + 1);
bd[a[i]] = a[i] + d[a[i]];
while (!st.empty() && bd[a[i]] <= bd[st.back()])
st.pop_back();
st.push_back(a[i]);
}
for (int i = 0; i < n; ++i) {
if (i)
putchar(' ');
printf("%d", d[i]);
}
return 0;
}
Python codeimport Queue
n = int(raw_input())
a = raw_input().split(' ')
used = []
d = []
for i in range(0, n):
used.append(False)
d.append(-1)
q = Queue.Queue()
q.put(0)
d[0] = 0
while not(q.empty()):
v = q.get()
for dl in range(-1, +2):
u = v + dl
if 0 <= u and u < n and d[u] == -1:
d[u] = d[v] + 1
q.put(u)
u = int(a[v]) - 1
if d[u] == -1:
d[u] = d[v] + 1
q.put(u)
for i in range(0, n):
print(d[i])
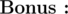 What if you have Q queries Q ≤ 2 × 105 of type (xi, yi) and you have to answer the minimal distance from xi to yi.
What if you have Q queries Q ≤ 2 × 105 of type (xi, yi) and you have to answer the minimal distance from xi to yi.
C. Mike and Chocolate Thieves
Author:danilka.pro,I_Love_Tina
Developed:I_Love_Tina,ThatMathGuy
Suppose we want to find the number of ways for a fixed n.
Let a, b, c, d ( 0 < a < b < c < d ≤ n ) be the number of chocolates the thieves stole. By our condition, they have the form b = ak, c = ak2, d = ak3,where k is a positive integer. We can notice that 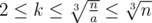 , so for each k we can count how many a satisfy the conditions 0 < a < ak < ak2 < ak3 ≤ n, their number is
, so for each k we can count how many a satisfy the conditions 0 < a < ak < ak2 < ak3 ≤ n, their number is 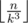 . Considering this, the final answer is
. Considering this, the final answer is 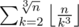 .
.
Notice that this expression is non-decreasing as n grows, so we can run a binary search for n.
Total complexity: Time ~ 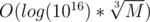 , Space: O(1).
, Space: O(1).
C++ code
ll get(ll x)
{
ll ans = 0;
for (int i = 2;1ll * i * i * i <= x;++i)
ans += x / (1ll * i * i * i);
return ans;
}
int main(void)
{
ll m;
fi>>m;
ll n = 0;
for (ll k = 1ll << 60;k;k /= 2)
if (n + k <= 1e16 && get(n+k) < m) n += k;
++n;
if (get(n) == m) fo << n << '\n';
else fo << "-1\n";
return 0;
}
Another C++ code
# include <bits/stdc++.h>
using namespace std;
long long get(long long n)
{
long long ans = 0;
for (long long i = 2; i * i * i <= n;++i)
ans += n / (1ll*i * i * i);
return ans;
}
int main()
{
long long m,n=-1;
cin>>m;
long long l=0,r=5e15;
while (l<r)
{
long long mid = (l+r)/2;
if (get(mid)<m) l=mid+1;
else r=mid;
}
if (get(l)==m) n=l;
cout << n << '\n';
return 0;
}
D. Friends and Subsequences
Author:I_Love_Tina
Developed:I_Love_Tina,ThatMathGuy
First of all it is easy to see that if we fix l then have 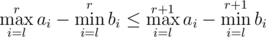 . So we can just use binary search to find the smallest index rmin and biggest index rmax that satisfy the equality and add rmax - rmin + 1 to our answer. To find the min and max values on a segment [l, r] we can use Range-Minimum Query data structure.
. So we can just use binary search to find the smallest index rmin and biggest index rmax that satisfy the equality and add rmax - rmin + 1 to our answer. To find the min and max values on a segment [l, r] we can use Range-Minimum Query data structure.
The complexity is  time and space.
time and space.
C++ code O(N)
#include <bits/stdc++.h>
using namespace std;
int n, a[200001], b[200001];
long long ans;
deque<int> mx, mn;
int main() {
scanf("%d",&n);
for(int i = 1; i <= n; i++) scanf("%d", &a[i]);
for(int i = 1; i <= n; i++) scanf("%d", &b[i]);
for(int i = 1, j = 1; i <= n; i++) {
while(!mx.empty() and a[mx.back()] <= a[i]) mx.pop_back();
while(!mn.empty() and b[mn.back()] >= b[i]) mn.pop_back();
mx.push_back(i);
mn.push_back(i);
while(j <= i and a[mx.front()] - b[mn.front()] > 0) {
j++;
while(!mx.empty() and mx.front() < j) mx.pop_front();
while(!mn.empty() and mn.front() < j) mn.pop_front();
}
if(!mx.empty() and !mn.empty() and a[mx.front()] == b[mn.front()]) ans += min(mx.front(), mn.front()) - j + 1;
}
printf("%lld", ans);
}
C++ code O(N log N)
# include <bits/stdc++.h>
# define scan(x) scanf("%d",&x)
using namespace std;
# define fi cin
# define fo cout
int dx[20][1 << 20];
int dy[20][1 << 20];
int lg[1 << 20];
int mx(int l,int r)
{
int p = lg[r - l + 1];
return max(dx[p][l],dx[p][r - (1 << p) + 1]);
}
int mn(int l,int r)
{
int p = lg[r - l + 1];
return min(dy[p][l],dy[p][r - (1 << p) + 1]);
}
int main(void)
{
int n;
scan(n);
for (int i = 1;i <= n;++i) scan(dx[0][i]);
for (int i = 1;i <= n;++i) scan(dy[0][i]);
for (int p = 1;(1 << p) <= n;++p)
for (int i = 1;i + (1 << p) - 1 <= n;++i)
dx[p][i] = max(dx[p-1][i],dx[p-1][i + (1 << (p-1))]),
dy[p][i] = min(dy[p-1][i],dy[p-1][i + (1 << (p-1))]);
for (int i = 2;i <= n;++i)
lg[i] = lg[i >> 1] + 1;
long long ans = 0;
for (int i = 1;i <= n;++i)
if (mx(i,i) <= mn(i,i))
{
int l = i-1,r = i;
for (int p = 1 << lg[n - i + 1];p;p >>= 1)
{
if (p + l <= n && mx(i,l+p) < mn(i,l+p)) l += p;
if (p + r <= n && mx(i,r+p) <= mn(i,r+p)) r += p;
}
ans += r - l;
}
fo << ans << '\n';
}
C++ code O(N log ^ 2 N)
int a[1 << 20];
int b[1 << 20];
int Sa[1 << 20];
int Sb[1 << 20];
int n;
int lg[1 << 20];
void updA(int i,int val)
{
for (;i <= n;i += i&(-i)) Sa[i] = max(Sa[i],val);
}
int quA(int i)
{
int ans = -(1e9+1);
for (;i;i -= i&(-i)) ans = max(ans,Sa[i]);
return ans;
}
void updB(int i,int val)
{
for (;i <= n;i += i&(-i)) Sb[i] = min(Sb[i],val);
}
int quB(int i)
{
int ans = (1e9+1);
for (;i;i -= i&(-i)) ans = min(ans,Sb[i]);
return ans;
}
int mx(int T)
{
return quA(T);
}
int mn(int T)
{
return quB(T);
}
int main(void)
{
for (int i = 2;i <= 1e6;++i) lg[i] = lg[i/2] + 1;
scan(n);
for (int i = 1;i <= n;++i) scan(a[i]),Sa[i] =-(1e9+1);
for (int i = 1;i <= n;++i) scan(b[i]),Sb[i] = (1e9+1);
ll ans = 0;
for (int i = n;i;--i)
{
updA(i,a[i]);
updB(i,b[i]);
if (mx(i) > mn(i)) continue;
int l = i-1,r = i;
for (int p = 1 << lg[n - i + 1];p;p >>= 1)
{
if (p + l <= n && mx(l+p) < mn(l+p)) l += p;
if (p + r <= n && mx(r+p) <= mn(r+p)) r += p;
}
ans += r - l;
}
fo << ans << '\n';
return 0;
}
Another C++ code
#include <bits/stdc++.h>
using namespace std;
const int N = int(1e6) + 5;
int a[N], b[N], n;
int lfa[N], rga[N], lfb[N], rgb[N], nxt[N];
void calc_max(int *a, int *lf, int *rg) {
stack <int> st;
a[n] = int(1e9) + 1;
for (int i = 0; i <= n; ++i) {
while (!st.empty() && a[st.top()] < a[i]) {
rg[st.top()] = i;
st.pop();
}
lf[i] = st.empty() ? -1 : st.top();
st.push(i);
}
}
int naive() {
int res = 0;
for (int i = 0; i < n; ++i)
for (int j = i; j < n; ++j)
if (*max_element(a + i, a + j + 1) == *min_element(b + i, b + j + 1))
res++;
return res;
}
bool read() {
if (!(cin >> n))
return false;
for (int i = 0; i < n; ++i)
assert(scanf("%d", &a[i]) == 1);
for (int i = 0; i < n; ++i)
assert(scanf("%d", &b[i]) == 1);
}
void solve() {
calc_max(a, lfa, rga);
for (int i = 0; i < n; ++i)
b[i] = -b[i];
calc_max(b, lfb, rgb);
map <int, int> pos, last;
for (int i = 0; i < n; ++i) {
b[i] = -b[i];
nxt[i] = n;
if (!pos.count(b[i]))
pos[b[i]] = i;
else
nxt[last[b[i]]] = i;
last[b[i]] = i;
}
long long res = 0;
for (int i = 0; i < n; ++i) {
if (!pos.count(a[i]))
continue;
int pb = pos[a[i]];
while (nxt[pb] <= i) {
pb = nxt[pb];
if (lfb[pb] != -1 && b[lfb[pb]] == b[pb])
lfb[pb] = lfb[lfb[pb]];
}
pos[a[i]] = pb;
for (int t = 0; t < 2 && pb < n; ++t, pb = nxt[pb]) {
int lf = max(lfa[i], lfb[pb]);
int rg = min(rga[i], rgb[pb]);
if (lf < min(i, pb) && max(i, pb) < rg)
res += (min(i, pb) - lf) * 1ll * (rg - max(i, pb));
}
}
cout << res << endl;
}
int main() {
while (read())
solve();
return 0;
}
What if you need to count (l1, r1, l2, r2), 1 ≤ l1 ≤ r1 ≤ n, 1 ≤ l2 ≤ r2 ≤ n and 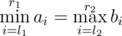 .
.
Hint:Take idea from this problem.
C++ code for Bonus
const int mod = 1e9 + 7;
int a[1 << 20];
int b[1 << 20];
int st[1 << 20];
int dr[1 << 20];
map < int , ll > A,B;
int main(void)
{
int n;
IOS;
fi>>n;
for (int i = 1;i <= n;++i) fi>>a[i];
for (int i = 1;i <= n;++i) fi>>b[i];
deque < int > d;
for (int i = 1;i <= n;++i)
{
while (!d.empty() && a[d.back()] < a[i]) d.pop_back();
if (d.empty()) st[i] = 0;
else st[i] = d.back();
d.push_back(i);
}
d.clear();
for (int i = n;i;--i)
{
while (!d.empty() && a[d.back()] <= a[i]) d.pop_back();
if (d.empty()) dr[i] = n+1;
else dr[i] = d.back();
d.push_back(i);
}
for (int i = 1;i <= n;++i)
A[a[i]] += 1ll * (i - st[i]) * (dr[i] - i);
while (!d.empty()) d.pop_back();
for (int i = 1;i <= n;++i)
{
while (!d.empty() && b[d.back()] > b[i]) d.pop_back();
if (d.empty()) st[i] = 0;
else st[i] = d.back();
d.push_back(i);
}
d.clear();
for (int i = n;i;--i)
{
while (!d.empty() && b[d.back()] >= b[i]) d.pop_back();
if (d.empty()) dr[i] = n+1;
else dr[i] = d.back();
d.push_back(i);
}
for (int i = 1;i <= n;++i)
B[b[i]] += 1ll * (i - st[i]) * (dr[i] - i);
for (auto &it : A) it.y %= mod;
for (auto &it : B) it.y %= mod;
int ans = 0;
for (auto it : A)
ans = (ans + 1ll * it.y * B[it.x]) % mod;
fo << ans << '\n';
return 0;
}
E. Mike and Geometry Problem
Author:I_Love_Tina
Developed:I_Love_Tina,ThatMathGuy
Let define the following propriety:if the point i is intersected by p segments then in our sum it will be counted 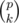 times,so our task reduce to calculate how many points is intersected by i intervals 1 ≤ i ≤ n.Let dp[i] be the number of points intersected by i intervals.Then our answer will be
times,so our task reduce to calculate how many points is intersected by i intervals 1 ≤ i ≤ n.Let dp[i] be the number of points intersected by i intervals.Then our answer will be 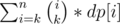 . We can easily calculate array dp using a map and partial sum trick,here you can find about it.
. We can easily calculate array dp using a map and partial sum trick,here you can find about it.
The complexity and memory is and O(n).
C++ code
# include <bits/stdc++.h>
using namespace std;
# define fi cin
# define fo cout
# define x first
# define y second
const int nmax = 2e5 + 5;
const int mod = 1e9 + 7;
int pow(int a,int b,int mod)
{
int ans = 1;
while (b)
{
if (b&1) ans = (1ll * ans * a) % mod;
a = (1ll * a * a) % mod;
b /= 2;
}
return ans;
}
int f[nmax];//factorial
int c[nmax];//inverse of factorial
map < int , int > s;
int C(int n,int k) // combination
{
int ans = (1ll * f[n] * c[k]) % mod;
return (1ll * ans * c[n - k]) % mod;
}
main(void)
{
int n,k;
int ans = 0;
ios_base :: sync_with_stdio(0);
fi>>n>>k;assert(1 <= k && k <= n && n <= 2e5);
f[0] = c[0] = 1;
for (int i = 1;i <= n;++i) f[i] = (1ll * f[i-1] * i) % mod,c[i] = pow(f[i],mod-2,mod);
for (int i = 1;i <= n;++i)
{
int a,b;
fi>>a>>b;
assert(-1e9 <= a && a <= b && b <= 1e9);
++s[a];--s[b+1];
}
int l = s.begin()->x;
int sum = 0;
for (auto it : s)
{
int dist = it.x - l;
if (sum >= k) ans += (1ll * C(sum,k) * dist) % mod;
ans = (ans >= mod ? ans - mod : ans);
sum += it.y;
l = it.x;
}
return fo << ans << '\n',0;
}
Another C++ solution#include <bits/stdc++.h>
#define ll long long
#define ld long double
using namespace std;
const int mod = 1e9+7;
ll pp(ll x, int y)
{
if (!y) return 1;
ll t = pp(x,y/2);
t = 1ll*t*t;
t%=mod;
if (y%2) t*=1ll*x;
t%=mod;
return t;
}
int n,k;
struct s
{
int x;
int y;
};
s a[2*200000];
ll c[200001];
void gen()
{
ll b = 1;
c[k] = 1;
for (int i=k+1; i<=n; i++)
b*= i,b%=mod,b*=pp(i-k,mod-2),b%=mod,c[i]=b;
}
ll ans = 0;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(0);
cin>>n>>k;
gen();
for (int i=0; i<n; i++)
cin>>a[2*i].x>>a[2*i+1].x,a[2*i].y = 1,a[2*i+1].y=-1,a[2*i+1].x++;
sort(a,a+2*n, [] (s x, s y) { if (x.x!=y.x) return (x.x<y.x); return (x.y>y.y);});
int last = a[0].x;
int now = 0;
for (int i=0; i<2*n;)
{
int d = a[i].x;
ans += 1ll * c[now] * (d-last);
ans%=mod;
while (a[i].x==d)
now+=a[i].y,i++;
last = d;
}
cout<<ans;
return 0;
}
what if 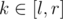 where l, r are given in input.
where l, r are given in input.
I'm really sorry that problem A was harder than ussually.









biggest solution ever for a div2 A
and safest
In Problem C, wasn't the upperbound of m 10^15 and not 10^16?
Yes, but the upper bound on n is 8*m if (k = 2 ). So the log(10^16) factor.
I didn't understand. Can you please elabore? Also, in the second C++ code given in the editorial , why has the upperlimit of the binary search been put to 1e15 instead of 1e15 ?
Lets take a particular value of
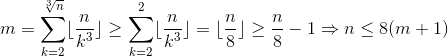
nand calculatemnumber of ways to steal chocolates. We will get something like this:so we can set
8*(m+1)as upper bound for binary search.So, why then is the upper limit in the binary search set to 5e15, instead of 8e15?
for k = 1e15, the answer is about 4.9*(1e15). That's why you can put limit to be 5*1e15.
What does log(10^15) mean? The upper bound is not clear to me.
See my comment above,
n <= 8*(m+1)and10^16is greater than8*(m+1)for anymthat satisfies input constraintsThanks!
BolsoMito
Contest was about to end, and I realized that I was solving bonus version of D... :(
Can D be solved in O(N) using two pointers?
You can use deque to find max/min + two pointer
Is there anybody who got AC for two pointers? I'm stuck with a bug right now and I don't know what I'm doing wrong.
I also thought that something like two pointers would help here. So I came up with this solution and got AC 18974188. The idea is to calculate in each iteration the number of segments that end at the current index and have max = min. I believe that it has O(N) complexity but can't prove it.
I think my code for problem A is easier to read than author code ==. sorry for my bad English http://mirror.codeforces.com/contest/689/submission/18925245
you're right about that,i added this solution to editorial,thank you.
Please, could someone help me. Why my solution for E is wrong on pretest 10?
18937604
I will be more careful with parenthesis next time.
Thank you so much
I used a different approach for the problem B. We can use a Segment Tree in order to get the nearest incoming shortcut in the range [i..N] and update the answer. O(N*log(N))... http://mirror.codeforces.com/contest/689/submission/18937575 Now I can sleep... I will read the tutorial after... Thanks a lot for the problems... Nice contest (Sorry for my poor English)
Actually you can run a simple bfs on the graph, since the graph edges cost only 1. You only have to know the levels of each nodes.
Yes. I know it now... But in the contest i don't realize it. I over killed the problem... :( . I submitted my solution 10 min after the contest has ended.
can you clarify more your solution by segments Tree ?
There is a greedy property in this problem, if you have two entry points (by shorcuts), you always must choose the leftmost point.
So you need to know the position of this point in the range [i..N] (that is why I used RMQ here).
Now for each point I update the answer with the minumum(distance to last point before, distance to the leftmost point in the range[i..N]).
Sorry for my poor english. I hope this helps you.
a super better code for A. https://ideone.com/Q5i7z6
Is it your idea?
yes! why?
Could you, please, explain it?
first if we are dialing a number, we make it mark true; then we check that if we have at least 2 number,1 in row up(1,2,3) and 1 down(7,9); then we check that if we have at least 2 number,1 in column right(1,4,7), and 1 in column left(3,6,9); if both our checks are true then no number can be made by directions like this,because this number is using the 3*3 up square so U can not shift the directions. and if U have any of(1,2,3) and 0 then U have a direction with length 4 and again U cannot shift the directions any way; i hope i have explained it good; sorry for bad English.
I have a doubt. Why are you checking against (7,9) and not (7,8,9)? Does this make any difference? Your logic is great by the way! :)
tnx:)
Explanation for A, If the given string (configuration) touches all four sides of keyboard, then answer will be "YES", else "NO". Upper side contains 1,2,3 , left: 1,4,7,0 , right: 3,6,9,0 , lower:7,0,9.
link : 18922768
what's the intended complexity for D? is O(n log(n) * log (n)) passable within the time. my program (which is O(n * log(n) * log(n))) fails in the 7th case :(
My solution run in ~250 ms,try maybe to use scanf.
solution run in ~250 ms,try maybe to use scanf.
I always use scanf for such huge inputs. maybe too much constant factor there
Yep I'm also having the same concern. I came up with an solution during the contest but its worst-case performance was ~2500 ms and gets TLE on pretest 7. That was driving me crazy. I tried getchar-based I/O and even function pointers (to digtinguish between min/max cases) but neither helped... Appears that the constant factor in my implementation is too large.
solution during the contest but its worst-case performance was ~2500 ms and gets TLE on pretest 7. That was driving me crazy. I tried getchar-based I/O and even function pointers (to digtinguish between min/max cases) but neither helped... Appears that the constant factor in my implementation is too large.
I totally forgot about sparse table RMQs during the contest... T^T Segment trees seem to consume really a lot more time than that, both when coding and running.
I had this problem too, but then i realized that ANS can be more than 1e+9. Got AC, now. And there can be TL because of you trying to get_ans separately (max/min) if you'll get it in one time. Sory for my english, code will show it better https://ideone.com/aRj0ti
Ah... Thanks for pointing out, I didn't even realize I could do that! _(:з」∠)_ And sparse tables can also be optimized in this way, if I got it right?
i think Sparce table can't get TL, because it works too fast :). So it is no need to optimize it by this way. It's all about constant factor in Segment Tree :/
Sparse table works O(1) per query, so I think there is no need to optimise it :D
thanks a lot
i got AC by querying (max(F,l,r),min(G,l,r)) at the same time
Thank you,I changed my segment tree to do exactly what you said!
Aha, I meet this occation too. And I put Update1 and Update2 together , then I get AC. Sorry for my sorry English.
I also use a o(nlogn^2) solution, binary search and segment tree. Luckily I passed case 7 in 1965ms but tle in case 61. Then I replaced __int64 with int in binary search and get accepeted. It's interesting that I passed case 62 in 1996ms~ But later again I submit my solution, it tle again QWQ.
Еverything depends on the phase of the moon.
Guys, as i understand, there are no solution for python 3 for task C? Maybe it is good to separate time limits for different languages? Does system have such possibility?
My python solution for A: here...
More pythonic:
Wow, I like the way binary search is implemented! Looks really neat!
Can anyone please explain the solution idea for problem D ? I have read the editorial but I can't get the idea :(
I do the following.
You will calculate the answer for each segment that starts in position L. So, you need to count how many positions i are that max(A[L],A[L+1],... A[i-1],A[i]) = min(B[L],B[L+1],... B[i-1],B[i])
Now, the key observation is that the function max doesn't decrease. Similarly, function min doesn't increase. If you draw both functions would be something like:
(-) is the min function.
(*) is the max function.
(+) is when both functions have the same value (what you are looking for).
Looking the drawing(imagine is a good drawing) you notice that the difference between min function and max function doesn't increase. First is positive, maybe at some moment it is zero and then will be negative.
So, you need to search in wich position (if exist) the diference between both functions is 0. I did two binary search, one for the last position where min(L,i)>max(L,i) andthe other for the first position where min(L,j)<max(L,j). if j>i+1 then there exist j-i-1 positions where both functions are the same.
You have to repeat this for each starting position L. Complexity is O(NlogN)
A typo :- Function max doesn't increase(decrease)
Sorry, fixed
Shouldn't it be O(n * logn * logn) as u have to query seg tree for min/max each bin search
make a sparse table . sparse build is O(nlogn) and query as O(1)
ok ! Tried it with seg trees in java TLE on test 7
It says it's O(logn).
it's funny that problem A has longer code than B,C,D,E!!
A lot of people solved it with codes similiar to mine: http://mirror.codeforces.com/contest/689/submission/18922407
What is wrong with my solution of Div2B: My solution
You are not considering back edges, that is, start to end and end to start.
Consider this case -
8
5 2 3 8 5 6 7 8
Correct answer is -
0 1 2 2 1 2 3 3
Also a[1000 * 1000] should be a[2000 * 1000+5]
Also, its O(N^2) and will give TLE
The problem states that a is a non-decreasing sequence...
Yes, right!
Correct example would be -
10
5 5 5 8 10 10 10 10 10 10
Here distance from 1 to 8 should be 3. The edge 5-> 4 should be considered.
Can anyone explain the first two approaches/codes for problem A ?
If the given string (configuration) touches all four sides of keyboard, then answer will be "YES", else "NO". Upper side contains 1,2,3 , left: 1,4,7,0 , right: 3,6,9,0 , lower:7,0,9.
link : 18922768
I have idea of BONUS D : with one element X of array a[] I find how many times this element is max of subsequence(define cntA[X]) and with one element X of array b[] I find how many times this element is min of subsequence (define cntB[X]) (use map to store cntA[] and cntB[]) Ans of problem is product of all (cntA[X] * cntB[X]); To find cntA[] (max of subsequence is the max value of subsequence and min index) let left[i] is the first element so that a[left[i]] >= a[i] and left[i] < i; right[i] is the first element so that a[right[i]] > a[i] and right[i] < i; cntA[a[i]] += right[i] — left[i] — 1; same with cntB[]
This has to be one of the hardest div2 contest I have ever seen... My first thought on problem B was like :"Nah it's just a Div2B, it can't be dfs/bfs related...", and there goes a bunch of time trying out a few naive approaches.
Problem D was pretty awesome, when I learnt data structures my underestimated Sparse Table and thought "Huh if it is static I would rather use a prefix array, and if it has updates I would use segment tree." What a back stab! Thankfully it wasn't that hard to learn at all after understanding BIT and segment tree.
I don't think div2A is too hard though, all you need is to make the observation that you can't slide the order of input as long as the input contains all four side of the boarders, it's not that straight forward but definitely not hard. In fact, I think it is pretty decent as div2A problems are getting more and more similar to each other.
Edit: Oh snap, just read the problem D editorial, dang it I done my research on Sparse table before coming up with the observation of binary search is again applicable in this problem... X_X
I think I have missed something huge in problem E... I am using the partial sum approach to keep the amount of points within a certain length of segment, but I somehow got tripped over by test 13.
http://mirror.codeforces.com/contest/689/submission/18942895
UPD: Heil long double.... AND PRAISE MODULAR INVERSE FUNCTION WHICH I'VE TOTALLY FORGOT
I also got wrong answer in test 13. Can you explain why we use modular inverse function?
oh, I misread D and came up with a complicated solution to find the count of max(a) == max(b)...
My solution for A http://mirror.codeforces.com/contest/689/submission/18930613. I check if i cant move all the digits to all the direction then it's a "YES".
http://mirror.codeforces.com/contest/689/submission/18956712
``
It's O(N^2).
hello friends can anybody help me in div2B in pointing out the mistake, i start visiting all the intersections from a node and update their distance(do this initially for 1) and also insert them all in a set and then for all other n's i just iterate over them and find their upper bound and lower bound and take its minimum distance and then do the same process as above. here's my code http://mirror.codeforces.com/contest/689/submission/18938871, although i am getting a wrong answer but i cannot figure out where
Try this
Your algorithm first visits 1 and goes to 5, and then goes to 6, then 7, ... until finally reaching 2 from 10. After that when
if (d[x]) return;is executed the program misses the fact that 2 can actually be reached within fewer steps.The order you visit points is not guaranteed to be correct, that is, when you visit a point and use it to update other points' information, you are not sure that the info on current point is fully determined (will not be updated in the future), which may lead to some incorrect answers. To ensure this you will need BFS in this problem's case, and Dijkstra's algorithm when dealing with a graph whose edge weights are not all 1. These approaches use a vertex's information to update others' only when they're sure the optimal answer for it has been fully determined.
Thank you for the reply but how can the input be 5 1 1 ..... , it should be in increasing order only according to the question and my answer is going wrong at 75th position, can you please recheck, thank you
Oh sorry that was such a careless mistake T^T I completely misunderstood the case. My apologies...
Your algorithm is mostly correct with a few errors. Firstly I suppose you're using
if (d[x] && d[x] <= v) return;and I know you can figure out why :)Let's directly observe test #4. The problem is with the 87th point — the program gets to 53 within 6 steps with the help of shortcuts, and goes through another shortcut to reach 87, with 7 steps taken. However there exists another solution: use shortcuts to get to 90 within 3 steps and then go back to 87 — that's only 6 steps!
What's wrong here is, when we iterate to 87,
if (*vis.lower_bound(i) == i) continue;ignores it, leaving the chances to be reached from some neighbouring points (in this case, 90). After removing this statement, you should also carefully handle cases wherevis.lower_bound(i) == vis.begin(), which could cause range overflows when applying the--operator.However the quickest and safest way to handle such shortest-route problems is doing a BFS. Hoping to be helpful this time (。・ω・) Correct me if I made some mistake again
How to find out the possible upper limit of n in Div.2 C? Trial and error?
You can use 1e18 as upper limit. It will pass all test cases. Or you can calculate answer for 1e15 (using upper limit 1e18). It will be upper limit.
Check the comment nagibator2005 above
What's the idea behind test 11 in D? My code can't pass it and I can't find the test it doesn't work on. Link: http://mirror.codeforces.com/contest/689/submission/18949949
In div 2 C — "how many a satisfy the conditions 0 < a < ak < ak^2 < ak^3 ≤ n, their number is floor(n/(K^3) )...how ?
For a particular k the max possible ak^3 to be stored in bag n is the greatest value of ak^3<=n
So no. of ways = a = n/(k^3)
Take eg n = 64 for k=2 values of a which satisfy are 1,2,3,4,5,6,7,8 count = 8 = (64/(2^3)) = (n/(k^3)) for k = 3 values of a which satisfy are 1(27),2(54) count = 2 = (64/(3^3)) = (n/(k^3))
Above brackets are floor since int. divison
For some strange reason, my submission to B with Dijkstra is faster than the submission using a BFS
I am not getting Prob D explaination. We binary search to find rmax and rmin for fixed l which satisfy the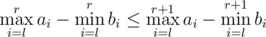 Or which should satisfy max ai — min ai
Or which should satisfy max ai — min ai
See my submission, I am getting WA at test case 3.
you know the inequality for sure because min is decreasing and max is increasing,consider function fl(r) = max a[l..r] - min b[l..r] then fl(r) ≤ fl(r + 1) so you can binary search to find rmin which is the minimal number such that fl(rmin) = 0 and rmax is the maximal number such that fl(rmax) = 0 then for each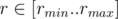 fl(r) = 0 so add to answer rmax - rmin + 1,be attentive with case when there doesn't exist any r for which fl(r) = 0.
fl(r) = 0 so add to answer rmax - rmin + 1,be attentive with case when there doesn't exist any r for which fl(r) = 0.
Can anyone explain how this code for problem D works? (Credits to szawinis)
It looks like he did something with a monotonic queue, or related.
If you want to understand this code first of all you need to understand how does a deque works.
Or here(read method 3)
In problem D I wonder what is the solution if both of them can tell only the maximum value?
My solution can solve it as well.
Assuming the number T appears in both sequence A and B, In A it covers ranges [la1,ra1],[la2,ra2]...(in every range T is the maximum) In B it covers ranges [lb1,rb1],[lb2,rb2]...(in every range T is the minimum) Set A consists of the former ranges, Set B consists of the latter ones.
If we take a look at the sub-ranges in A∩B, all the answers sharing the number T are included, and some don't share the same maximum/minimum,too. Then we exclude them.
Define F(A,B)=the numbers of sub-ranges in A∩B, let set ^A consist of all the ranges[la1,ra1],[la2,ra2]...excluding the position which has the value T.
Then employ the Inclusion-Exclusion Principle, the answer of same ranges sharing same maximum/minimum is F(A,B)-F(A,^B)-F(^A,B)+F(^A,^B)
Since for every value T,the number of its ranges in both A and B is O(its appear times), the total calculation can be done in O(N).
PS: Applogize for my imprecise description, you may as well view my code. In that I have just started to use C++ and there is much inherited from Pascal, it may not look great. :D
Can bonus of B be solvable by FLOYD warshal ? I think complexity is huge for this constraint O(N^3) => O((2x10^5)^3 ) => O(8x10^15) ? So what is the another approach ?
I think, segment tree + LCA would be enough?
** I meant to ask this as a question. Sorry for my bad English.
Please, describe your approach or stop throwing random guesses.
Why so difficult solution for A?
It could be done easier:
- (can up) all of "123" cells are free -> NO
- (can left) all of "1470" cells are free -> NO
- (can right) all of "3690" cells are free -> NO
- (can down) all of "709" cells are free -> NO
- otherwise -> YES
First solution that came to my mind and i think the safest one,whithout any cases.
how to solve bonus B and bonus D?
Can problem D simply iterate and compare A[i] == B[i], A[j] == B[j], and max(A[i], A[j]) == min(B[i], B[j]) when j = 1, i = j — 1?
I desperately wanna know why the above solution ends up with the wrong answer on hidden test cases.
wrong answer on hidden test cases.
wat?
What I meant was above method turns out wrong when submitted on test case #5
You can see all tests by just clicking on your submission.
What if all elements are equal?
See test:
3
1 1 1
1 1 1
You output 5 but the answer is 6: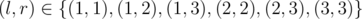 .
.
Solution for E: line sweep. For each point, if there's d intervals containing it, add Ck(d, k) to solution. 19035768
Can problem B be solved using Dynamic Programming??
see C++ with deque.
Could anyone explain O(n) solution for 689D - Friends and Subsequences?
How to solve problem E bonus? I thought of the following:
Let's have F'(x) = answer for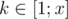 . Then obviously our answer will be F'(R) - F'(L - 1). But here comes the problem on how to count
. Then obviously our answer will be F'(R) - F'(L - 1). But here comes the problem on how to count 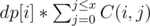 for every i. Can you please explain the official solution to the bonus (I_Love_Tina, ThatMathGuy).
for every i. Can you please explain the official solution to the bonus (I_Love_Tina, ThatMathGuy).
my first program of problem D is the bonus...hahaha. I misunderstand the problem, and then solve the bonus...