


Hello Codeforces,
FHC 2017 Round 2 will take place soon: Jan 21, 2017 10:00 AM PST
The contest will last 3 hours. Time penalty counts!
Top 200 will advance to Round 3.
Top 500 will get T-shirts!
I will post the contest link here closer to the start time.
Good luck everyone.
UPD: contest link






Contest starts at 1 am here. RIP ranking :(
Contest starts 2am here, I am happy even if I can only get a t-shirt.
Contest starts at 3am here. Is there anybody from east Australia, east Russia, or New Zealand?
Hello, I enjoyed my 5am morning in Australia.
It begin at Jan 21, not Jan 20. You almost give me a heart attack, I think I miss the round :p
Oh sorry for scaring you. Fixed the date.
Contest Link : https://www.facebook.com/hackercup/round/742957399195355/
Just so everyone knows, if you go to https://www.facebook.com/hackercup/round/ you will end up at the next round's page.
How hard is it to win a TShirt? This is my first HackerCup. I could score only 35 in round 1 :(
this is my first round 2 as well! (Previous year I failed round 1).
considering a heavy participation(from entire world) I think getting into top 500 is difficult for a blue rated programmer like me!
About 2400 people qualified for Round 2, and I would guess that fewer than 2000 will compete. So you'll need to be in the top 25% or so. Good luck!
I'm in a really weird situation. I have a solution for C, which gives expected answers on the first 4 samples, but a different one on the last sample; the same happens for a bruteforce. I've read the code and the problem about a million times and can't see anything wrong. Since tests are generated, the samples are quite strong, but making any tests I want is... hard.
I don't see any better strategy than giving up.
I know it's not a good practice to discuss questions of ongoing rounds, but damn... I have been sitting in front of my monitor for 45 minutes and I still can't understand the statement.
Literally me after understanding the statement.
I had same experience but with B :|
I spent > 1.5 hours writing both good solution + brute force for B. Both gave same result and wrong on last 2 tests. After reading code 1000 times I switched to A + C.
I had the exactly same problem. I spent my last 1.5 hours on B even though I had the idea for D, but it initially thought the code would be easier. B was really annoying... C and D though
What was C's solution?
My failed solution was n logn^2, using segment tree, that we can merge 2 ranges [l1, r1] and [l2, r2] as
ans[l1, r2] = ans[l1, r1] * ans[l2, r2] + ans[l1, r1 — 1] * ans[l2 + 1, r2] * M[r1][front] * M[l2][back],
where M stores number of mappings uptil now in that given direction, with base case as ans[x, x] = M[x][same]
You can solve it in NlogN with a segtree storing the following information:
Answer , Answer without last element , Answer without first element , Answer without first as well as last element.
This is my solution: http://ideone.com/Wdrr2g
Though untested, since I could not debug it on example cases(1 char mistake :( ) — the logic is exactly same to most of accepted solutions — you keep 4 things in segtree nodes, matchings in [l+1,r] in [l+1,r-1], [l,r-1] and [l,r] in [l,r] . just see the merge function its the whole solution..
The key observation is that there're only two ways to match two adjacent pairs: the edges are either parallel or they cross each other (it looks either like two parallel lines or as an X letter).
Let's store
f(is left open, is open right)in each node of the segment tree (it denotes the number of ways to match everything inside the segment so that the state of the left and the right border corresponds to the boolean parameters (it's true if and only if the edge goes across)). We can merge two nodes by iterating over all possible parameters' values for the left and for the right node (in fact, there're 8 valid combinations as the middle ones must match).The time complexity of this solution is
O(N log N).Yeah, could one of you guys share your accepted code, since I implemented the same idea, got WA, logN times higher complexity though.
My solution.
By the way, you can download everyone's code by clicking the source link in the scoreboard.
Please somebody in 30 minutes explain what was the catch with problem B, where I am absolutely sure that my solution for test example 4 is correct (I even had enough time to draw the picture) and the number is smaller then official answer (they are asking for minimum, so). I tried to do it with two different methods (including brute force) and got same answer. Must be something in problem statement which is not obvious, but I did read it many many times...
I resign at this point. After competitions ends I can post my answer to example 4.
Did you just say "brute force" for a problem with geometric statement? How?
Aren't all angles were 45 degrees if you wanted to achieve minimal cross section? Meaning from every pole it was going down at 45 degrees both left and right unless some other pole prevented it from happening?
I just multiplied height and position by 2 and did everything even in integer numbers.
Are there cases where something else then 45 degrees gives optimal solution? if this is the case then this must be my error in understanding the problem statement.
Indeed, it's always 45 degrees. Do you check that the height of the tent is always non-negative?
It's more like data structures, and not really a geometry :)
Don't know about zholnin, but I simply split each 1x1 cell in 4 parts by 2 diagonals, and after that putting a pole is equal to labeling some of these triangles as used.
Aren't you forgetting to add current area to the answer when it doesn't increase? Cause that's what happened to me on test 4 and it took more than 30 minutes to find.
It would be very helpful if you can give me current area + sum of current areas after each pole. I have this:
And this is the answer at the bottom.
You have exact same result as me. And my reason was because of what Vercingetorix said.
Note that you print only 9 lines while N = 13.
Yeah, it was very stupid. I see now. There should be 13 lines in my output not 9.
Seems like Vercingetorix was right
Fighting all the Zombies is similar to http://mirror.codeforces.com/contest/573/problem/D.
I also noticed that :D
Now that it is over, what was the solution for Q1 ? Couldn't find a pattern.
these are the only possible cases , also swap n , m once and try it once again
I had the same idea but I only used (n,m) as (max, min) ... Now I think about it that was very stupid.
Placed 500th, what a luck.
What can be more awesome than passing all samples on B and it output negative numbers in all the test cases !
Got the same but managed to debug it in 4 minutes and finally grab my AC.
Spending all 3 hours on the last problem is the best strategy, isn't it?
Indeed, was 15 minutes before being able to finish D (though maybe simpler solutions exist).
I wrote naive solution in problem B to stress test my solution and it generated all answers in 4 minutes. Very weak tests again.
The testdata of pC does not include the case "n = 1". I believe somebody would fail on that. Hope that round 3 would have stronger testdata :P
Lucky you, my naive solution for B worked for around 8 minutes, mind sending me your T-shirt? :D
Also, I think problem A required way too much rigorous drawing on paper and too many if-elses even though some people came up with somewhat concise solutions. I didn't like it at all.
Just 1 char change in problem 3 code and could have been selected to next round :( — Was initializing all matchings in segtree nodes to 1, while half matching should be 0...
I also initialised all matchings to 1 and failed system tests but can't find any error.
What is half matching? Did you pass the pretests?
I could not debug it on example cases — had 10 minutes left when i started to debug it the hard way. you keep matchings in [l+1,r], [l,r-1], [l+1,r-1], and [l,r]. Base cases of all others are 1 except [l+1,r-1] — its 0. Code — http://ideone.com/Wdrr2g
Edit — It matches the input/output with accepted solutions :(
I don't like problems like A in important contests without full feedback. It make things more random. Or maybe were we expected to write some exponential solution to check the correctness?
Problems B and C were so boring IMO, they're only about the implementation. It's sad that those problems were most important for choosing who passes.
Though, I liked the last problem.
I disagree with you on D. A very routine problem with all the standard algebra tricks rather than clever algorithmic insight. Probably would favor someone with strong arithmetic library.
That being said, C is quite an interesting problem if you haven't seen it before.
Finding the area of building and clouds were standard for me but I couldn't find a way to compute the area of water, at least during the contest — this is why I liked it. Maybe I missed something and it's standard indeed.
For me C was yet another segment tree problem with complicated merging. It's so known that I used a similar problem on a CF round before (573D - Bear and Cavalry), but that one required some thinking first and otherwise I likely wouldn't use it at all.
Well, If I say that area of water is (area of cells below cloud) — (area of grey cells below cloud), will it make it standard?
I made this observation in first seconds and assumed that I must use it. Still, I couldn't find the sum of grey area under clouds.
After reading your comments, I just figured out that water area = total area — all other areas.
Never mind, it doesn't help)
It's interesting to see how different people find different observation difficult. I didn't see this fact for a long time, but after I understood it, I understood everything.
Anyway sketch of what I did:
index — position of highest tower
h — its height
l — start of segment(inclusively)
r — end of segment(exclusively)
L = index - l
R = r - index - 1
First of all there's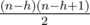 ways to choose rows for it, will multiply everything by it.
ways to choose rows for it, will multiply everything by it.
Tower at position x will be counted (L + 1)(R + 1) times, so adds H(L + 1)(R + 1) to answer
Let's check how much will tower at position l ≤ x < index give. It's hx(R + 1)(x - l + 1) (we choose left border to the left of x and right border to the right of index). We need to sum that for all x from l to index and we need only prefixsums for hx and for hx·x
Okay, here's my take for D. I will only focus on calculating the blue parts, please comment if you prefer a complete solution.
Let W[i] = n - H[i] be the number of non grey squares on column i.
Let L[i] be the smallest index such that W[x] > W[i] for L[i] ≤ x ≤ i, and let R[i] be the largest index such that W[x] ≥ W[i] for i ≤ x ≤ R[i].
Fix an index i and let L = L[i], R = R[i], W = W[i], the blue part corresponding to column i is equal to
(there are w ways choosing a rectangle that leaves only S[k] - w blue squares remaining)
Collecting the term associated with w we get
. so it suffices to calculate the sum
. The trick here is to split the range of k into $L \le k \le i - 1$ and i ≤ k ≤ R. On L ≤ k ≤ i - 1, the coefficient associated with S[k] is (R - i + 1) × (k - i + 1), so it suffices to precompute the prefix sum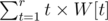 . On i ≤ k ≤ R, the coefficient associated with S[k] is (i - L + 1) × (R - k + 1), so it suffices to precompute the suffix sum
. On i ≤ k ≤ R, the coefficient associated with S[k] is (i - L + 1) × (R - k + 1), so it suffices to precompute the suffix sum 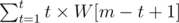 . The rest is algebraic manipulation.
. The rest is algebraic manipulation.
Was merging in C complicated? If we model each node as an 2x2 matrix, the problem just boils down to matrix update / matrix product calculation. There was nothing to implement besides segment tree (which is easy)
I think figuring out a right model was the only important thing in problem C, and that's why I liked that problem. I didn't knew your problem, so I also found it fresh. but seems like I'm wrong for it..
I agree to your point about the rest of the problems. For D, I thought it was simply too tedious, but I couldn't solve it anyway and some might disagree for it..
That awkward moment when somebody says "B and C are just a boring implementation" and I have spend like 50 minutes trying to figure out how the hell that problem B should be solved before coming up with something meaningful :)
I completely agree with your point of view on A, now I'm even surprised that it doesn't contain some more tricky cases — during a round it was "let's submit it, in case there are some tricky cases I'll not find them anyway" for me. And prior to that it was "this is what I have to solve for 12 points, I don't even want to think what to expect from other problems".
I'd put it this way: "without full feedback" plus "time penalty" is relatively bad. Remove one and you get either old-fashioned IOI or ACM ICPC.
The quality of problems was pretty bad in my opinion.
Problem A is OK if you can get the feedback like in ACM ICPC style, otherwise it is just about luck B and C were just so standard and implementation heavy that I don't really want to compete anymore
I understand that this is early qualification round and they don't waste good problems but for example, Google Code Jam has much better problems at this stage.
We wrote the same thing and posted it in the same minute. Nice.
Yeah looks like one of us wasted time :)
At least I saved some time by not competing in the last hour.
I got an achievement: "For two years in a row in R2 submit a source code that produces correct answer in short time, but somehow still submit wrong output".
Last year it was in most important problem and costed me qualifying to R3, however luckily this year it was in easiest problem, so it didn't cause a big harm. Last year my mistake was pretty pathetic, but I can't explain what happened this year. Maybe I didn't compile code after changing it or whatever, no idea.
Failed the 3rd one since the tests were so that it didn't touch one of the combination cases.
At least I learned that even if it's a big and random test, it might still be an evil random test :(.
How to solve B properly?
Does anyone have a proof for A? I've spent one and a half hours before giving up. It's so frustrating.
Honestly I didn't like the problems but at least Let's hope the tshirt color will be better than the last two years :P
Can you share pictures of last two years' t-shirts?
The red one is 2014's and the other is 2015's. The 2016's one had the same design but the color was pale grey. The worst thing is the writings on the back they write lots of stuff with large fonts.
The most awkward thing about their last year T-Shirts is that their color scheme is almost 'white text on the white background". After a few washes, the background and the text become indistinguishable :)
I also hope there won't be
print "Hello, world!"...This is on codejam tshirt :P FBHC writes something like "Code fast and win things" with a link to their facebook page on the tshirt -_-
In problem B, if I have pole of height 10 at 0 and pole of height 3 at 100. Suggested solution is iterating all and adding areas — 100 + 109 = 209. But it's not optimal, optimal is 9 + 109 + 118. What am I missing?
You don't get to choose the order. The poles appear one by one in the order in which they are given in the input.
Yep, thanks for confirmation.
Should we have received a t-shirt by now or have they not been sent out?
anybody got their t-shirts yet?