


Всем привет!
Я рад объявить о том, что сегодня в 19:30 MSKсостоится Codeforces Round #138. Автором этого раунда являюсь я (Василий Вадимов). Это мой первый раунд на Codeforces, до этого я лишь помогал другим авторам в подготовке их раундов.
Раунд мне помогал готовить Геральд Gerald Агапов, а условия задач перевела Мария Delinur Белова, за что им большое спасибо. Также я благодарен создателю Codeforces Михаилу MikeMirzayanov Мирзаянову за отличную платформу для проведения соревнований.
Успехов на раунде! Надеюсь, задачи будут для вас интересными.
Разбалловка в обоих дивизионах стандартная (500-1000-1500-2000-2500).
UPD. Внимание! Язык D, который находится на этапе внедрения на Codeforces, на этом контесте не будет доступен.
UPD2. Раунд завершен, топ-5 по в каждом из дивизионов:
Div1:
Div2:
Поздравляем победителей!
Также приношу извинения за неточность в условии в задаче div1 A/div2 C. Разбор будет опубликован завтра.
UPD3. Доступен разбор задач.







Good luck and having fun to all!!! I hope, that problemset will be interesting.
в "обОих" дивизионах же)
Провал. Спасибо, пофиксил.
Сообщение перенесено чуть ниже.
http://nagradite.bg/vote/HekpoMaH-47464.html
Кстати, уж простите за оффтоп. Меня вот интересует вопрос целесообразности этого:
А как много пользователей не нажимают на "здесь", чтобы посмотреть, что же там всё же заминусовано? =) Может, стоит просто засветлять сообщение? Единственная причина, по которой мне может видеться полезным такой подход, -- огромные картинки и/или стены мусорного текста, но тогда хорошо бы сделать ссылочку, чтобы прятать их обратно.
На хабре, к слову, это сделано гораздо юзабельнее, лично по мне. Блеклость текста не мешает его читаемости, в отличие от полного его скрытия.
а зачем вообще затемнять коммент?
Чтоб знать, что минусовать.
Когда ветки огромные или over9000 сообщений я читаю либо комменты с "+20", либо скрытые.
Иногда нажимаю, иногда нет. Вообще, нравится эта штука со скрытием. Не понимаю, в чём проблема.
Спорим, задачи сегодня будут на анимешную тематику? =)
Это было бы круто :)
Ну, зная Васю... ^__^
Эм...У меня тут вопрос есть...Это не вы в ушах таких сидели рядом с нами на ВКОШПе?
Нет, на последнем ВКОШПе я был с бубном.
Я знаю, что на ВКОШПЕ в ушах сидел G_gekko :)
И в самом деле не угадал. Эх, Вася, что же ты меня так подводишь?
Waiting for interesting and useful Contest.
Сижу и жду когда начнется этот раунд , так как я продолжительное время не участвовал на раундах Codeforces , а значит для меня этот раунд очень важный.Всем желаю успехов !!!
What do you mean by "D language will not be available on this contest". Is there no translation of the problem D?
No This mean the D programming language is not available
No, it means that you cannot submit solutions written in D programming language. See http://en.wikipedia.org/wiki/D_(programming_language)
Давайте все-таки поговорим о разбалловках. Я не понимаю, почему авторов раундов не устраивает динамическая разбалловка. А ошибки в определении сложности задач случаются регулярно. Почему бы не перестать противиться прогрессу?
<IMHO>
Потому что прогресс, предлагаемый нам динамической разбалловкой от CF — это что-то странное. Когда один сабмит может перемешать таблицу, размазав бывший топ-10 по первым трём страницам, это неправильно. В этом отношении, например, система CPR, гораздо лучше.
</IMHO>
Слишком IMHO. Таблица результатов на момент времени на то и на момент времени.
Причём здесь момент времени? Плохо что функция place(numA, numB, ... numE), выражающая зависимость твоего места при фиксированных твоих результатаъ от количества решивших каждую задачу людей настолько негладка рядом с точками, в которых происходит переход.
А по-вашему динамическое определение стоимости задач никогда не ошибается? В динамической стоимости задач нет прогресса, лишь замена одних проблем другими. Мне вот намного больше нравится знать сколько баллов я получу за задачу, чем играть в "угадайку". В динамической разбалловке можно только гадать скольким еще людям понравилась эта же задача и не обвалят ли они ее стоимость до 500-ки, несмотря на то, что она не такая уж и простая.
В смысле, тред о том, почему бы и не совместить динамическую разбалловку с сортировкой по предлагаемому уровню сложности.
Но это же просто возьмет и уберет подобные проблемы. И "угадайку" уберет, и баллы адекватные задачам.
Куда это уберет угадайку? Есть две примерно одинаковые задачи. Видно что одна успеется любая, две не успеваются. Откуда узнать какая их них будет больше стоить? Стоимость сейчас, не зная насколько сильные претесты по большому счету может не давать информации вообще. На самом деле эта же проблема была бы, и при непрерывно меняющейся стоимости, но там она меньше ощущается.
about problem C:
what is the answer of ((()))? should be 0
or 0 ((()))
?
I think any of them would be ok.
So you can print any proper subsequence, including empty. Anyway, do not ask questions about problems during the contest here, for this purpose there is "Questions about problems".
Исправление за 2 минуты до конца раунда — такого я еще никогда не видел...
Не в обиду автору, знаю что контест сложно готовить.
Очень очень очень не понравлися этот контест.
Как C решать?
ans[i, k] = ans[i - 1, k] + ans[i, k - 1];
Получаем цэшки с каким-то коэффициэнтами. n небольшое, посчитали.
Ой. Что-то у меня слишком сложно. Я сказал, что это почти домножение на многочлен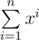 . Его возвели в степень за n^2log. Вроде 1.8 на макстесте.
. Его возвели в степень за n^2log. Вроде 1.8 на макстесте.
Количество вхождений элемента исходного массива i в элемент итогового массива j C(k + (j - i), j - i) Тогда нам нужно всего n цешек, каждая из которых пересчитывается из предыдущей. Потом переберем пару элемент исходного — элемент итогового и добавим к элементу итогового элемент исходного, домноженный на нужную цешку.
Очень похожая задача на TC: условие, разбор.
Классные задачи!!! Спасибо, I_love_Nastya.
Сколько, вы говорите, зачтённых решений по D и E? Ноль? Такого я ещё не видел.
Имхо, в D условие, что нельзя выползать наружу — лишнее, задача и так сложна, а разбор того, торчит ли вертикальный вектор из вершины внутрь или наружу меня добил(
А в целом задачи понравились.
А как решать без этого условия? Оно было добавлено чтобы спасти эту задачу и не придумывать новую, без него я не умею решать быстро.
Решение: прошлись сканлайном с сетом отрезков. На каждом x взяли все вершины (+начало+конец) и провели по отрезку вверх и вниз. Получили новые вершины (их линия), построили на них понятно какой граф с линией рёбер, пустили Дейкстру.
Если разрешить выход за границу, то может стать выгодно идти не до ближайшего пересечения вертикальной прямой с границей, а до какого-нибудь еще. Поэтому новых вершин квадрат.
Ну поменьше вершин сделать, например. Всё равно сложность в реализации, а не в идее. А в текущей версии — после 300 строк кода хочется повеситься.
Я умер после 250ой. Правда, я совсем по-другому делал. Я посортировал вершины по y. Теперь делаю две итерации: в первой узнаю первый отрезок выше ее, во второй — ниже. Разберу, как делать первый вариант: ну, понятно, сразу убьемся, если вектор, идущий наверх, выходит из многоугольника. После этого давайте посмотрим на текущую вершину v. У нее есть два соседа. рассмотрим левого (там всегда один будет левым, а другой — правым, т.к. оба не могут идти строго вниз, и ни один сосед не может идти вверх — зачем паутину пускать?). Теперь посмотрим на левого (с правым то же самое). Давайте найдем первую вершину, x-координата которой будет >= v.x, при рассмотрении вершин в порядке обхода (т.е. порядок такой: v, левый сосед v, сосед соседа v...) Это делается бинпоиском по количеству соседей и нахождением за логарифм максимального x, среди подряд идущих вершин в обходе (пилится деревом отрезков). Вот такое я придумал:)
Начал писать про сканлайн, сет ребер, дейкстру и т.д... подумал... да, беру свои слова назад, без этого условия число ребер, которые надо добавить в граф получается квадратичным.
Геометрец... Жесть.
И на чём же сегодня надо было ломать? Я проглядел, по-моему, все решения в своей комнате, но так ни одного взлома и не нашёл :-(
Везёт :) Я вот каждое второе решение по A в своей комнате хотел сломать. Правда, почему-то взломы были не очень удачные — что-то я совсем разучился читать говнокод с бредовыми хаками :(
Надо было ломать мою B! Она падает на тесте "abcacba abcba", но претесты проходит. Но никто не ломал :( (Думаю, не у меня одной такие ошибки.)
noooooooooooooo
И у меня падает :-( Вроде 33 тест — из это оперы.
я надеюсь, ответ Yes (вроде среднюю буквку 'a' нельзя покрыть)
ответ noooooooooo.
Задачи интересные, но контест несбалансированный. На мой взгляд, мы сегодня увидели B, B, B/C, F, F. Серьёзно, что-то не так когда ни tourist , ни Petr за полтора часа ничего даже не засабмитили в D и E.
да, будем называть вещи своими именами — контест убойный, кст у меня сложилась такая же оценка задач... А явно стоит 1000, да и С не слишком сложна для С
взломал десятерых на тесте, на котором падает моё решение)
Not important, hidden.
I asked about this. They said: "Not important".
Problem E was great.
I can't comment on E as I had not even read it during the contest, but I actually liked problems
мне одному показались А и B по уровню сложности близкие первым двум задачам на всеросе?
Возможно. А есть табу на задачи близкие по уровню к задачам всероса?
А как решать А?
Стыдно спрашивать, но как делать А? :(
А — слишком идейная для первой задачи в контесте. Там выше правильно подметили, такая задача хорошо идёт на какую-нибудь всероссийскую олимпиаду.
Утверждается, следующее. Пройдёмся стеком по строке как обычно делаем, когда проверяем её на правильность. Если очередная закрывающая подходит, до отрезок от открыващей на вершине до неё — правильная скобочная последовательность, можно срелаксировать ею ответ. Если очередная закрывающая не подходит, очищаем стек.
Только иногда открывающуюся скобку в стеке нужно оставлять от предыдущего захода на этот уровень, иначе на [][] обломаемся, и рассмотрим только 2 отрезка [] и [].
Я что-то сам перестал понимать, как работает моё прошедшее решение. Я не оставляю скобку от предыдущего захода. Мне достаточно после каждого облома принудительно релаксировать ответ и дописать в конец #, чтобы принудительно в конце обломаться.
Забудем про nested последовательности ( [][] ). Тогда будем делать стэк, где запоминаем момент прихода каждой открывающей скобки. Приходит корректная закрывающая, значит если мы зафиксируем закрывающуюся, минимальная открывающаяся, что мы можем получить вот она. Частичными суммами считаем сколько на этом отрезке [] .
Если в какой-то момент обломались, полностью очищаем стэк. Без чётких доказательств, интуитивно кажется, что мы не можем уже для любого конца отрезка правее этого места зайти началом отрезка левее.
А теперь nested. Когда пихаем открывающуюся скобку, если перед этим была закрывающаяся (или самое начало или после крэша стэка), то мы не обновляем левый край этого отрезка, как-бы говоря в случае [ ] [ ], что после обработки третьей скобки на этом уровне парная скобка на самом деле первая. Если перед этим была открывающаяся — то на этом уровне, эта часть обязательно первая.
Сорри, если непонятно объяснил. Ну и не факт что это работает, но похоже на то. :)
я обрабатывал nested попроще в плане понимания. просто каждый раз когда находим подходящую пару скобок — ставим флажки в массиве что эти обе скобки хорошие.
в итоге в конце просто проходимся по массиву флажков, все непрерывно хорошие отрезки, которые больше не увеличить — ПСП. ну потом частичными суммами выбираем самый лучший из них.
Можно сделать то же самое чуть проще в два прохода. Сначала идем со стеком. Когда что-то поматчилось, помечаем в отдельном массиве позиции обеих поматченных скобок как хорошие. Когда обломались, очищаем стек. Потом вторым проходом находим самый длинный подотрезок, состоящий только из хороших позиций.
У меня вроде простое решение. Давайте посчитаем такую динамику: пусть мы начинаем с iой позиции, какая максимальная длина нужной нам последовательности. Чтобы ее посчитать, будем бежать с конца и поддерживать стек закрывающих скобок. Открывающая разбирается так: если стек пуст, заканчиваем рассмотрение. Дальше снимаем со стека скобку. Если она не подходит — заканчиваем рассмотрение. Теперь, мы понимаем, что нашли что-то такое:
(.......)....
обозначим за l, r — позиции скобок. Что делать? Нужно проверить, что внутри этих скобок последовательность правильная, иначе забить (l + 1 + d[l + 1] == r). Если все хорошо, то прибавить к текущей динамике d[r + 1].
написал C, быстро тянусь к кнопке отправить и — "соревнование завершено"! зачем так жить!?
My first hack in Division 1 :)
[[]:DThanks for telling the testcase you hacked me with :D
Can anybody teach me how to solve div2 E? Lucas?
You can calculate how many ai is in aj. So you can find the formula is C(k-1+j-i,j-i) (It is combination number). And you can use C(a+b+1,b+1)=C(a+b,b)*(a+b+1)/(b+1) to get C.
Можно ли где-то получить тесты? Падает B Runtime-error'ом на 20м тесте, но они слишком длинные что поместиться в просмотр сабмита.
UPD: вопрос отменяется, сам понял где зафэйлил, но вообще, не хватает системы посмотреть input'ы, где они большие. Или так задумано?
D and E are too hard hah....sad....
all problem are interesting and hard
Hi friends, I get WA on Test Case 23 and I dont understand what happend. Thanks in advance.
Under "Answer" is the correct answer for the test. Under "Output" is your output. You have no output for that test.
Edit: lol, don't edit your post like that :)
Thanks friend, Now I see this problem.
Div 2, D problem. in test where's |t|>|s| which answer must be?
No, because there is no substrings at all. So no symbol (and there is at least one) is covered.
thanks a lot!
The correct output is No. You can't make the substring. I failed on test 115 that was aa aaa , silly mistake
I failed on the same test, silly mistake.
I spent all the time in the first three problem so that I didn't read the problem D,E.I think they are good problems,thank you!
Прикольная бага с рейтингом) (2 раза зачли тур)
даааа, прикольная
а я подумал почему рейтинг настолько упал :)
А вы специально набирали -250 в раунде для последнего места? Или "Код не читай @ Ломай"?
У меня рейтинг 2 раза обновился, это нормально?
Our ratings have changed 2 times! Admin please fix this error! UPD: I think it's fixed already, thanks :)
Admin, please, dont fix it ;)
Yes, I am DIV 1 now... This must be a mistake (+180 pts) ...
Это, конечно, сильно. Если можно, оставьте так, мне все нравится ;)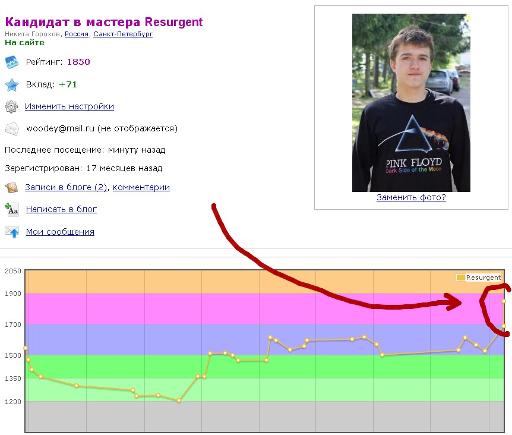
Один из редких контестов, когда Гена не смог решить все задачи
Div 2, problem B. Where is my mistake? id: 2192405.
Convenient to click 2192405
Try this input:
The output should be
3 5, but yours was1 5.Thanks a lot.
Это такой сверхконтест? С удвоенным изменением рейтинга? Идея, конечно, неплохая...
ЭЭЭЭ Почему мой старый рейт вернули
Ура, обновился нормально.
Why has the rating for this round been changed two times?! Someone please fix this!!!
Спасибо за контест!
В дорешивании D зашла со второй попытки (т.е. в версии, которая была готова через 30 секунд после конца контеста был еще (концептуальный) баг — иногда пролетал сквозь финиш :)).
Can someone please help me with problem C div 2, I got WA on test 58 and I can't find my bug. link: Link
Perhaps you are pop()ping too many elements when kt.size()==0? Here's a smaller failing test case:
[[[]]])Nice problems — I liked the contest very much! Probably a bit on the hard end, but still :)
Буду признателен за ответ на вопрос: Если за решение первой задачи получаешь 400 баллов и 3 раза неправильно шлешь задачу номер 3 то общий результат +250 или есть дополнительные коэф?
Количество посылок играет роль только для сданных задач. То есть общий результат останется равным 400.
Еще, кстати, D можно было сделать гораздо более решаемой, сказав, что все x-координаты различны. У меня большая часть кода именно равным посвящена.
Тогда нужно было бы ещё как-то побороться с тем, что 105 точек и координаты до 104 по модулю.
Например, сделать до 2 * 10^4 + 1 точек? Никто бы не помер, наверное
Спасибо за интересный контест!
Thanks for your great contest! The problems were really good and enjoyable. But I have a question: after the contest my rating became 1557 and about 10 minutes later it became 1503! And now it's again 1557. What happend? What was the problem?
http://mirror.codeforces.com/contest/223/submission/2199884 Can someone explain please?
Actually, you output a symbol with code 0 before the string, at least on my system.
It will be better if someone give detail explanation of problem D and E. Please someone help ...
upd. Затупил ужасно, не бейте больно :)
ломать полностью
On div2 C i did so: Found every correct sequence and counted the maximum of ['s a correct sequence have and then saved that sequence. But i got WA on Pretest #9. Maybe i did something wrong in the code, or i don't know, but i find my solution to be ok.
First of all, it would help to write your submission number 2203267 if you want to get any help. Secondly, if you have looked at it yourself, which you should have done, then you would see that on test 9 your output is:
which has 5 [] braces, and the checker tells you exactly that.
Finally, in the following case:
The number of correct non-empty sequences is 1,250,025,000 which is a lot, so I assume that your solution would get TLE even if it's corrected.
Sorry to interrupt, but why the tutorial link leads to a "ru" page?
Because there is no english editorial yet. UPD. Sorry, there it is :)
Could anyone translate the tutorial? I don't understand Russian, google translate sucks and i want know the solutions...
You can change the "ru" into "com", or follow this:http://mirror.codeforces.com/blog/entry/5301
I am having wrong answer in Test 78. The test case is too big and thus got truncated. I have been trying to find the bug for a while now, could someone help? Here's my code.
Your solution produces wrong answer on this test:
Unfortunately, I copied the wrong code. Now it's corrected. Could you please check?