


Attention Hackers! The dates have been set for Facebook Hacker Cup 2013.
Jan 7 — Jan 27 — Registration
Jan 25 — Jan 27 — Online Qualification Round
Feb 2 — Online Elimination Round 1
Feb 9 — Online Elimination Round 2
Feb 16 — Online Elimination Round 3
March 22 -23 — Onsite Finals at Facebook
For more details visit official page.
UPD : Registration is now open for the 2013 Facebook Hacker Cup! If you registered for a previous year, you're automatically registered for this year, but you should check to make sure all of your information is up-to-date. The qualification round begins on January 25th. Good luck!







I wonder if it's possible to submit the output and solution this year.
Take me to the Facebook)
Damn, I hoped this would be contest in who can hack Facebook the best in some manner. :D
Registration is opened.
I wonder if there's a possibility to add problems from past years to CF.Gym for training purpose before the upcoming contest. It's hard enough to find problems itself even to read them so it would be nice if we have an opportunity to read them conveniently. Moreover, maybe somebody saved tests. There was totally 15 problems (1st, 2nd rounds in 2011, 1st, 2nd, 3rd rounds in 2012) worth to solve. I don't count qual problems and problems from onsite finals because obviously there's no opportunity to get tests for them. So, who has problems and tests?
MAybe the problems wrote Anton_Lunyov or dzhulgakov
i have registered for the contest but i am not getting the link for contest arena please some post the link
You'll get the link before the start of the contest
am I allowed to see the problems in hole time between 25 and 27 and submit my solutions whenever I want (between 25 and 27) or there is a timer start when I open the problems when the timer ends I am no longer allowed to submit solution (like USACO)??
You can submit problem only once. You can submit it anytime during competition.
for example if I see the problems in 25 can I download the input file and upload the output in 27?
Yes you can. The only thing is that you have 6 or 8 minutes(dont remember the rigth number) after downloading the input to submit the output
Thank you.
UPD : Ok, misunderstandings.
Good luck.
квалификация уже идет? где можно прочитать задачи
насколько я понимаю... The Qualification Round
то есть нет, еще не идет.
Can anyone explain me how calculate 'penalty' here?
Penalty in Qualification round doesn't matter.
I did not understand,On score board people is sorted by penalty,and it is not matter?,more formally I am interested what I need to advance in the qualification round?
You need to solve one problem.
OK, let's T[i] be the time for solving i-th problem. T[i]=0 if the problem isn't solved. Then S=T[1]+T[2]+T[3]+...+T[n] is your penalty time. People are sorted but it doesn't matter in qual and 1st round. It does matter in 2nd and 3rd rounds.
Anybody got the statement of the last problem? Could you explain one of the samples please?
Reread the statement, it helped me.
Thank you, so much help from the community as I can see. I appreciate this.
I had to reread it too. The first time I read it I didn't notice the part of the statement that is bold and in asterisks :)
Here it is:
John knows the following: for each index i, where k <= i < n, m[i] is the minimum non-negative integer which is *not* contained in the previous *k* values of m.
Does it mean that all values of array beginning with k-th position are equal?
Oh, I got it! Not first but previous k values. Thank you very much!
Is there any age restriction for the participating in online rounds?
Объясните пожалуйста, я должен считать инпут с файла "beautiful_stringstxt.txt", а затем в него же и записать ответ ?
Можно отсылать файл с любым названием, главное чтоб в нем был записан ответ.
Это-то понятно, но к ответу нужно приложить исходный код.
Вопрос в том, откуда этот код должен считывать данные и куда записывать (консоль/файл)?
Этот код выкладывается только для тех, кто возможно захочет его посмотреть, а не чтобы его тестировать. Так что куда хочешь.
Это победа :)
Вы уверены, что там один Петр участвует?
Кстати, не в тему, но табличка просто ужасна. Почему нельзя добавить механизм "друзей"? Я хочу смотреть результаты человека, даже если я не дружу с ним в Фейсбуке. Почему нельзя добавить нормальные ссылки на страницы? По имени сложно определить человека — так я могу хоть щелкнуть на его страницу и посмотреть фамилию. И вообще, эти объявления красным цветом вверху страницы тоже не сказать, чтоб уж очень заметные. Я как раз попался на том, что у меня была установлена та прога, в которой говорится в одном из оповещений, и когда я скачал инпут, у меня скачал файл формата sdx и я немножко испугался. В общем, за 2 года ничего не изменилось в лучшую сторону, кроме приза для первого места, но это улучшение только для таргетов всяких — обычные люди не видят улучшений!
Я точно знаю, какой именно это Петр ;) Инсайдерская информация
Проблема в privacy. Они не хотят, чтобы можно было попасть на страницу человека. С другой стороны, можно было бы хотя бы друзей показывать, кто есть кто, да
Так друзей они показывают.
Да, перепутал
Не кипятись раньше времени :) Вдруг в этот раз они предварительные результаты скажут сразу и ничего не напутают с рассылкой)
Если очень захотеть, то на страницу человека перейти всё-таки можно: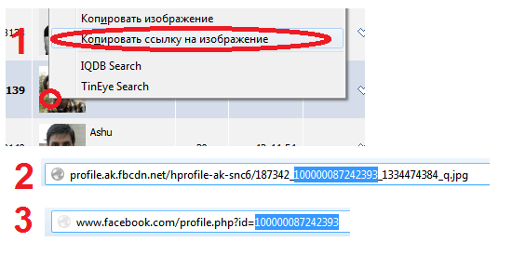
Нужно скопировать ссылку на изображение с его фотографией и взять из ссылки второе справа число — это и будет id человека на фейсбуке.
И потом в ссылку вида www.facebook.com/profile.php?id=10000 вместо 10000 записать нужный id
Осталось только написать скрипт...
А как такие скрипты пишутся? Я бы написал, если бы Вы вкратце сказали, в каком направлении двигаться.
Вроде работает :) http://paste.ubuntu.com/1584924/ Только чтобы перейти по ссылке нужно кликнуть на фото.
UPD: А, нет. Работает только для первой страницы.
Лучше берите селектор по <div class="scoreboard_row"
и в нем первый image
Еще не понятно как находить id тех, у кого нет фото.
Скажите, я правильно понял, что на всё про всё у меня одна попытка, и если я не зашлю свой аутпут за 6 минут, то про задачу можно забыть?
Правильно.
Отправил по второй задаче первую. Я дебилко :)
интересно, а как валидируется субмит? казалось бы, во второй нужно сказать YES/NO, а в первой — число
Да, интересно, я им отправил клар :)
Очевидно же, что надо добавлять в input тесткейсы sample input'а, и если они не проходят (или файл не парсится) — не давать такое сабмитить. Но по необъяснимым причинам фейсбук этого не делает...
я сейчас поглядел — во всех моих инпутах есть хотя бы по одному примеру из условия, так что наверно они тоже догадались до этого, но вот как-то оно не так...
Правильно ли я понимаю, что надпись "Last valid submission at %d minutes ago" означает правильный залитый аутпут на скачанный тест, но программа будет проверяться только после окончания раунда?
Чуть выше пишут, что код тестироваться не будет....
Аутпут будет сравниваться с правильным.
lol,i forgot to put ':' after "Case #x",and couldn't find it in 6 min,now i can do nothing to change it,maybe it will be better if contestants can submit solutions during whole 72 hours...
You can try to solve another two problems without this stupid mistake :)
sure :)
I forgot the "#" character on "Case #x:" for 2 questions. It was actually worse, because it doesn't complain about output format, and I ended up doing it twice. I'm probably getting Wrong Answer for this :S
Why not more flexible validation, like on codeforces or topcoder: just output the numbers, one by line or separated by spaces... If we want to see what test case correspond at what input, we can easily debug ourselves using flag and number of test case, but I don't see any reason to use this format for validation...
In Google Code Jam the system checks that the first line of the submission starts with "Case #1: " and that the number of such "Case #X:" is consistent with the input file — http://code.google.com/codejam/faq.html#how_we_judge.
This helps to prevent submitting source code as output or output to a different problem accidentally.
Facebook just copied the format blindly without implementing the reasons behind it.
I forgot to output the '#' in 'Case #1:' and my solution passed!!
ппц, вместо s.find(x) != s.end() написал !s.count(x) и не влез в 6 минут(( после того как поменял, все тесты прошли за 35 сек(((((
а в чём пипец то, обычный баг, давайте все будем свои баги на кодфорсес постить
Куча решений закомичено на github. Думаю пользоваться ими нежелательно :)
Нигде в правилах этого года не могу найти, что в первом раунде не учитывается штрафное время, как в прошлом году. Что-то поменялось, они забыли это упомянуть или я просто не вижу?
Я заинтересовался и написал в техподдержку. Заранее сорри за мой кривой английский.
Я: Hello, I have a question about Round 1 rules. Is it true, taht competitors, who have the same amount of points, as competitor at 500-th place, will advance to the Round 2 regardless of their penlaty?
Админ: No, this year only the top 500 will advance.
Такие дела.
Я всё больше убеждаюсь в гениальности сего мероприятия...
P.S. Хорошо ещё нормальное время начало попалось, а не 3 ночи по нашему.
Да, глупость та еще. Даже старт в 20.00 по Киеву меня не радует, поздновато. И не понятно, что делать, если задача не решается — то ли мой затуп и надо срочно решать, то ли задача — гроб и можно идти спать.
Вот да, непонятны 24 часа тогда. Если не учитывается время — то каждый просто решает когда ему удобно по таймзоне. Мы с pashka вот в 22:02 выезжаем на поезде в Петрозаводск. Остается надеяться на надежность 3g (хотя бы на станциях)
Тактика дождаться остановки чтобы сабмитить была правильная, ИМХО. Очень уж рвано инет был вплоть до Волховстроя
Нет, неправильная. Сабмитил бы сразу (и если бы не пофейлилась при этом сеть) — прошел бы. А так все как обычно. Всем удачи!
Да уже одно то, что тестирование затянулось на пару дней, и так из года в год, уже наталкивает на такие мысли. А зачем делать раунд на 24 часа, при фиксированной квоте 500, это вообще глупость, слов нет.
Еще можно вспомнить историю с посылками из Opera двухгодичной давности. Это вообще по-моему за рамками добра и зла. При чем, когда я пытался достучаться до админов, меня просто игнорировали.
Кстати, что-то поменялось с тех пор? Я уже два года отправляю из Google Chrome.
Я не в курсе, у меня та же история: в тот год всё из оперы сдавал, а следующие из хрома.
UPD. А, по ссылке как раз моя ветка :)
И сейчас, и год назад в Опере уже всё заработало.
Написал небольшой отчетик о том как я удачно слажал.
Всем удачи в последующих раундах! Пусть победит сильнейший!
Может кто-то рассказать, какие правила Online Elimination Round 1? Время не считается, но проходит первых 500 человек. Как это?
Да они вроде уже и сами рассказали — время учитывается.
С сайта:
"Clarification: For this year the time penalty does matter in Round 1. Only the top 500 people will advance, unlike last year when it was the top 500 plus everyone who got as many problems correct as the 500th person."
Т.е время считается, просто в прошлом году было чуть иначе.
Все прочитал, не нашел.
Футболки будут?
FAQ
Ахах.. фб лежит :)
Есть у кого-то на http://www.facebook.com/hackercup/problems.php?round=189890111155691 ошибка сервера?
Кто знает, как связаться с поддержкой Хакеркапа?
Возможно, через "Give Feedback / Request Clarification" на странице "Instructions"
..или на любой странице с задачей
Кстати, а с какой целью ты по второй задаче послал код первой?...
Хм. Полагаю, что было так: я открываю диалог для "выбрать тест", вижу, что не в той папке (потому что нет файла с нужным названием), перехожу в нужную, открываю. Хочу выбрать исходник, открывается старая папка, выбираю файл с решением.
Ну или просто стормозил.
Да в общем, понятно, как может случиться такая ошибка ("поспешишь — людей насмешишь"), да и код я уже посмотрел у других участников.
Дело в другом. Они как-то проверяют код? Если нет, то зачем его посылать, а если да, то когда и как, и что тебе будет за такой промах?
Видимо, как раз недавно проверили. Меня в таблице уже нет, никаких уведомлений не приходило. Написал им куда-то, посмотрим, что будет. Очень печально.
Нет вообще? В Code Jam насколько я знаю в таких случаях могут убрать только одну задачу а не все.
"Sorry, you don't appear anywhere on this scoreboard!"
Facebook Hacker Cup. Trying to copy Google Code Jam and failing at it miserably since 2011...
Вот скопировали бы уже полностью. А то эта лотерея без изи сабмитов и нормальных семплов уже начинает раздражать
О, ты есть. Но без второй задачи. Я поднялся ровно на одно месте =)
Собственно, код, если интересно.
Я правильно понимаю, что если я однажды получил инпут и мое время закончилось, то я уже с этой задачей ничего делать не могу?
Правильно
Learn a lesson from Hacker Cup, READ THE RULES CAREFULLY! I supposed that I can download another test data like GCJ, which lead my submitting without enough testing, and finally lose points. Crying...
Oh, I was a second from win! I was filling really pity that happened so. I've understood that there is one chance to submit a problem and decided to do better testing. And found that for the worst case it could compute in 7 minutes. I've decided to implement multithreaded implementation. And in rush did not mind that processor loaded and refused from multithreaded solution(I thought it was slow. But the real reason was that processes of previous testing that I've stopped before were hanging). Then I've decided that the test wouldn't be so hard and started a submit. I've ran solution and it start slowly displaying results and than I understood system was swapping! I've started to kill those previously ran solutions and it started to output result quite fast. It was about a minute when 15 tests left, but it managed to calculate them all. The counter was just 0:00 when I was pressing a submit button and it blocked. I was filling very pity because after this I found that real time to compute was a minute and a 50 seconds. Just another one lesson for me and now for all who is reading this.
Ооооочень интересный Online Elimination Round 1. Все решает часовой пояс в котором ты живешь. Замечательно.
Чего там решает пояс? Всегда в таких случаях игнорят суммарное время и проходят все с определённым числом задач.
ну в этот раз-то не так. дополнительный минус еще и в том, что задачи довольно простые, а значит всё решат более 500 человек.
Да-да, огромный минус, ужасно простые задачи. В 1-й раунд прошло 10к человек, и уже чуть ли ни треть из них засабмитили утешительную задачу, и целых 7% засабмитили все 3. Конечно, гораздо правильнее было бы затачивать массовый раунд под потребности топ 1%, чего уж там.
Если раунд для отбора 500 человек, то он должен решить задачу адекватного отбора 500 человек, а не взять 500 рандомных топов, а всех остальных пораовать тем, что они порешали
Если кто-то крутой решает все 3 задачи за 1 час и делает мелкую багу в одной — то он не проходит. Или решает все 3 задачи за 1 час, но ближе к концу контеста. А если кто-то, у кого свободного времени много,^W^W^W^W^W решает все задачи за 24 часа (не забыв написать стресстесты) — то он проходит. Офигенно адекватные правила.
Как закончится, напишите пожалуйста как решить вторую задачу (у меня не прошла по времени).
Фейсбук как всегда будет проверять целый день после окончания раунда, скорее всего — ребята там крайне оперативные((
Может, кто-нибудь из крутых посонов расшарит решения после окончания round 1, для осуществления возможности прогнать на скачанных инпутах и сравнить аутпут со своим?
На гитхабе же какие-то откровенно стремные решения находятся поиском. Видимо, несознательными являются только нубы, выкладывая решения до окончания турнира))))
Итак! =) Умеет ли кто-нибудь решать 45 быстрее, чем за O(W*H)? Точнее, O(max(N, W*H)).
Если кому-то интересно, могу описать решение за указанную асимптотику.
что-то типа O(N * log(H) + W + H)
А сортировка данных, или без неё можно?
Ничего не сортировал, все распихивал по векторам :)
А как считать количество нулей в дереве с массовой операцией? Или делал как-то не так?
Дерево отрезков с интервальной модификацией. количество нулей = длина — сумма единиц.
Модификация-то — прибавление.
Считать минимум и количество раз которое он встречается.
ну вообще это можно, храня в вершине дерева (минимум, количество минимумов), но я обошелся простыми сетами и мэпами и операциями с ними.
Я это делал. Но как быстро пересчитать количество минимумов?
Все модификации дерева — это либо прибавление единицы к отрезку, либо вычитание. Причем, отрицательные числа у нас никогда не появятся. Значит, можем для каждой вершины хранить, сколько отрезков из +1 ее целиком накрывает, а также количество нулей в поддереве. Тогда, если данную вершину накрывает хотя бы один отрезок, то нулей в поддереве нет. Если же ее ничего не накрывает, то мы можем быстро пересчитать информацию, зная ответ для детей.
Спасибо!
Будет интересно почитать как быстрее:)
Ну а мое O(W*H), на мощном компе считалось где-то 2 минуты, заняло 6 ГБ оперативки.
Всё что нужно это структура, позволяющая в множестве чисел находить предыдущее и следующее.
Будем двигаться поясом из P рядов. Также для каждой колонки заведём счётчик — сколько там в этом поясе битых пикселей. Для любой колонки где это >= 1, добавляем её в множество.
Для первого пояса считаем пробежась по весму множеству. А когда переходим от пояса (x..x+P-1) к (x+1..x+P), у нас могут убраться или прибавиться битые пиксели. Изменяем счётчик. Если у какой-то колонки он стал 0, или перестал быть 0, изменяем множество, предварительно пересчитав число хороших позиций.
Есть три величины: prev, now, next. now — что мы сейчас хотим добавить, prev — предыдущее число в множестве за now, next — следующее число в множестве за now.
В случае добавления now сумма хороших позиций для этого пояса увеличивается на good(prev,now) + good(now,next) — good(prev,next). В случае удаления сумма увеличивается на good(prev,next) — good(prev,now) — good(now,next). Функция good(l,r) = max(0,r-l-Q). Итого мы можем перейти на следующий пояс за логарифмическое время для одного пикселя. И каждый пиксель мы обработаем не больше двух раз. Итого: O(N log N).
Использовать можно set, но можно и что угодно, например дерево отрезков, потому что я извращенец и надо бы выучить STL.
я нихера не понял, но круто
Допустим мы делаем sweepline, по поясу из P рядов. То есть все возможные расстановки перебираем сначала в [0..P-1] ряду, потом в [1..P] и.т.п.
Если мы для пояса знаем какие из его колонок заняты, то есть те колонки, в которых в данном поясе есть хотя бы один битый пиксель, посчитать кол-во расположений в этом поясе легко — перебираем все соседние занятые колонки, между ними можно разместить max(0, r-l-Q) картин.
Осталось эффективно перейти к следующему поясу. Мы храним массив — сколько битых пикселей в каждой колонке в данном поясу. При переходе ряд сверху уходит, а снизу приходит. Если ни одна занятая колонка не появилась/убралась (кол-во битых пикселей 0 -> 1/1 -> 0), то тогда ответ для данного пояса будет таким же как для предыдущего.
Если же что-то изменилось, и допустим появилась занятая колонка, это повлияет только на одну пару соседних чисел. Отнимаем от суммы пояса что было, вставляем колонку, прибавляем к сумме пояса 2 новые величины.
Так мы можем быстро переходить от пояса к поясу. Стало ли более понятно или если всё ещё непонятно, можно пожалуйста, что именно более ясно рассказать?
Действительно, в java итератор по сету интов перебирает элементы в возрастающем порядке (не знаю, как в С++). Круто и ведь, главное, очень просто.
А умеет ли в Java TreeSet обращаться к предыдущему элементу по итератору? То есть, если мы сделали что-то вроде set ::iterator it = s.lower_bound(x); и хотим взять не текущий элемент, а предыдущий. Кажется, такая штука часто нужна, в том числе и в этом решении мне пригодилась и я вот думал, как ее сделать на Java.
Ну есть же методы lower() и higher(). А получение следующего итератора в C++, насколько я понимаю, все равно за логарифм работает.
вроде как все действия с Random Access Iterator (а у сета именно такой) производятся за константу.
Random Access Iterator? Круто. В каком языке у вас есть Random Access Iterator для сета? Скажите, и я буду переучиваться на этот язык.
Вроде бы ни в каком per se нету, но кто же мешает написать свое сбалансированное дерево? После чего приделать random access за O(log) проблем нету вообще
В третьей на мой взгляд ограничения нечестные в плане что O(T*W*H) проходит у тех, у кого свежая техника, а остальные получают либо TLE, либо честно пишут O(T*N log N).
Вторую задачу я кажется overkill'нул, написав O(T * M^3)...
Если написать O(T*W*H) с O(max(W,H)) памяти, это довольно быстро работает.
Я написал так, и меня довольно медленный комп. Работало пару минут. Но вообще это не очень, согласен.
Я тоже так писал. А как ещё? O(m) поисков идеального паросочетания.
Если я сильно не заблуждаюсь, самый простой способ найти макс. паросочетание — это O(M^3). Хопкрафт-Карп снижает это до O(M^(5/2)). А не O(M^2).
У моего решения макс. паросочетание полностью ищется всего один раз.
О, да, сорри, у меня O(m^4). Ого, а как искать его один раз?
Можно так: сначала ищем полный парсоч, а теперь когда фиксируем какую-то букву на очередной позиции i: то у нас меняются ребра в графе, только инцидентные блоку содержащего позицию i, мы их все выкидываем (выкинется одно ребро из паросочетания), добавляем новые ребра (это все O(n)) и запускаем поиск паросочетания только из нашего блока (одного, т.е. например одну итерацию Куна) — O(m^2) на обновление паросочетания.
Да, у меня тоже самое. Только я не по буквам, а по блокам перебирал. И у графа ребро если было, стояла минимальная строка, которая удовлетворяет паре (то есть все ? заменябтся на a).
Только я бы хотел уточнить процедуру обработки блока i. Когда мы выбираем пару для блока i, у нас есть поток N-1, как уже было замечено выше. Мы хотим выбрать такое ребро для блока i, чтобы его значение было минимальным. То есть, если мы будем перебирать все рёбра из блока i по одному, из кое-каких полное паросочетание будет недостижимо, а из кое-каких — будет. Из всех из которых будет — выбираем минимальное и для блока i+1 оставляем в графе ВСЕ рёбра с таким минимальным значением — мы не знаем какое будем использовать.
Но, это всё ещё M BFS'ов. Надо узнать из каких рёбер из i-го блока полное паросочетание запустимо. Не добавляем ни одно ребро пока, запускаем BFS из единственной пустой правой вершины. BFS обратный — справа налево идём по пустым, слева направо — по полным. Итого получаем множество правых вершин, из которых можно добраться инкрементирующим путём до единственной пустой правой вершины. Объединяем это множество с множеством рёбер из i-го — выбираем минимум — одного BFS'а хватает для обработки i-го блока. Пускаем поток по любому из минимальных рёбер, при этом оставим все минимальные рёбра из i-го блока, убрав все остальные.
А у кого сколько в третьей в тестах было максимально разных точек?
В том тесте, что у меня всего лишь около 85 тысяч, что сильно меньше ожидаемого мной миллиона...
Тоже 85 тысяч (=85176).
У меня 6 тестов с N = 1000000.
Имеются ввиду различных, при генерации попадаются одинаковые, если удалить дубликаты, то получается порядка 85 тысяч.
А таких максимум получилось 39581 (тест 36402 39273 278 35 1000000 11371 25106 51 98 33 54).
Ууу как всё плохо. Ведь тогда можно было втупую за квадрат делать, за 6 минут как-нибудь доработало бы. Неужели с их способом генерации нельзя много различных точек получить? Что-то не верится.
Можно получить миллион простыми тестами типа
Мое решение на таком тесте работало бы вечность... А их файл прорешало за 8 секунд (правда в четыре потока).
моё решение тоже не айс, O(H*W*log(N/W)), но в восемь потоков (4 из которых Hyper Threading) на ксеонах 3.4 с этим инпутом справилось за полторы минуты.
У меня тоже sweepLine O(nlogn). Было бы хорошо, если W и H были 100000. Думаю не честно написать квадратное.
Как решать вторую?
Перебираем очередную букву, делим всё на блоки, строим граф, пускаем паросочетание. Если полное — оставляем букву, иначе меняем на следующую. Если использовать запоминания каких-нибудь промежуточных паросочетаний то можно получить WA.
а букву обязательно перебирать? недостаточно каждый блок из k2 перебрать и однозначное минимальное слово восстановить, затем попытаться построить полное паросочетание
Каждый блок из k1. Ну если перебирать мин. слово среди тех которые получаются пересечением этого блока из k2, и проверять паросочетанием — то да, выйдет. Но если при этом фиксировать пару к этому блоку, то будет WA.
Я через min-cost-flow сделал. Просто нужно протянуть такое паросочетание, стоимость которого наименьшая, только пришлось матрицу стоимости делать длинной арифметикой, чтобы 6^100 влезло.
И я также, только на Python :)
Они довольно быстро в этом году. Что ж, слава богу, по крайней мере, для прохода было достаточно решить все три задачи за любое время.
Я вижу, что очень многие провалили вторую задачу, интересно, какую такую стандартную ошибку там можно было допустить?
если пытаться фиксировать минимальные блоки каждый раз, то можно упасть по примеру
и у некоторых выдаёт ответ abab, а нужно abaa
Фиксировать минимальные блоки?
ну решение заключается в том, что мы пытаемся строить ключ подбирая блоки, которые ставим в начале, и если получается полное парасочетание, то фиксируем его. Оно падает на этом примере.
Оно будет действовать следующим образом: Пробуем поставить в начало минимальный префикс a?
Дополнить получается и поэтому мы его фиксируем. Но после того, как a? занято, мы можем построить только abab.
Ага, ясно) Спасибо.
Пришло время рассказать веселую историю, друзья... Налейте себе вкусного чая, возьмите печеньки и слушайте.
Прекрасным субботним вечером (да уже скорее ночью) я сел писать Facebook Hacker Cup Round 1. Первая задача оказалась совсем несложной, и написал я очень быстро. Немного ручных тестов, немного сомнений над кнопкой "Download Input File", и задача отправляется на сервера Facebook.
Вторая задача тоже особых волнений в мою душу не принесла, решение оказалось на поверхности, для написания кода — также несложное. Снова немного ручных тестов и сомнений над кнопкой "Download Input File", и ответ с решением летит по проводам в противоположную точку земного шара.
... шесть минут ничто не предвещало беды, однако когда они истекли, мой субмит по второй задаче Security исчез. Совсем исчез. Ну то есть прям совсем-совсем исчез. На странице условия было написано лишь "Time Expired", в мониторе только дырка от бублика на пересечении строки с моим именем и столбца задачи Security.
ООООООП-ПААААА. Следующие N минут я пребывал в расстроенных чувствах, так как не понимал, что случилось и что теперь делать. Я помнил прошлый год Hacker Cup, когда надо было решать абсолютно все задачи, а иначе ты попадал бы на самое дно турнирной таблицы.
Следующим шагом было написать куда только можно, найти любые способы связи с организаторами. Я написал всем моим знакомым в Facebook, комментарий, в форму обратной связи. Никто мне мгновенно не ответил, и я уже менее уверенный в исходе Round 1, сел писать третью.
Примерно через полчаса мне пришел ответ от поддержки, текст был следующим:
Ну что же, раз они подтверждают, что имеют в наличии мой субмит, то по идее и волноваться не за что. Казалось бы. Однако это все меня по-прежнему не радовало, и я желал прояснить ситуацию. Подозрительным казалось то, что из веб-интерфейса никаким образом не следовало, что я вообще что-либо посылал, а в мониторе так ничего не появлялось вместо черточки.
Через какое-то время мне стали отвечать те, кому я писал в личные сообщения. Меня заверили, что действительно мой субмит лежит в базе, все нормально, волноваться не за что. Я предложил — давайте проверим, что все на самом деле пришло в нормальном виде, например, смерив md5, однако реакции на это предложение не последовало.
На данный момент результаты подведены, но у меня по-прежнему стоит черточка в столбце "Security". На написанные стопицот писем в поддержку мне не пришло больше ни одного ответа.
На данный момент я занимаю почетное 423 место.
P.S. Я категорически не понимаю, как это в принципе возможно — принять субмит, но не отобразить его в мониторе. Значит, такая ситуация может быть у кого угодно и когда угодно. В финале, в квалификации, в любом из раундов с любым из участников. Более того, каждому могут заявить: "У нас есть твой ответ, но вот в мониторе показывать мы его не будем". Поддержка в принципе старается не отвечать участникам.
P.S.S. кстати, да, мне e-maxx тут напомнил... я пользуюсь Google Chrome 24.0.1312.57
Все это показывает величайшее свинское отношение организаторов и бесконечно бажную систему проведения.
Всем спасибо за внимание, надеюсь, печеньки и чай были вкусными.
Ну прошёл же :) Так что не такой критичный баг.
По поводу "свинского отношения организаторов" — думаю, тут дело в другом. Организаторов совсем мало, ресурсов на контест тоже выделяется мало, а в квалификации/раунде 1 участвует куча неадекватов-"кулхацкеров", которые наверняка заваливают организаторов огромным количеством спама.
А вот "бесконечно бажная система" — совершенно по делу сказано. Это такой подход фейсбука, слепить по-быстрому на php (или на, упаси боже, флеше), даже не думая о юнит-тестах и проверке корректности. У меня общее впечатление от их системы очень хорошо согласуется с общим впечатлением от фейсбука в целом.
P.S. Я категорически не понимаю, как это в принципе возможно — принять субмит, но не отобразить его в мониторе — ну такого очень просто добиться, с помощью какого-нибудь race condition. Но отсутствие стресс-теста для системы, который такое поймал бы, — тоже не в плюс разработчикам.
Проблема в перепутанном файле ответов и исходнике. В этом случае система выдает предупреждение (The output file was incorrectly formated. ...) и не принимает решение на проверку.
Хорошо то, что кончается неплохо, однако статусы показывайте какие-нибудь что ли... Предупреждения я не видел, хотя всегда страничку не обновлял, не закрывал. Поэтому не могу утверждать, что оно было :)
не смог найти, уже известно во сколько будет следующий раунд?
http://www.facebook.com/notes/facebook-hacker-cup/hacker-cup-2013-faq/591459627536609
спасибо. вот нельзя так просто взять и провести раунд не ночью. :)
Ночью лучше всего, по-моему.
Мда, судя по тому что в анализе третьей задачи первого раунда описан N log N, и нет ни слова о W*H, в Facebook качественно готовят задачи, проверяя хотя бы несколько других возможных решений...
Вот прямо N log N? Я таких не знаю. У меня N log W, например
Я, например, предпочитаю сортировать массивы при помощи sort(), а не ручной сортировки подсчетом или других извращений.
Ну ок, мне было для самого решения удобнее сделать бакеты, и точки как объекта у меня не было в принципе, но теперь мне хотя бы понятно откуда берется log N
У меня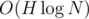 . Делаю sweepline снизу вверх, в multiset'е поддерживаю x выколотых точек и ответ (количество позиций таких, что справа есть сколько надо пустых столбцов), пересчитывается за
. Делаю sweepline снизу вверх, в multiset'е поддерживаю x выколотых точек и ответ (количество позиций таких, что справа есть сколько надо пустых столбцов), пересчитывается за  .
.
Ну они сортируют данные битые пиксели.
А можете объяснить как FB решает эту задачу, а то прочитав их решение я только понял его сложность и что там есть дерево интервалов?
Я уже попытался два раза c такой же ассимптотикой.
Они, как я понял, делают такой же sweepline по поясу, только для пояса ответ считают сразу в дереве отрезков, обновляя его при вставке/удалении засчёт доп. информации о самом левом и самом правом битом пикселе на данном отрезке пояса приведённым кодом.
just saw the news that winner is none other than what we guess, its Petr :) Congrats Petr !!!