Spoiler
Setter: antontrygubO_o
Preparer: errorgorn
Setter: errorgorn
Preparer: errorgorn
Setter: errorgorn and oolimry
Preparer: oolimry
Setter: errorgorn
Preparer: errorgorn
Setter: iLoveIOI
Preparer: iLoveIOI
Setter: errorgorn and oolimry
Preparer: errorgorn
You may have realized that python codes in the editorial are quite short. We actually had a code golf challenge among testers. You are invited to try code golf our problems and put them in the comments. Maybe I will put the shortest codes in the editorial ;)
Rules for code golf:
Hello again Codeforces!
errorgorn, oolimry and iLoveIOI are glad to invite you to participate in Codeforces Round 723 (Div. 2) which will be held at May/28/2021 17:05 (Moscow time). The round will be rated for the participants with a rating lower than 2100. Participants from the first division are also welcomed to take part in the competition but it will be unrated for them.
You will be given 2 hours and 30 minutes to solve 6 questions. One of the puzzles is interactive, please read the guide of interactive problems before the contest.
We would like to thank:
We hope you find the bugaboos interesting and fun! Wish you high rating!
Here is scoring distribution because you guys deserve it <3
Btw, remember to downvote all testers who writes stupid comments to beg for likes.
UPD: editorial released
Setter: syksykCCC
Prepared by: syksykCCC
Setter: syksykCCC
Prepared by: syksykCCC
Setter: oolimry
Prepared by: errorgorn
Setter: errorgorn
Prepared by: errorgorn
Setter: Widowmaker
Prepared by: Widowmaker and syksykCCC
Setter: 3.141592653 and star_xingchen_c
Prepared by: 3.141592653 and star_xingchen_c
Setter: errorgorn and oolimry
Prepared by: errorgorn
Setter: Ynoi
Prepared by: Widowmaker and Ynoi
Setter: oolimry
Prepared by: oolimry
As the solution to this problem is very long, the full editorial is split into $$$4$$$ parts. If you want to challenge yourself, you can try reading one part at a time and see if you get any inspiration. You can also try to read the specific hints for each part.
Привет, Codeforces!
Присоединяйтесь к объединенному Div1 и Div2 раунду Codeforces Raif Round 1 (Div. 1 + Div. 2), который будет проходить при поддержке Райффайзенбанка и начнётся в 17.10.2020 16:05 (Московское время). Он будет рейтинговым и открытым для обоих дивизионов. Обратите внимание на нестандартное время начала раунда.
Все задачи были придуманы и подготовлены bensonlzl, oolimry, errorgorn, dvdg6566, shenxy13.
Спасибо:
zhangguangxuan99 за то, что он лучший IOI тренер <3
Армии наших тестеров: Ari, KAN, Monogon, prabowo, SYY, shashwatchan, TeaTime, Tlatoani, -rs-, agul, cstuart, dantoh, jhkoh, kai824, kymmykym, lperovskaya, mango_lassi, morzer, Retired_cherry, socho, zhangguangxuan99, zscoder за их советы и замечания.
MikeMirzayanov за замечательные системы Codeforces и Polygon.
Вам будет дано 8 задач, одна из которых будет разделена на простую и сложную версии, и 150 минут на их решение.
Мы надеемся что для вас условия покажутся короткими, задачи интересными и претесты будут сильными. Всем успешного раунда и повышения в рейтинге!
Разбалловка будет объявлена ближе к началу раунда.
Спасибо компании Райффайзенбанк за подарки участникам:
Призы для победителей:
1-3 место = Беспроводная колонка
4-10 место = Поясная Сумка
11-20 место = Power bank

Случайные 50 участников, не вошедшие в топ-20, но решившие хотя бы одну задачу, получат:
Термокружки
Футболки от Райффайзенбанка
Несколько слов от команды алготрейдинга Райффайзенбанка:
Наша команда разрабатывает ультрасовременную HFT-платформу для торговли на валютном, срочном и фондовом рынках, основанную на математических, статистических моделях и машинном обучении, с высокими требованиями к latency и производительности.
Вы сможете:
поработать с задачами в таких областях как JIT-компиляция, устройство современных CPU;
поучаствовать в разработке высоконагруженных распределённых систем;
оптимизировать скорость исполнения кода и архитектуру платформы;
реализовывать низкоуровневые структуры данных и алгоритмы.
Если вам интересно пообщаться с рекрутерами и командой алготрейдинга Райффайзенбанка, заполните короткую анкету и расскажите о себе.
UPD: Разбалловка: 500 — 1000 — 1000 — 1500 — 1750 — 1750 — (2250+750) — 4000
UPD: Разбор!
So my O level Chinese exam is in 2 days so I decided to learn a data structure that I can only find resources for in Chinese. I thought I might as well write a tutorial in English.
This data structure is called 析合树, directly translated is cut join tree, but I think permutation tree is a better name. Honestly, after learning about it, it seems like a very niche data structure with very limited uses, but anyways here is the tutorial on it.
Thanks to dantoh and oolimry for helping me proofread.
Consider this problem. We are given a permutation,$$$P$$$ of length $$$n$$$. A good range is a contiguous subsequence such that $$$\max\limits_{l \leq i \leq r} P_i - \min\limits_{l \leq i \leq r} P_i = r-l$$$. This can be thought of the number of contiguous subsequence such that when we sort the numbers in this subsequence, we get contiguous values. Count the number of good ranges.
Example: $$$P=\{5,3,4,1,2\}$$$.
All good ranges are $$$[1,1], [2,2], [3,3], [4,4], [5,5], [2,3], [4,5], [1,3], [2,5], [1,5]$$$.
The $$$O(n^2)$$$ solution for this is using sparse table and checking every subsequence if it fits the given conditions. But it turns out we can speed this up using permutation tree to $$$O(n\log{n})$$$.
A permutation $$$P$$$ of length $$$n$$$ is defined as:
A good range is defined as a range, $$$[l,r]$$$ such that $$$\max\limits_{l \leq i \leq r} P_i - \min\limits_{l \leq i \leq r} P_i = r-l$$$ or equivalently $$$\nexists x,z \in [l,r], y \notin [l,r], P_x \lt P_y \lt P_z$$$.
We denote a good range $$$[l,r]$$$ of $$$P$$$ as $$$(P, [l,r])$$$, and also denote the set of all good ranges as $$$I_g$$$.
So we want a structure that can store all good ranges efficiently.
Firstly, we can notice something about these good ranges. They are composed by the concatenation of other good ranges.
So the structure of the tree is that a node can have some children and the range of the parent is made up of the concatenation of the children's ranges.
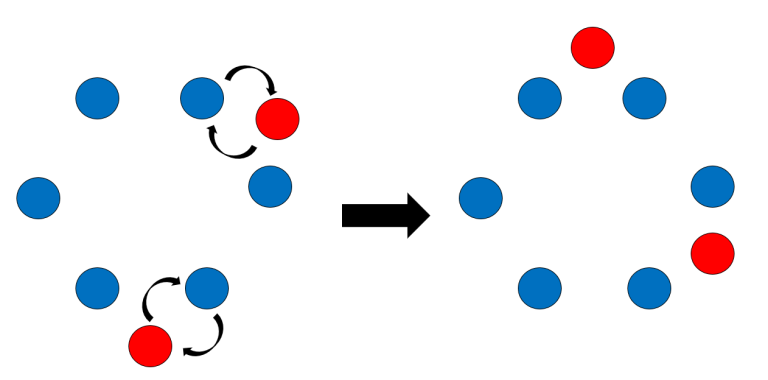
Here is an example permutation. $$$P=\{9,1,10,3,2,5,7,6,8,4\}$$$.
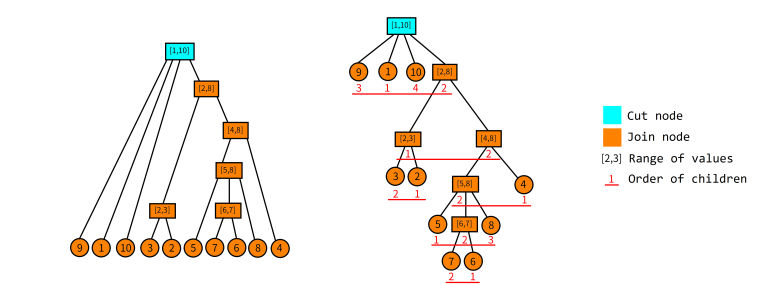
As we can see from the above image, every node represents a certain good range, where the values in the node represent the minimum and maximum values contains in this range.
Notice in this data structure, for any 2 nodes $$$[l_1,r_1]$$$ and $$$[l_2,r_2]$$$, WLOG $$$l_1 \leq l_2$$$, either $$$r_1 \lt l_2$$$ or $$$r_2 \leq r_1$$$.
We shall define some terms used in this data structure:
Firstly, we have this very trivial property. The union of all ranges of children is the node's range. Or in fancy math notation, $$$\bigcup_{i=1}^{|S_u|} S_u[i]=[u_l,u_r]$$$.
For a join node $$$u$$$, any contiguous subsequence of ranges of its children is a good range. Or, $$$\forall i,j,1 \leq i \leq j \leq |S_u|, \bigcup_{i=l}^{r} S_u[i]\in I_g$$$.
For a cut node $$$u$$$, the opposite is true. Any contiguous subsequence of ranges of its children larger than 1 is not a good range. Or, $$$\forall i,j,1 \leq i \lt j \leq |S_u|, \bigcup_{i=l}^{r} S_u[i]\notin I_g$$$.
The property of join nodes is not too hard to show by looking at the definition of what a join node is.
But the property of cut nodes is slightly harder to prove. A way to think about this is that for some cut node such that there is a subsequence of ranges bigger than 1 that form a good range, then that subsequence would have formed a range. This is a contradiction.
Now we will discuss a method to create the Permutation Tree in $$$O(n\log{n})$$$. According to a comment by CommonAnts, the creator of this data structure, a $$$O(n)$$$ algorithm exists, but I could not find any resources on it.
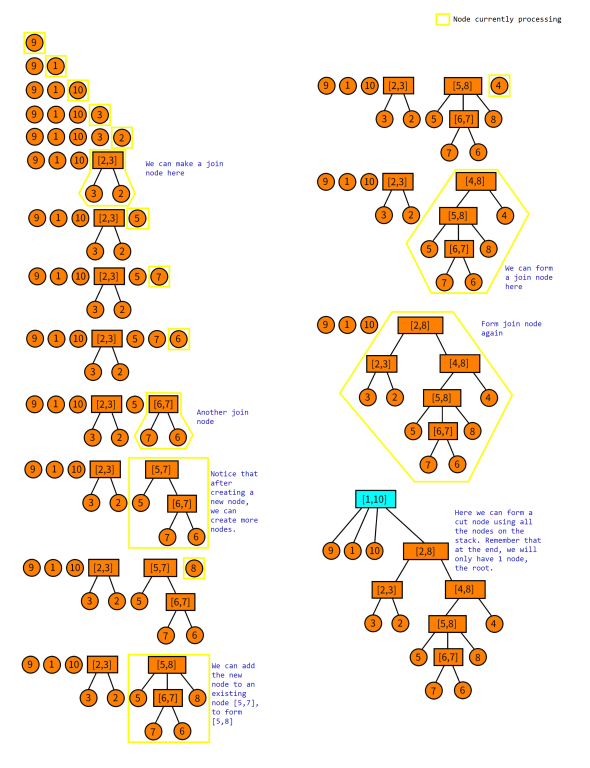
We process the permutation from left to right. We will also keep a stack of cut and join nodes that we have processed previously. Now let us consider adding $$$P_i$$$ to this stack. We firstly make a new node $$$[P_i,P_i]$$$ and call it the node we are currently processing.
Notice that after processing all nodes, we will only have 1 node left on the stack, which is the root node.
For operation 1, if we note that we can only do this if the node on top of the stack is a join node. Because if we can add this as a child to a cut node, then it contradicts the fact that no contiguous subsequence of ranges of children larger than 1 of a cut node can be a good range.
For operation 2, we need a fast way to find if there exists a good range such that we can make a new node from. There are 3 cases:
We have established for a good range $$$(P,[l,r])$$$ that $$$\max\limits_{l \leq i \leq r} P_i - \min\limits_{l \leq i \leq r} P_i = r-l$$$.
Since $$$P$$$ is a permutation, we also have $$$\max\limits_{l \leq i \leq r} P_i - \min\limits_{l \leq i \leq r} P_i \geq r-l$$$ for all ranges $$$[l,r]$$$.
Equivalently, we have $$$\max\limits_{l \leq i \leq r} P_i - \min\limits_{l \leq i \leq r} P_i - (r-l) \geq 0$$$, where we have equality only for good ranges.
Say that we are currently processing $$$P_i$$$. We define a value $$$Q$$$ for each range $$$[j,i], Q_j=\max\limits_{j \leq k \leq i} P_k - \min\limits_{j \leq k \leq i} P_k - (i-j),0 \lt j \leq i$$$. Now we just need to check if there is some $$$Q_j=0$$$, where $$$j$$$ is not in the current node being processed.
Now we only need to know how to maintain this values of $$$Q_j$$$ quickly when we transition from $$$P_i$$$ to $$$P_{i+1}$$$. We can do this by updating the max and min values every time it changes. How can we do this?
Let's focus on updating the max values since updating the min values are similar. Let's consider when the max value will change. It changes every time $$$P_{i+1} \gt \max $$$. Let us maintain a stack of the values of $$$\max\limits_{j \leq k \leq i}P_k$$$, where we will store distinct values only. It can be seen that this stack is monotonically decreasing. When we add a new element to this stack, we will pop all elements in the stack which are smaller than it and update their maximum values using a segment tree range add update. This amortizes to $$$O(n)$$$ as each value is pushed into the stack once.
Do note to decrement all $$$Q_j$$$ by 1 since we are incrementing $$$i$$$ by 1.
Now that we can maintain all values of $$$Q_j$$$, we can simply check the minimum value of the range we are interested in using segment tree range minimum queries.
If we can make a new cut node, then we greedily try to make new cut node. We can do this by adding another node from our stack until our new cut node is valid.
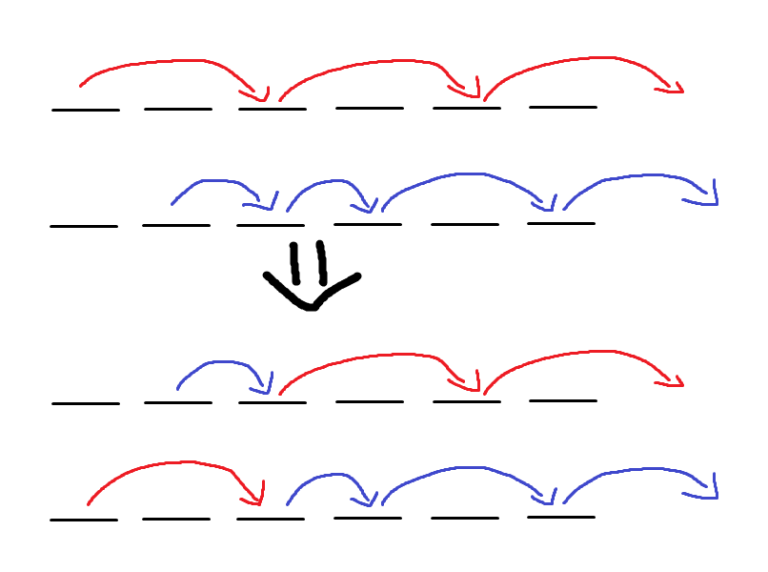
Since the above may be confusing, here is a illustration of how the construction looks like.
Codeforces 526F – Pudding Monsters
CERC 17 Problem I – Instrinsic Interval
Codeforces 997E – Good Subsegments
Sumitomo Mitsui Trust Bank Programming Contest 2019 has just finished, and this is an unofficial editorial.
Thanks to my friends oolimry and shenxy13 for helping write some of the editorial.
You can solve it simply by checking for each end date of the Gregorian calendar. However, note that as the second date directly follows the first date (a fact which I think is not clear in the English translation), we can also check whether they're in different months, or whether the second date is the first day of a month. This can be done in constant time.
We note that there is monotonicty in this question. $$$\lfloor 1.08(X+1) \rfloor \geqslant \lfloor 1.08X \rfloor$$$. Hence, we can binary search the answer. When we binary search the value of X(the answer), if $$$\lfloor 1.08X \rfloor = N$$$, then we have our answer. Otherwise, we can search higher if $$$\lfloor 1.08X \rfloor \gt N$$$ and search lower otherwise. If we find that no number gives us desired N, then it is impossible.
We can simply do a 0-infinity knapsack with weights 100,101,...,105 and check if some value is reachable. We get a time complexity of $$$O(N)$$$.
First, we note that there are $$$O(N^{3})$$$ subsequences of the string, so generating all of them and using a set to check for number of distinct subsequences is TLE. However, there are only at most 1000 distinct such subsequences, from 000 to 999. We can linearly scan through the string for each of these possible subsequences to check if it is actually a subsequence of the string in $$$O(N)$$$. Thus, this can be solved in $$$O(1000N)$$$, which is AC.
Firstly, we can imagine there are 3 imaginary people standing at the very front, each with a different colour hat. For each person, we consider how many possible people could be the first person in front of him with the same hat colour. If the current person has number X, then the number of ways is:
(no. of ppl with X-1 in front) — (no. of ppl with X in front)
This is because those with X in front of him must be paired with one of the X-1 already, so this reduces our options.
Implementation wise, we can store an array which keeps track of the number of people with no. X who are not paired yet. Initially, all values are 0, except at index -1 with the value of 3. Then when processing the current p[user:AtillaAk]erson X, we multiply the answer by arr[X-1], decrease arr[X-1] by 1, and increase arr[X] by 1.
Firstly, if $$$T_{1}A_{1}+T_{2}A_{2}=T_{1}B_{1}+T_{2}B_{2}$$$, the answer is infinity.
Else, WLOG, we let $$$T_{1}A_{1}+T_{2}A_{2} \gt T_{1}B_{1}+T_{2}B_{2}$$$. If $$$A_{1} \gt B_{1}$$$, then Takahashi and Aoki will never meet each other. The answer is 0. Now, we have solved all the corner cases. We shall move on to the general case. We shall call the period $$$T_{1}+T_{2}$$$. Now, we shall find the number of periods where Takahashi and Aoki meet each other. If we do some math, we get the number of periods to be $$$\lceil \frac{T_{1}(B_{1}-A_{1})}{(T_{1}A_{1}+T_{2}A_{2})-(T_{1}B_{1}+T_{2}B_{2})} \rceil$$$.
The number of times that Takahashi and Aoki meet each other is $$$2periods-1$$$ since every period they meet each other twice when Aoki overtakes Takahashi and Takahashi overtakes Aoki. We need to minus 1 since we do not count the first time they meet each other at the very start. We submit this and... WA.
Yes, we need to think about the case where $$$\frac{T_{1}(B_{1}-A_{1})}{(T_{1}A_{1}+T_{2}A_{2})-(T_{1}B_{1}+T_{2}B_{2})}$$$ is a whole number. In this case, we need to add one, as there will be one more time where Aoki will meet up with Takahashi but never overtake him. And now we get AC. (Thanks to Atill83 for pointing out the mistake)
Example problem: (I dont have the link as this problem only exists in my school's private judge)
We have an array of n positive intergers and we need to group them into k segments such that each element of the array is in a segment and that all elements in a segment are contigous. The cost of a segment is the sum of the numbers in the segment squared.
We need to minimize the total cost of all the segments.
Example 1, we have n=5 and k=3. Where the array is [1,2,3,4,5]. The optimal answer is by grouping (1+2+3) , (4) and (5) into different segments. The total cost is 6^2 + 4^2 + 5^2 =77.
Example 2, we have n=4, k=2. Where the array is [1,1000000,3,4]. The optimal answer is by grouping (1,1000000) and (3,4) into different segments. The total cost is 1000001^2+7^2=10000200050
Now I asked some people and they said this can be solved by doing the lagrange (or aliens) speedup trick. We shall define a cost C. Then do a convex hull trick where we try to minimize the value of all our segments but we also add C to our cost whenever we make a new segment. Now, if C is INF, then we will only have 1 segment, while if C is 0 we will have n segments. So people claim that we can binary search on C to find some C where there will be K segments existing.
This allowed me to AC the problem, but my solution was not always correct as the test cases were weak. I thought of this test case: n=4, k=3. Where is array is [1,1,1,1] Now, when C is 2, we get 4 segments. But when C is 3, we get 2 segments only. Therefore when I ran my code against this case my code printed 8, even though the answer was (1+1)^2+1^2+1^2=6.
So I think I need someway to iterpolate the lagrange speedup trick. Anyone can help? My code is here.
For my code, the input format is:
n k
a1 a2 a3 a3... an
Where ai is the ith element in the array.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | Qingyu | 158 |
| 2 | adamant | 152 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 144 |
| 5 | errorgorn | 141 |
| 6 | cry | 139 |
| 6 | Proof_by_QED | 139 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 9 | TheScrasse | 134 |