[Tutorial] Schieber & Vishkin LCA Algorithm
The following is a tutorial of the paper: On finding lowest common ancestors: Simplification and parallelization by B Schieber, U Vishkin.
Disclaimer: this technique doesn’t allow one to solve any new problems. Rather it only shaves a log off of some common problems.

To the best of my knowledge, this comment https://mirror.codeforces.com/blog/entry/78931?#comment-655079 was the first time that someone mentioned this algorithm.
Thanks to ssk4988 for giving feedback on this blog.
The Inlabel Numbers
Consider the following code, where adj is the adjacency list of a tree:
int lsb(int x) { return x & -x; } // lsb=least significant bit
int id = 1;
void dfs(int u, int p) {
for(int v : adj[u]) if(v != p){
dfs(v, u);
if(lsb(inlabel[u]) < lsb(inlabel[v])) inlabel[u] = inlabel[v];
}
if(!inlabel[u]) inlabel[u] = id++;
}
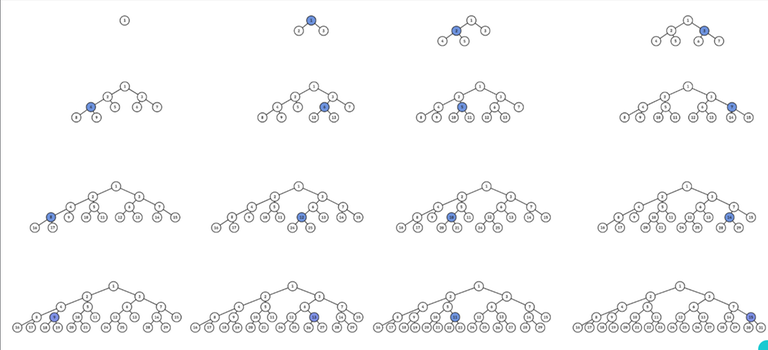
What is this array inlabel? First the leaves have inlabel 1,2,3,... in DFS order.

Photo credits: https://mirror.codeforces.com/blog/entry/132771
Then internal nodes have inlabel equal to the inlabel of one of its children, namely the child whose inlabel has the highest lsb.

To better understand this, observe lsb(8) >= lsb(i) for all i in [1,14]. Thus the 8-th leaf, and all of its ancestors have the same inlabel of 8:

Then 4 and 12 have next highest lsb, thus the 4th and 12th leaf, and all of their ancestors which are not ancestors of the 8th leaf have the same inlabel:

Then 2, 6, 10, 14 have the next highest lsb. We have:


Observe the main 2 facts about the inlabel numbers:
- They decompose the tree into vertical paths: nodes
uandvare on the same vertical path iffinlabel[u]==inlabel[v]. - You can compress each vertical path into a single node then add edges
inlabel[parent[u]] -> inlabel[u]. What you get is not quite a perfect binary tree, rather something similar to a virtual/auxiliary tree of a perfect binary tree. If nodeuis an ancestor of nodevin the original tree, then nodeinlabel[u]is an ancestor of nodeinlabel[v]in the perfect binary tree andlsb(inlabel[u]) >= lsb(inlabel[v]).
If nodes u and parent[u] are on different vertical paths, then lsb(inlabel[parent[u]]) > lsb(inlabel[u]). So if you start at u and walk the vertical paths to the root, the lsb’s are strictly increasing, so you’ll walk on at most log(n) paths.
And that’s it! So basically it is a drop-in replacement for HLD.
https://judge.yosupo.jp/submission/367730 https://judge.yosupo.jp/submission/367732
LCA in O(1)
Let LCA(u,v) be a query.
Observe LCA(u,v) is an ancestor of both u and v in the original tree thus inlabel[LCA(u,v)] is an ancestor of both inlabel[u] and inlabel[v] in the perfect binary tree. Thus inlabel[LCA(u,v)] is an ancestor of LCA(inlabel[u], inlabel[v]) in the perfect binary tree.
This gives us a starting point. Let’s think about how to calculate LCA(inlabel[u], inlabel[v]). Consider the perfect binary tree and the inlabel’s written vertically in binary:

Observe:
- The bits more significant than
lsb(inlabel[u])represent theroot <-> inlabel[u]path. - The bit
lsb(inlabel[u])represents the depth where theroot <-> inlabel[u]path stops.
Intuitively, we want to consider the most significant bit where inlabel[u] and inlabel[v] differ as this bit represents the first place where the root <-> inlabel[u] path differs from the root <-> inlabel[v] path. This bit is exactly the bit bit_floor(inlabel[u] ^ inlabel[v]). Formally, we have:
bit_floor(inlabel[u] ^ inlabel[v]) == lsb(LCA(inlabel[u], inlabel[v]))
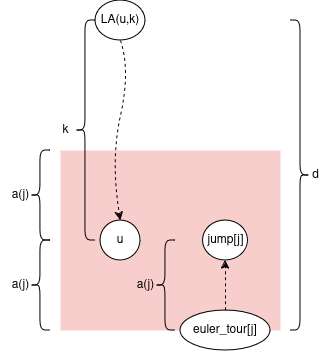
It would be so nice if LCA(u,v) always lies on the vertical path corresponding to LCA(inlabel[u], inlabel[v]). But the problem is LCA(u,v) lies on the vertical path corresponding to inlabel[LCA(u,v)] which can be any ancestor of LCA(inlabel[u], inlabel[v]). You could have a case like:

In this case LCA(inlabel[17], inlabel[24]) == 10, but inlabel[LCA(17,24)] == 16. For example, 10 -> 12 -> 8 -> 16 is the path from 10 to 16 in the perfect binary tree.
To fix this problem, we need a new array, ascendant.
The Ascendant Numbers
Definition:
ascendant[root] = lsb(inlabel[root]);
ascendant[u] = ascendant[parent[u]] | lsb(inlabel[u]); // for u != root
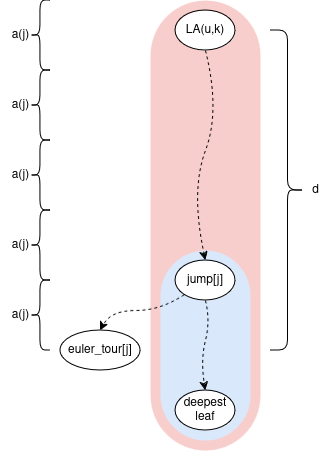
Observe if you walk up vertical paths from u to the root, each vertical path corresponds to a bit in ascendant[u]. So you can think of ascendant[u] as storing information about all ancestors of u in some sort of compressed format.
Observe LCA(u,v) is an ancestor of both u and v, thus bit lsb(inlabel[LCA(u,v)]) is set in both ascendant[u] and ascendant[v]. Thus, bit lsb(inlabel[LCA(u,v)]) is set in ascendant[u] & ascendant[v]. In fact, we can say something slightly more general: lsb(inlabel[LCA(u,v)]) is the lowest set bit in ascendant[u] & ascendant[v] which is >= lsb(LCA(inlabel[u], inlabel[v])). Thus, let’s introduce a new variable j:
j = ascendant[u] & ascendant[v] & -bit_floor(inlabel[u] ^ inlabel[v])
First, -bit_floor(inlabel[u] ^ inlabel[v]) can be thought of as a mask that zeros out all lower bits. Next, each bit in j corresponds to some vertical path containing or above LCA(u,v). For example, we have: lsb(j) == lsb(inlabel[LCA(u,v)]).
Then if we do: ascendant[u] ^ j (ascendant[u] - j also works), we xor-ed out all the high bits in ascendant[u]. What we’re left with are the lower bits corresponding to the vertical paths strictly below LCA(u,v).

Let’s introduce a new variable k as k=bit_floor(ascendant[u] ^ j), representing the highest vertical path strictly below LCA(u,v). One final property of inlabel numbers is (inlabel[u] & -k) | k is the ancestor of inlabel[u] in the perfect binary tree such that lsb(inlabel[u] & -k) | k) == k.
If we precalculate an array head which maps inlabel numbers to the head (node closest to root) of the corresponding vertical path, then parent[head[(inlabel[u] & -k) | k]] represents the lowest ancestor of u on the same vertical path as LCA(u,v). We do the same for v, then LCA(u,v) is the node closer to the root.
We only jump up u if it’s not on the same vertical path as LCA(u,v), i.e. if inlabel[u] != inlabel[LCA(u,v)]. (And similarly for v). For example if inlabel[u]==inlabel[v] initially, then we don't jump up either node and LCA(u,v) is just the node closer to the root.
https://judge.yosupo.jp/submission/367724
<O(n),O(1)> Almost-LCA in Tree
Problem: https://mirror.codeforces.com/blog/entry/71567
Assume we have u,v, where u != v.
If ascendant[u] is not a submask of ascendant[v], then u is not an ancestor of v. The answer is parent[u].
Else, ascendant[u] is a submask of ascendant[v]. Then each bit in ascendant[u] ^ ascendant[v] corresponds to a vertical path below LCA(u,v). Let’s find the highest set bit with:
k = bit_floor(ascendant[u] ^ ascendant[v])
Then jump up v with: v = head[(inlabel[v] & -k) | k]. Now it’s just a few cases:
- If
parent[v] == uthen answer isv - Else if
depth[u] < depth[v]then the next node on path is the child ofuwith the same inlabel asu(precompute this in an array) - Else
uis not an ancestor ofv. The answer isparent[u].
Open Problem
I thought a lot but couldn’t solve it myself. Also I was unable to get AI to solve it. I’d love to know an answer to it.
Currently, it requires 2 DFS’s. In the first DFS, the inlabel numbers are calculated bottom-up. Then in the second DFS, the ascendant numbers are calculated top-town and depend on the inlabel numbers.
The open problem is can you do it in a single DFS. Maybe there’s some alternative to the ascendant numbers which can be calculated in the first DFS alongside with the inlabel numbers which also allows O(1) LCA.
If you use this as a replacement for HLD, then you need 2 DFS’s anyways, but if you use this only for LCA, then a single DFS solution would be nice to have.