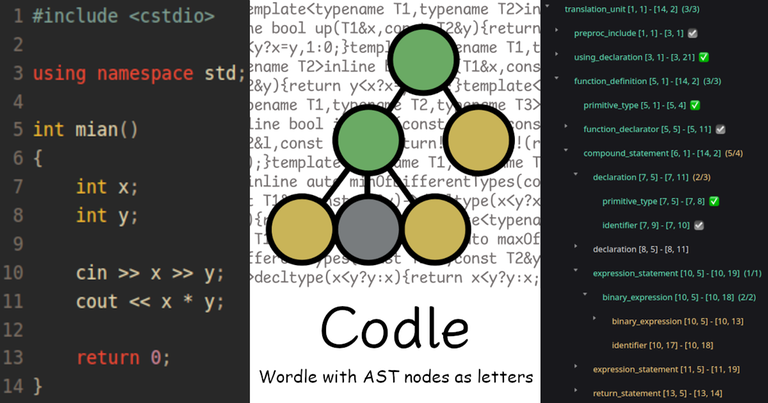
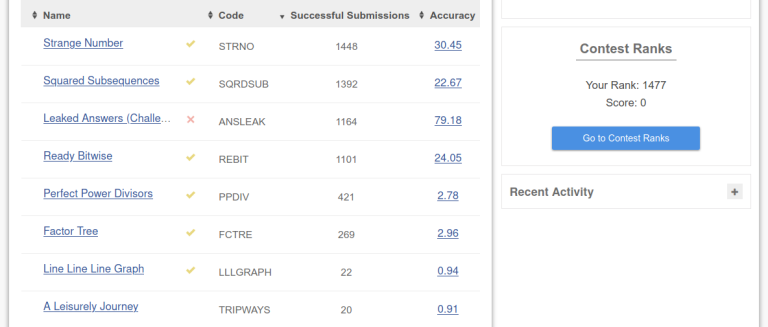
There are Wordle, Semantle, 汉兜, Medle, and much more. So, will there be a, Codle?
Code is long and complicated. It's not like a word or a piece of music.
But code has a formal structure. We can build an abstract syntax tree, and that's what can be guessed like Wordle.
So here it is, come and play Codle!
P.S. If you speak Chinese, you can watch this introduction video.
P.P.S. If you want to read the source first, here it is.