


Sorry for the long wait. All problems were written, prepared, and editorialized by Yam, hyforces, culver0412, HaccerKat, alexlikemath007, jay_jayjay, n685, Mustela_Erminea, Jasonwei08, eysbutno, training4usaco, nyctivoe, and gg_gong. The problems (with problem credits) can be found in the Novice Gym and Advanced Gym. Also thanks to our testers for providing valuable feedback and to our logistics and web team for making TeamsCode possible!
Novice A/Advanced A: Lily Pads
This is the first problem — don't overthink it!
Try a few examples on paper — see if you notice any patterns.
Try to focus on just one row of lilypads, and it's contribution to the total score.
Notice that for each row, both lily pads will get jumped on. If you focus on a row, the first frog will jump onto the currently afloat lily pad, and when it leaves, the other lily pad goes afloat, causing the second frog to jump on it.
Therefore, for each row, one of the frogs will jump on the right lily pad, and the other will jump on the left. Each row contributes 1 point to the answer, so the answer is simply the number of rows, which is $$$N$$$.
n = int(input())
print(n)
Novice B: Sacrifice the Rook
This might be annoying to code, but just do it.
Watch out for edge cases, and read the sample explainations.
You can show that only considering rook moves is sufficient.
You simply need to check every possible rook and king move, and then check if it is possible for the opponent's king to capture your rook. Make sure that your rook doesn't jump over your king, and that your king doesn't "defend" your rook after you make your move. (See sample test case 5).
A shortcut you can take is that you don't have to check king moves. If your rook is able to be captured if the king moves, that means it must be diagonally adjacent to the opponent's king. (Otherwise, their king is in check, and the position is not valid.) Thus, there are two possible rook moves to become adjacent to the opponent's king, and your king can't defend both of these cells to stop you from sacrificing your rook.
#include <bits/stdc++.h>
using namespace std;
#define pii pair<int, int>
#define fi first
#define se second
bool isAdjacent(pii p1, pii p2) { return (abs(p1.fi - p2.fi) <= 1 && abs(p1.se - p2.se) <= 1); }
bool pathClear(pii start, pii end, pii wk, pii bk) {
if (start.se == end.se) {
int col1 = min(start.fi, end.fi), col2 = max(start.fi, end.fi);
for (int col = col1 + 1; col < col2; col++) {
if ((wk.fi == col && wk.se == start.se) || (bk.fi == col && bk.se == start.se))
return 0;
}
} else if (start.fi == end.fi) {
int row1 = min(start.se, end.se), row2 = max(start.se, end.se);
for (int row = row1 + 1; row < row2; row++) {
if ((wk.fi == start.fi && wk.se == row) || (bk.fi == start.fi && bk.se == row))
return 0;
}
}
return 1;
}
signed main() {
ios::sync_with_stdio(0), cin.tie(0);
int t;
cin >> t;
for(int tc = 0; tc < t; tc++){
string wks, wrs, bks;
cin >> wks >> wrs >> bks;
auto toPos = [&](string s) -> pii { return {s[0] - 'a' + 1, s[1] - '0'}; };
pii wk = toPos(wks), wr = toPos(wrs), bk = toPos(bks);
bool flg = 0;
for (int dc = -1; dc <= 1; dc++) {
for (int dr = -1; dr <= 1; dr++) {
if (dc == 0 && dr == 0)
continue;
pii cur = {bk.fi + dc, bk.se + dr};
if (cur.fi < 1 || cur.fi > 8 || cur.se < 1 || cur.se > 8)
continue;
if (cur.fi != wr.fi && cur.se != wr.se)
continue;
if ((cur.fi == wk.fi && cur.se == wk.se) ||
(cur.fi == bk.fi && cur.se == bk.se))
continue;
if (!pathClear(wr, cur, wk, bk))
continue;
if (isAdjacent(cur, wk))
continue;
flg = true;
}
}
cout << (flg ? "YES" : "NO") << "\n";
}
return 0;
}
Novice C: Fill the world with Argon
Notice how in the sample, argon is poured on the cell with the largest height.
Argon cannot move up. Therefore, if a cell is surrounded by cells with lower heights, you must pour argon on that cell. Call such cells peaks.
Is pouring argon on all peaks sufficient?
Call cells peaks if it has no higher adjacent cells. Note that you must pour argon on peaks since argon from adjacent cells cannot flow to a peak. It also turns out pouring argon on all the peaks is sufficient.
Proof: Assume for the sake of contradiction that argon is poured on all peaks, and the world is not filled. Consider the cell $$$X$$$ with the largest height that is not filled with argon. Note that $$$X$$$ cannot be a peak, as otherwise argon would have been poured on it. Thus, there must be a cell $$$Y$$$ higher than it that is adjacent to it. And, $$$Y$$$ cannot be filled with argon, as otherwise, argon would have flowed from $$$Y$$$ to $$$X$$$, and filled $$$X$$$ with argon. However, this creates a contradiction, as $$$Y$$$ has a higher height and is not filled with argon, contradicting that $$$X$$$ has the largest height and is not filled with argon.
Therefore you can simply loop through all cells, and check for cells that satisfy this, in $$$O(NM)$$$.
/**
* @author n685
* @date 2025-03-22 19:02:42
*/
#include <bits/stdc++.h>
#ifdef LOCAL
#include "dd/debug.h"
#else
#define dbg(...) 42
#define dbg_proj(...) 420
#define dbg_rproj(...) 420420
void nline() {}
void bar() {}
void start_clock() {}
void end_clock() {}
#endif
namespace rs = std::ranges;
namespace rv = std::views;
using u32 = unsigned int;
using i64 = long long;
using u64 = unsigned long long;
const std::array<int, 4> dx{-1, 0, 1, 0}, dy{0, 1, 0, -1};
int main() {
#ifndef LOCAL
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
#endif
int n, m;
std::cin >> n >> m;
std::vector a(n, std::vector<int>(m));
for (std::vector<int>& arr : a) {
for (int& val : arr) {
std::cin >> val;
}
}
int ans = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
bool good = true;
for (int d = 0; d < 4; ++d) {
int x = i + dx[d];
int y = j + dy[d];
if (x < 0 || x >= n || y < 0 || y >= m) {
continue;
}
if (a[i][j] < a[x][y]) {
good = false;
break;
}
}
if (good) {
++ans;
}
}
}
std::cout << ans << '\n';
}
Read the main solution first.
We iterate over the cells in decreasing order of height. For each cell without argon, we simulate the pouring of argon using a flood fill algorithm like dfs or bfs and add $$$1$$$ to the answer. This process takes $$$\mathcal{O}(nm \log (nm))$$$ time due to sorting the cells.
This process works because it turns out the only cells in this process that we pour argon on are peaks. For peaks, argon cannot flow from another cell to it, so we pour argon onto peaks. For non-peaks, based on the proof of the main solution, if all cells higher than it contain argon, then the non-peak has to contain argon as well. Since in this process, when processing a cell, we make sure all higher cells contain argon, we do not pour argon on non-peaks.
/**
* @author n685
* @date 2025-03-22 19:10:16
*/
#include <bits/stdc++.h>
#ifdef LOCAL
#include "dd/debug.h"
#else
#define dbg(...) 42
#define dbg_proj(...) 420
#define dbg_rproj(...) 420420
void nline() {}
void bar() {}
void start_clock() {}
void end_clock() {}
#endif
using u32 = unsigned int;
using i64 = long long;
using u64 = unsigned long long;
const std::array<int, 4> dx{-1, 0, 1, 0}, dy{0, 1, 0, -1};
int main() {
#ifndef LOCAL
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
#endif
int n, m;
std::cin >> n >> m;
std::vector a(n, std::vector<int>(m));
for (std::vector<int>& arr : a) {
for (int& val : arr) {
std::cin >> val;
}
}
std::vector<std::pair<int, int>> coord;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
coord.emplace_back(i, j);
}
}
std::sort(
coord.begin(),
coord.end(),
[&](const std::pair<int, int>& lhs, const std::pair<int, int>& rhs) {
return a[lhs.first][lhs.second] > a[rhs.first][rhs.second];
}
);
std::vector fl(n, std::vector<bool>(m));
auto dfs = [&](auto&& self, int i, int j) -> void {
for (int d = 0; d < 4; ++d) {
int x = i + dx[d];
int y = j + dy[d];
if (x < 0 || x >= n || y < 0 || y >= m || fl[x][y] || a[i][j] < a[x][y]) {
continue;
}
fl[x][y] = true;
self(self, x, y);
}
};
int ans = 0;
for (auto [i, j] : coord) {
if (!fl[i][j]) {
++ans;
fl[i][j] = true;
dfs(dfs, i, j);
}
}
std::cout << ans << '\n';
}
Novice D: Please solve this in O(N^3)
There are two ways to solve this problem — the normal way, and the cool $$$O(N^3)$$$ way.
Normal Way:
Consider one color at a time.
You can use algorithms like Depth First Search, Breadth First Search, or Disjoint Set Union to find connected components in a graph, and thus determine whether two nodes are connected by some path.
Consider a "subgraph" that includes only nodes of a specific color. If there is a path from $$$i$$$ to $$$j$$$ in the subgraph, that means there is a valid path from $$$i$$$ to $$$j$$$ in the graph with all nodes sharing that color in common. Therefore, we can just find the connectivity of nodes in the subgraphs for each color using DFS, BFS or DSU, and if two nodes are connected in a subgraph, we can mark them as connected.
This has a time complexity of $$$O(30 N^2)$$$. This is faster than the $$$O(N^3)$$$ solution, but not as cool.
#include <bits/stdc++.h>
using namespace std;
#define pii pair<int, int>
#define fi first
#define se second
const int N = 755;
struct DSU {
vector<int> fa;
DSU(int n) : fa(n) { iota(fa.begin(), fa.end(), 0); }
int find(int a) { return fa[a] == a ? a : fa[a] = find(fa[a]); }
void merge(int a, int b) {
a = find(a), b = find(b);
if (a != b) fa[b] = a;
}
};
int n, m, cm[N];
vector<pii> G;
bitset<N> vis[N];
signed main() {
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m;
for (int i = 0; i < n; i++)
cin >> cm[i];
for (int i = 1, u, v; i <= m; i++) {
cin >> u >> v, u--, v--;
G.push_back({u, v});
}
for (int i = 0; i < n; i++)
vis[i].reset(), vis[i].set(i, 1);
for (int c = 0; c < 30; c++) {
DSU dsu(N);
for (auto &[u, v] : G) {
if ((cm[u] & (1 << c)) && (cm[v] & (1 << c)))
dsu.merge(u, v);
}
unordered_map<int, vector<int>> mp;
for (int i = 0; i < n; i++) {
if (cm[i] & (1 << c)) {
int rt = dsu.find(i);
mp[rt].push_back(i);
}
}
for (auto &p : mp) {
vector<int> &lc = p.se;
for (auto u : lc)
for (auto v : lc)
vis[u].set(v, 1);
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++)
cout << (vis[i].test(j) ? '1' : '0');
cout << "\n";
}
return 0;
}
Cool way:
Is there a famous graph algorithm that runs in $$$O(N^3)$$$?
The famous graph algorithm is the Floyd-Warshall algorithm. Could you adapt it to this problem using bitwise operations?
Note that Floyd-Warshall can be modified to check for connectivity in a graph.
Normally, when running Floyd-Warshall, the statement $$$\text{dist}[j][k] = \text{min}(\text{dist}[j][k], \text{dist}[j][i] + \text{dist}[i][k])$$$ is used.
However, Floyd-Warsahll can also be used to check for connectivity. Define $$$\text{connected}[i][j] = \text{true}$$$ if $$$i$$$ and $$$j$$$ are connected, and $$$\text{false}$$$ otherwise. Then, we follow the same steps as the normal solution, initialize the adjacency matrix for each subgraph, and run Floyd-Warshall. Our update is $$$\text{connected}[j][k] = \text{connected}[j][k] \ \text{||} \ (\text{connected}[j][i] \ \text{&&} \ \text{connected}[i][k])$$$. That is, if there is a path between $$$j$$$ to $$$i$$$, and there is a path between $$$i$$$ to $$$k$$$, we should update the array to show that we found a path between $$$j$$$ to $$$k$$$.
This has a time complexity of $$$O(30N^3)$$$.
Notice that instead of running $$$30$$$ Floyd Warshalls, we can simply run all of them at once by using bitwise operations. Define $$$\text{bitmaskConnectivity}[i][j]$$$ to be a bitmask, where the $$$k$$$th bit is $$$1$$$ if there is a path between $$$i$$$ and $$$j$$$ such that all nodes on the path contain the color $$$k$$$.
We initialize $$$\text{bitmaskConnectivity}[i][i] = a[i]$$$, and if there is an edge between $$$i$$$ and $$$j$$$, $$$\text{bitmaskConnectivity}[i][j] = a[i] \ \text{&} \ a[j]$$$, and our update is $$$\text{bitmaskConnectivity}[j][k] = \text{bitmaskConnectivity}[j][k] \ \text{|} \ (\text{bitmaskConnectivity}[j][i] \ \text{&} \ \text{bitmaskConnectivity}[i][k])$$$
This has a time complexity of $$$O(N^3)$$$.
Although this solution might be very complicated, the code is short and simple!
#include <iostream>
using namespace std;
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
int n, m;
cin >> n >> m;
int a [n];
for(int i = 0; i < n; i++){
cin >> a[i];
}
int edg [n][n];
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
edg[i][j] = 0;
}
}
for(int i = 0; i < n; i++){
edg[i][i] = a[i];
}
for(int i = 0; i < m; i++){
int x, y;
cin >> x >> y;
x--;
y--;
edg[x][y] = edg[y][x] = (a[y] & a[x]);
}
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
for(int k = 0; k < n; k++){
edg[j][k] |= edg[j][i] & edg[i][k];
}
}
}
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
cout << (edg[i][j] != 0);
}
cout << '\n';
}
return 0;
}
Novice E: Mingle
Try solving the problem for a tree.
Consider the maximum number of pairs we can make in any tree of size $$$n$$$. What does this tell us about the problem?
Let's solve each connected component individually. For now, assume that all the connected components are trees.
Consider a bottom-up DFS approach. For a given node, pair up all the child nodes that have not been paired yet. If there's one remaining child node that hasn't been paired, we pair it with our current node.
This algorithm is guaranteed to maximize the number of pairs made. Specifically, for a tree of size $$$n$$$, we will make $$$\left \lfloor \frac{n}{2} \right \rfloor$$$ pairs.
Now, let's go back to the main problem. How can we solve for a normal graph?
Here's the thing: a graph is just a tree with extra edges added on. And the algorithm for solving a tree already pairs up as many players as possible. Thus, we actually don't care about the extra edges that a normal graph has!
So, to sum it up, we come up with a bottom-up DFS approach for a tree, and then we treat graphs roughly the same as trees. This allows us to solve the problem in $$$\mathcal{O}(n + m)$$$.
#include <bits/stdc++.h>
using ll = long long;
int main() {
std::ios_base::sync_with_stdio(false);
std::cin.tie(nullptr);
int n, m;
std::cin >> n >> m;
std::vector<std::vector<int>> adj(n);
for (int i = 0; i < m; i++) {
int u, v;
std::cin >> u >> v;
u--, v--;
adj[u].push_back(v);
adj[v].push_back(u);
}
std::vector<std::array<int, 2>> res;
std::vector<bool> vis(n);
const auto dfs = [&](int u, auto &&self) -> int {
vis[u] = true;
std::vector<int> ok;
for (const int &v : adj[u]) {
if (!vis[v] && self(v, self)) { ok.push_back(v); }
}
ok.push_back(u);
for (int i = 1; i < ok.size(); i += 2) {
res.push_back({ok[i - 1], ok[i]});
}
return ok.size() % 2;
};
for (int i = 0; i < n; i++) {
if (!vis[i]) { dfs(i, dfs); }
}
std::cout << res.size() << '\n';
for (const auto &[u, v] : res) {
std::cout << u + 1 << ' ' << v + 1 << '\n';
}
}
import sys
sys.setrecursionlimit(10**6)
n, m = map(int, input().split())
adj = [[] for _ in range(n)]
for _ in range(m):
u, v = map(int, input().split())
u -= 1
v -= 1
adj[u].append(v)
adj[v].append(u)
res = []
vis = [False] * n
def dfs(u):
vis[u] = True
ok = []
for v in adj[u]:
if vis[v]:
continue
if dfs(v):
ok.append(v)
ok.append(u)
for i in range(1, len(ok), 2):
res.append((ok[i - 1], ok[i]))
return len(ok) % 2
for i in range(n):
if not vis[i]:
dfs(i)
print(len(res))
for u, v in res:
print(u + 1, v + 1)
Novice F: Keys
Can you solve the problem with only one dimension?
Do the order of operations matter?
Do some operations cancel out (e.g. do two of the same operations have an effect on the final grid)?
We can notice that doing the operations on the grid is equivalent to doing the operations on each dimension once, because rotating a subgrid by $$$180$$$ degrees is equivalent to a reverse operation on the $$$x$$$ and $$$y$$$ axes. We also notice that the order of operations do not matter, and every pair of operations cancel each other out. Thus, there is at most one operation of each kind. We can then simulate each operation based on parity. We can simplify the code by using bitwise XOR, as we notice that, each reversing operation with $$$x, y$$$ is equivalent to taking XOR with $$$2^x-1, 2^y-1$$$.
#include<bits/stdc++.h>
using namespace std;
int main(){
ios_base::sync_with_stdio(0); cin.tie(0);
int n,m,k;
cin >> n >> m >> k;
long long int s[n+1]={0};
for(int i=1;i<=n;i++) s[i]=(s[i-1]<<1)^1;
pair<long long int,long long int> p[m];
for(int i=0;i<m;i++) cin >> p[i].first >> p[i].second;
long long int a=0,b=0;
int x,y;
for(int i=0;i<k;i++){
cin >> x >> y;
a^=s[x]; b^=s[y];
}
for(int i=0;i<m;i++){
cout << (p[i].first^a) << ' ' << (p[i].second^b) << '\n';
}
}
Novice G: Path on Big Grid
Solve the $$$N = 1$$$ and $$$M = 1$$$ subtask first.
Use dynamic programming. Let $$$\text{dp}_{i, j}$$$ represent the minimum cost to move from $$$(0, 0)$$$ to $$$(i, j)$$$.
Which states can we remove to make the solution fast enough?
Let $$$\text{dp}_{i, j}$$$ represent the minimum cost to move from $$$(0, 0)$$$ to $$$(i, j)$$$. At a cell, we can move right or down. Therefore, the transitions are,
\begin{align*} \text{dp}_{i, j} + C_{i + 1, j} &\rightarrow \text{dp}_{i + 1, j}, \\ \text{dp}_{i, j} + C_{i, j + 1} &\rightarrow \text{dp}_{i, j + 1}. \end{align*}
This takes $$$\mathcal{O}(NnMm)$$$ time, which reduces to $$$\mathcal{O}(nm)$$$ for the $$$N = 1$$$ and $$$M = 1$$$ subtask.
To optimize, we need to remove some states. It turns out transitioning on the corners only is sufficient.
Proof: For every possible path, we can transform it into a path with the same cost or lower that only changes direction at corners.
Let a chunk consist of all cells $$$(i, j)$$$ with the same $$$\left \lfloor \frac{i}{N} \right \rfloor$$$ and $$$\left \lfloor \frac{j}{M} \right \rfloor$$$, therefore having the same $$$c_{\left \lfloor \frac{i}{N} \right \rfloor, \left \lfloor \frac{j}{M} \right\rfloor}$$$.
First, let's look at the subpath for each chunk row such that the subpath spans multiple chunk columns. We can group all movements downward at the chunk with minimum cost at either the first or last column such that all direction switching besides entering and exiting the chunk row happens at corners. We can see that this process will not increase the cost.
Then, we do the same process for each chunk column such that the subpath spans multiple chunk rows such that all direction switching happens at corners. Therefore, we can represent the path using only corners, using similar transitions as the $$$N = 1$$$ and $$$M = 1$$$ subtask. Since each of the $$$nm$$$ chunks only has $$$4$$$ corners, we take $$$\mathcal{O}(nm)$$$ time.
#include <iostream>
using namespace std;
int grid [1000][1000];
int dp [2000][2000];
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int n, m, N, M;
cin >> n >> m >> N >> M;
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
cin >> grid[i][j];
}
}
for(int i = 0; i < 2 * n; i++){
for(int j = 0; j < 2 * m; j++){
dp[i][j] = 2000500000;
}
}
dp[0][0] = grid[0][0];
for(int i = 0; i < 2 * n; i++){
for(int j = 0; j < 2 * m; j++){
if(i != 0){
dp[i][j] = min(dp[i][j], dp[i-1][j] + grid[i/2][j/2] * (i%2 == 0 ? 1 : N-1));
}
if(j != 0){
dp[i][j] = min(dp[i][j], dp[i][j-1] + grid[i/2][j/2] * (j%2 == 0 ? 1 : M-1));
}
}
}
cout << dp[2 * n-1][2 * m-1] << endl;
}
Novice H: Fibocchi Sequence
When applying an operation, think of it in terms of the contribution to the sum of $$$f$$$.
DP?
Key observation: Applying an operation to some index $$$i$$$ increases the sum of $$$f$$$ by the same number regardless of what $$$f$$$ is.
Let $$$p_i$$$ be the increase to the sum of $$$f$$$ when $$$f_{n - i + 1}$$$ is increased by $$$1$$$. $$$p_i = \sum_{k=1}^{i} f_k$$$ for $$$1 \leq i \lt n$$$. $$$p_n$$$ is calculated differently since adding $$$1$$$ to $$$f_1$$$ does not change $$$f_2$$$. $$$p_n$$$ turns out to actually be $$$p_{n-2} + 1$$$.
Now, let $$$dp_x$$$ be the minimum number of operations for the sum of $$$f$$$ to be $$$x$$$ if $$$f$$$ is initially defined with $$$a, b = 0$$$. This can be computed using a knapsack DP with $$$p_i$$$ as the weights, all with the value of $$$1$$$.
To answer queries, we notice that the starting values of $$$a$$$ and $$$b$$$ are simply the same type of operations, just with no cost. Therefore, the answer is $$$dp_{x-v}$$$, where $$$v=a \cdot p_n + b \cdot p_{n - 1}$$$. If $$$x-v \lt 0$$$, the answer is $$$-1$$$.
Time Complexity: $$$\mathcal{O}(\max(x) + q)$$$
#include "bits/stdc++.h"
using namespace std;
const int N = 5000005;
const int inf = 1e9;
int n, m, k, qq;
int dp[N];
void solve() {
cin >> n >> qq;
vector<int> f(n), pref(n);
f[0] = f[1] = pref[0] = 1, pref[1] = 2;
for (int i = 2; i < n; i++) {
f[i] = f[i - 1] + f[i - 2];
pref[i] = pref[i - 1] + f[i];
}
fill(dp, dp + N, inf);
dp[0] = 0, pref[n - 1] = pref[n - 3] + 1;
for (int i = 0; i < n; i++) {
int w = pref[i];
for (int j = w; j < N; j++) {
dp[j] = min(dp[j], dp[j - w] + 1);
}
}
while (qq--) {
int a, b, x;
cin >> a >> b >> x;
x -= pref[n - 1] * a + pref[n - 2] * b;
cout << (x < 0 ? -1 : dp[x]) << "\n";
}
}
int32_t main() {
std::ios::sync_with_stdio(false);
cin.tie(NULL);
solve();
}
Novice I/Advanced B: Cell Towers
How can one transform a cell tower into an interval?
How does the answer to $$$i-1$$$ affect $$$i$$$?
We transform the problem into a 1D interval covering problem. Each house at coordinates $$$(r, c)$$$ is converted into an interval $$$[c, r + c]$$$. Then, we can process these intervals by sorting them based on increasing $$$c$$$. When $$$i=1$$$, the tower must span from the smallest starting coordinate to the largest ending coordinate among all intervals. As we go through the sorted intervals, we record gaps between consecutive intervals where coverage doesn't overlap. These gaps represent areas where additional towers could be placed to reduce the total coverage cost. By maintaining the current maximum coverage endpoint as we process each interval, we can prioritize covering the largest gaps first. This is achieved by sorting all gaps in decreasing order.
#include <iostream>
#include <algorithm>
#include <vector>
#define ll long long
using namespace std;
int main(){
int n;
cin >> n;
vector <pair<ll,ll>> v;
for(int i = 0; i < n; i++){
ll r; ll c;
cin >> r >> c;
v.push_back(make_pair(c, r+c));
}
sort(v.begin(), v.end());
ll minL = v[0].first;
ll maxR = 0;
for(int i = 0; i < n; i++){
maxR = max(maxR, v[i].second);
}
vector <ll> gaps;
ll curMxR = v[0].second;
int cnt = 0;
for(int i = 1; i < n; i++){
if((v[i].first - curMxR) > 0){
cnt++;
}
gaps.push_back(max(0ll, v[i].first - curMxR));
curMxR = max(curMxR, v[i].second);
}
sort(gaps.begin(), gaps.end());
reverse(gaps.begin(), gaps.end());
ll ans = maxR - minL;
cout << ans << " ";
for(int i = 0; i < (n-1); i++){
ans -= gaps[i];
cout << ans << " ";
}
cout << endl;
}
Novice J/Advanced C: Walk
Notice that the graph is bipartite. Consider the $$$2$$$ sets, which are $$$\{A, D\}$$$ and $$$\{B, C\}$$$.
From any node $$$u$$$, there is an edge from $$$u$$$ to every other node in the opposite set as $$$u$$$.
Read the hints above. Firstly, if $$$a \lt 2$$$, the answer is $$$0$$$. Continuing from hint $$$2$$$, we notice that a necessary and sufficient condition is for the walk to alternate between a node in the set $$$\{A, D\}$$$ and in the set $$$\{B, C\}$$$. From this observation, we notice that the answer is $$$0$$$ if $$$a + d - 1 \neq b + c$$$.
For the other cases, we can first compute the number of ways to arrange $$$A$$$ and $$$D$$$ arbitrarily (with first and last node being $$$A$$$). We can think of this as a string of $$$a + d - 2$$$ characters in which we must pick the positions of the remaining $$$a - 2$$$ $$$A$$$'s. The number of ways is the binomial coefficient $$$\binom{a + d - 2}{a - 2}$$$. We can then compute the number of ways to arrange $$$B$$$ and $$$C$$$ arbitrarily in a similar way, just without the first and last node being fixed. The number of ways here is $$$\binom{b + c}{c}$$$. The product of these two values is the answer.
To learn how to compute binomial coefficients, refer to this blog.
#include "bits/stdc++.h"
using namespace std;
typedef long long ll;
const int mod = 998244353;
const int N = 1000005;
int fact[N], inv_fact[N];
int mul(int x, int y) {
return (ll)x * y % mod;
}
int qpow(int b, int p) {
int res = 1;
for (; p; p >>= 1) {
if (p & 1) res = mul(res, b);
b = mul(b, b);
}
return res;
}
int C(int n, int k) {
if (k < 0) return 0;
return mul(fact[n], mul(inv_fact[k], inv_fact[n - k]));
}
void solve() {
int a, b, c, d;
cin >> a >> b >> c >> d;
a--;
if (a + d != b + c) {
cout << "0\n";
}
else {
cout << mul(C(a + d - 1, a - 1), C(b + c, b)) << "\n";
}
}
int32_t main() {
std::ios::sync_with_stdio(false);
cin.tie(NULL);
fact[0] = 1;
for (int i = 1; i < N; i++) {
fact[i] = mul(fact[i - 1], i);
}
inv_fact[N - 1] = qpow(fact[N - 1], mod - 2);
for (int i = N - 2; i >= 0; i--) {
inv_fact[i] = mul(inv_fact[i + 1], i + 1);
}
int tt;
cin >> tt;
while (tt--) {
solve();
}
}
Novice K/Advanced D: Not Japanese Triangle
Seems like calculating the answer layer by layer is impossible to solve this problem. How about calculate the contribution of each element to the answer? The first step towards doing this, is to find the intervals at which each element is minimum. This prompts us to find the first smaller element to the left and right of each.
How do we find the first smaller element to the left and right? Monotonic Stack or Binary Indexed Tree!
Now we know the bounds of the intervals at which the current element is minimum in. How do we range update answers for all intervals? Prefix sum! Also, note that we aren't range adding constant values, but rather, a piece-wise function.
Compute Spans:
For each $$$b[i]$$$ (the $$$i$$$'th element in the bottom row), compute:
- $$$A_i = i - L[i] - 1$$$, where $$$L[i]$$$ is the index of the last element to the left that is smaller than $$$b[i]$$$,
- $$$B_i = R[i] - i - 1$$$, where $$$R[i]$$$ is the index of the next element to the right that is less than or equal to $$$b[i]$$$.
To actually calculate $$$L[i]$$$ and $$$R[i]$$$, we will maintain a monotonic stack. When checking the current one, we keep on removing element bigger than the current, until a smaller one is found (which, must be the closest one because it's in a stack). We do this process from left to right for $$$L[i]$$$ and right to left for $$$R[i]$$$.
Finding Contribution Function:
Recognize that $$$b[i]$$$ contributes to every subarray (of lengths $$$t+1$$$ for $$$t$$$ from 0 to $$$A_i+B_i$$$) with weight $$$b[i] \times g_i(t)$$$, where $$$g_i(t)$$$ is:
- $$$t + 1$$$ for $$$0 \le t \le m$$$,
- $$$m + 1$$$ for $$$m \lt t \le M$$$,
- $$$A_i + B_i - t + 1$$$ for $$$M \lt t \le A_i + B_i$$$,
with $$$m = \min(A_i, B_i)$$$ and $$$M = \max(A_i, B_i)$$$.
Range Updates of Piece-wise Function:
For each element $$$b[i]$$$, break its contribution into three parts and “range update” an auxiliary array (or, equivalently, update two difference arrays for polynomial updates).
The standard prefix sum update only deals with constant update values, such as adding $$$4$$$ to range $$$[1, 23]$$$. However, we have a piece-wise, linear function to add. So, suppose we want to add function $$$F(i) = a \cdot i + b$$$ to range $$$[L, R]$$$, we perform the following updates:
- $$$p_1[L] += a$$$ and $$$p_1[R + 1] -= a$$$
- $$$p_0[L] += b$$$ and $$$p_0[R + 1] -= b$$$
After calculating prefix sum on $$$p_0$$$ and $$$p_1$$$. Our answer for $$$i$$$ will be $$$(i - 1) \cdot p_1[i] + p_0[i]$$$ (for $$$1$$$ indexing).
We essentially do this $$$3$$$ times because our function has $$$3$$$ pieces.
The total time complexity is $$$O(n)$$$, which is more than enough to pass this problem.
- Be careful about using $$$ \gt $$$ or $$$ \gt =$$$ in the monotonic stack. This may cause incorrect interval calculation.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define pll pair<ll, ll>
#define fi first
#define se second
#define uwu make_pair
const int N = 1e5 + 5;
ll n, a[N];
int l[N], r[N];
signed main() {
ios::sync_with_stdio(0), cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i];
pll stk[N];
ll tp = 0;
stk[0] = uwu(-1, 0);
for (ll i = 1; i <= n; i++) {
while (stk[tp] > uwu(a[i], i))
tp--;
l[i] = stk[tp].se;
stk[++tp] = uwu(a[i], i);
}
tp = 0;
stk[0] = uwu(-1, n + 1);
for (ll i = n; i >= 1; i--) {
while (stk[tp] > uwu(a[i], i))
tp--;
r[i] = stk[tp].se;
stk[++tp] = uwu(a[i], i);
}
vector<ll> p1(n + 2, 0), p0(n + 2, 0), res(n + 2, 0);
auto upd = [&](int pl, int pr, ll a, ll b) {
p1[pl] += a, p1[pr + 1] -= a;
p0[pl] += b, p0[pr + 1] -= b;
};
for (int i = 1; i <= n; i++) {
int st = i - l[i] - 1, ed = r[i] - i - 1;
int mi = min(st, ed), mx = max(st, ed), T = st + ed;
upd(1, mi + 1, a[i], a[i]);
if (mi + 1 <= mx) upd(mi + 2, mx + 1, 0, a[i] * (mi + 1));
if (mx + 1 <= T) upd(mx + 2, T + 1, -a[i], a[i] * (st + ed + 1));
}
for (int t = 2; t <= n; t++) {
p1[t] = p1[t - 1] + p1[t];
p0[t] = p0[t - 1] + p0[t];
}
for (int t = 1; t <= n; t++)
res[t] = (t - 1) * p1[t] + p0[t];
for (int t = n; t >= 1; t--)
cout << res[t] << " ";
cout << "\n";
return 0;
}
Novice L/Advanced E: Robot Racing
Solve for one subarray.
Greedy?
First, let's replace each $$$a_i$$$ with $$$\left\lfloor \frac{L}{a_i} \right\rfloor$$$: the latest possible second you have to shoot this robot by. For convenience, reverse $$$a$$$ so that it stays sorted in non-decreasing order.
Let’s consider solving the problem on one array. How can we check if we can make $$$k$$$ groups?
Say we have some arbitrary division of the robots into $$$k$$$ groups. For each group, we essentially only care about the robot $$$i$$$ with the smallest value $$$a_i$$$ out of all the robots in this group, because we must shoot this group before the fastest robot passes the end. Let this value for $$$j$$$-th group be $$$t_j$$$, meaning we have to shoot this group at time $$$t_j$$$ or before. Optimally, we should shoot the groups from smallest to greatest value of $$$t_j$$$. So to check if we can divide the robots into $$$k$$$ groups, we see if $$$t_1 \geq 1$$$, $$$t_2 \geq 2$$$, $$$t_3 \geq 3$$$, $$$\ldots$$$, $$$t_k \geq k$$$ is satisfied.
When dividing the robots into $$$k$$$ groups, it is optimal to have the last $$$k - 1$$$ robots in individual groups and the remaining prefix of $$$n - (k - 1)$$$ robots in one group.
Claim: There exists an optimal division such that all $$$k - 1$$$ groups other than the group containing $$$a_1$$$ will have one singular robot.
Consider a division of the robots such that a group $$$j$$$ not containing $$$a_1$$$ has more than one robot. While group $$$j$$$ has more than one robot, we can move any robot from $$$j$$$ to $$$a_1$$$'s group and not make the answer worse ($$$t_1$$$ will remain as $$$a_1$$$ and $$$t_j$$$ cannot decrease).
Now, we can move move all the singular robot groups to the end to maximize their $$$t$$$ values, while $$$t_1$$$ remains equal to $$$a_1$$$.
Using this, we can write the condition as $$$a_1 \geq 1$$$, $$$a_{n - k + 2} \geq 2$$$, $$$a_{n - k + 3} \geq 3$$$, $$$\ldots$$$, $$$a_n \geq k$$$.
Since all $$$a_i \geq 1$$$, we can replace the first condition, giving us $$$a_{n - k + 1} \geq 1$$$, $$$a_{n - k + 2} \geq 2$$$, $$$a_{n - k + 3} \geq 3$$$, $$$\ldots$$$, $$$a_n \geq k$$$. In other words, $$$a_{n - k + i} \geq i$$$ for all $$$1 \leq i \leq k$$$.
Looping through each subarray from left to right and maintaining the maximal $$$k$$$ value allows us to solve the first subtask in $$$O\left(N^3\right)$$$. We can even loop through the array once for each left subarray index while maintaining the maximum $$$k$$$ value, giving us a $$$O\left(N^2\right)$$$ solution.
To fully optimize this, we can notice that subarrays ending at the same index $$$r$$$ hold the same maximal $$$k$$$ value. To find the maximum $$$k$$$ where $$$a_{r - k + i} \geq i$$$ holds for $$$1 \leq i \leq k$$$, we can take the prefix minimum of $$$a_l + r - l$$$ among $$$1 \leq l \lt i$$$. Now we can calculate the answer for each subarray ending at $$$i$$$, which will be $$$\displaystyle\sum_{l=1}^{i}\text{min}(k, r - l + 1).$$$
Time Complexity: $$$O\left(N\right)$$$
// {{{1
extern "C" int __lsan_is_turned_off() { return 1; }
#include <bits/stdc++.h>
using namespace std;
#include <tr2/dynamic_bitset>
using namespace tr2;
#include <ext/pb_ds/assoc_container.hpp>
#define ll long long
#define inf 0x3f3f3f3f
#define infl 0x3f3f3f3f3f3f3f3fll
#include <assert.h>
#ifdef DEBUG
#define dprintf(args...) fprintf(stderr,args)
#endif
#ifndef DEBUG
#define dprintf(args...) 69
#endif
#define all(x) (x).begin(), (x).end()
struct cintype { template<typename T> operator T() { T x; cin>>x; return x; } };
// 1}}}
cintype in;
int main()
{
int n=in,L=in;vector<int>a(n);for(auto&x:a)x=in;
for(auto&x:a)x=L/x;reverse(all(a));
auto b=a;for(int i=0;i<n;i++)b[i]-=i;
for(int i=1;i<n;i++)b[i]=min(b[i],b[i-1]);
ll ans=0;
for(int i=0;i<n;i++){
int x = b[i]+i;
ll s=0;
if(i-x>=0) s+=1ll*x*(x+1)/2+1ll*(i+1-x)*x;
else s+=1ll*(i+1)*(x+x+i)/2;
ans+=s;
}
printf("%lld\n",ans);
}
Advanced F: Binary Function
Let $$$|x| = n$$$ and the digits of $$$x$$$ in binary representation be $$$x_1x_2 \dots x_{n-1}x_n$$$.
Let some $$$y$$$ such that $$$y \lt x$$$ and $$$\text{popcount}(y) \gt \text{popcount}(x)$$$ be considered beautiful.
Read the definitions. Pick some $$$k$$$ such that $$$x_k = 1$$$. Consider all $$$y$$$ that follow this form: $$$\overbrace{x_1x_2 \dots x_{k-1}}\overbrace{0}\overbrace{???\dots}$$$, where $$$?$$$ could either be $$$0$$$ or $$$1$$$. Doing this for all $$$k$$$ $$$(1 \leq k \leq n)$$$ covers all possible cases.
Let the number of $$$y$$$ that are beautiful given some $$$k$$$ that follow the form defined above be $$$f(k)$$$. Write $$$f(k)$$$ as a sum of binomial coefficients.
Draw out Pascal's triangle explicitly.
Try to find a way to transition between the sum of rows in the Pascal's triangle.
Pascal's identity?
Read the hints. Let's start from Hint $$$3$$$. Considering the range of $$$?$$$, $$$[k + 1, n]$$$, let $$$l$$$ be $$$n-k$$$ (the size of the range) and $$$\text{pc}$$$ be the number of $$$1$$$s in the range. Enumerating all $$$i \gt \text{pc}$$$,
In terms of Pascal's triangle, this is equal to a suffix sum of one of the rows. We can then observe that as $$$k$$$ decreases, the number of binomial coefficients in the summation of $$$f(k)$$$ is non-decreasing. Using Pascal's identity, which states that $$$\binom{n}{k} = \binom{n - 1}{k} + \binom{n - 1}{k - 1}$$$, we can solve the problem by enumerating $$$k$$$ in decreasing order and maintaining $$$f(k)$$$.
Let the current row sum be $$$S$$$. To transition between row $$$l - 1$$$ and row $$$l$$$, consider shifting the row $$$l - 1$$$ to the right by $$$1$$$ in Pascal's triangle. This is equal to $$$S - \binom{l - 1}{\text{pc} + 1}$$$. Then we can do this transition by adding the two values: $$$\left(2S - \binom{l - 1}{\text{pc} + 1}\right) \longrightarrow S$$$. If $$$x_k = 1$$$, increase $$$\text{pc}$$$ by $$$1$$$. If $$$x_k = 0$$$, we add $$$\binom{l}{\text{pc} + 1}$$$ to $$$S$$$ since $$$\text{pc}$$$ stays the same.
#include "bits/stdc++.h"
using namespace std;
template <typename T>
T inverse(T a, T m) {
T u = 0, v = 1;
while (a != 0) {
T t = m / a;
m -= t * a; swap(a, m);
u -= t * v; swap(u, v);
}
assert(m == 1);
return u;
}
template <typename T>
class Modular {
public:
using Type = typename decay<decltype(T::value)>::type;
constexpr Modular() : value() {}
template <typename U>
Modular(const U& x) {
value = normalize(x);
}
template <typename U>
static Type normalize(const U& x) {
Type v;
if (-mod() <= x && x < mod()) v = static_cast<Type>(x);
else v = static_cast<Type>(x % mod());
if (v < 0) v += mod();
return v;
}
const Type& operator()() const { return value; }
template <typename U>
explicit operator U() const { return static_cast<U>(value); }
constexpr static Type mod() { return T::value; }
Modular& operator+=(const Modular& other) { if ((value += other.value) >= mod()) value -= mod(); return *this; }
Modular& operator-=(const Modular& other) { if ((value -= other.value) < 0) value += mod(); return *this; }
template <typename U> Modular& operator+=(const U& other) { return *this += Modular(other); }
template <typename U> Modular& operator-=(const U& other) { return *this -= Modular(other); }
Modular& operator++() { return *this += 1; }
Modular& operator--() { return *this -= 1; }
Modular operator++(int) { Modular result(*this); *this += 1; return result; }
Modular operator--(int) { Modular result(*this); *this -= 1; return result; }
Modular operator-() const { return Modular(-value); }
template <typename U = T>
typename enable_if<is_same<typename Modular<U>::Type, int>::value, Modular>::type& operator*=(const Modular& rhs) {
#ifdef _WIN32
uint64_t x = static_cast<int64_t>(value) * static_cast<int64_t>(rhs.value);
uint32_t xh = static_cast<uint32_t>(x >> 32), xl = static_cast<uint32_t>(x), d, m;
asm(
"divl %4; \n\t"
: "=a" (d), "=d" (m)
: "d" (xh), "a" (xl), "r" (mod())
);
value = m;
#else
value = normalize(static_cast<int64_t>(value) * static_cast<int64_t>(rhs.value));
#endif
return *this;
}
template <typename U = T>
typename enable_if<is_same<typename Modular<U>::Type, long long>::value, Modular>::type& operator*=(const Modular& rhs) {
long long q = static_cast<long long>(static_cast<long double>(value) * rhs.value / mod());
value = normalize(value * rhs.value - q * mod());
return *this;
}
template <typename U = T>
typename enable_if<!is_integral<typename Modular<U>::Type>::value, Modular>::type& operator*=(const Modular& rhs) {
value = normalize(value * rhs.value);
return *this;
}
Modular& operator/=(const Modular& other) { return *this *= Modular(inverse(other.value, mod())); }
friend const Type& abs(const Modular& x) { return x.value; }
template <typename U>
friend bool operator==(const Modular<U>& lhs, const Modular<U>& rhs);
template <typename U>
friend bool operator<(const Modular<U>& lhs, const Modular<U>& rhs);
template <typename V, typename U>
friend V& operator>>(V& stream, Modular<U>& number);
private:
Type value;
};
template <typename T> bool operator==(const Modular<T>& lhs, const Modular<T>& rhs) { return lhs.value == rhs.value; }
template <typename T, typename U> bool operator==(const Modular<T>& lhs, U rhs) { return lhs == Modular<T>(rhs); }
template <typename T, typename U> bool operator==(U lhs, const Modular<T>& rhs) { return Modular<T>(lhs) == rhs; }
template <typename T> bool operator!=(const Modular<T>& lhs, const Modular<T>& rhs) { return !(lhs == rhs); }
template <typename T, typename U> bool operator!=(const Modular<T>& lhs, U rhs) { return !(lhs == rhs); }
template <typename T, typename U> bool operator!=(U lhs, const Modular<T>& rhs) { return !(lhs == rhs); }
template <typename T> bool operator<(const Modular<T>& lhs, const Modular<T>& rhs) { return lhs.value < rhs.value; }
template <typename T> Modular<T> operator+(const Modular<T>& lhs, const Modular<T>& rhs) { return Modular<T>(lhs) += rhs; }
template <typename T, typename U> Modular<T> operator+(const Modular<T>& lhs, U rhs) { return Modular<T>(lhs) += rhs; }
template <typename T, typename U> Modular<T> operator+(U lhs, const Modular<T>& rhs) { return Modular<T>(lhs) += rhs; }
template <typename T> Modular<T> operator-(const Modular<T>& lhs, const Modular<T>& rhs) { return Modular<T>(lhs) -= rhs; }
template <typename T, typename U> Modular<T> operator-(const Modular<T>& lhs, U rhs) { return Modular<T>(lhs) -= rhs; }
template <typename T, typename U> Modular<T> operator-(U lhs, const Modular<T>& rhs) { return Modular<T>(lhs) -= rhs; }
template <typename T> Modular<T> operator*(const Modular<T>& lhs, const Modular<T>& rhs) { return Modular<T>(lhs) *= rhs; }
template <typename T, typename U> Modular<T> operator*(const Modular<T>& lhs, U rhs) { return Modular<T>(lhs) *= rhs; }
template <typename T, typename U> Modular<T> operator*(U lhs, const Modular<T>& rhs) { return Modular<T>(lhs) *= rhs; }
template <typename T> Modular<T> operator/(const Modular<T>& lhs, const Modular<T>& rhs) { return Modular<T>(lhs) /= rhs; }
template <typename T, typename U> Modular<T> operator/(const Modular<T>& lhs, U rhs) { return Modular<T>(lhs) /= rhs; }
template <typename T, typename U> Modular<T> operator/(U lhs, const Modular<T>& rhs) { return Modular<T>(lhs) /= rhs; }
template<typename T, typename U>
Modular<T> power(const Modular<T>& a, const U& b) {
assert(b >= 0);
Modular<T> x = a, res = 1;
U p = b;
while (p > 0) {
if (p & 1) res *= x;
x *= x;
p >>= 1;
}
return res;
}
template <typename T>
bool IsZero(const Modular<T>& number) {
return number() == 0;
}
template <typename T>
string to_string(const Modular<T>& number) {
return to_string(number());
}
// U == std::ostream? but done this way because of fastoutput
template <typename U, typename T>
U& operator<<(U& stream, const Modular<T>& number) {
return stream << number();
}
// U == std::istream? but done this way because of fastinput
template <typename U, typename T>
U& operator>>(U& stream, Modular<T>& number) {
typename common_type<typename Modular<T>::Type, long long>::type x;
stream >> x;
number.value = Modular<T>::normalize(x);
return stream;
}
// using ModType = int;
// struct VarMod { static ModType value; };
// ModType VarMod::value;
// ModType& md = VarMod::value;
// using Mint = Modular<VarMod>;
constexpr int md = (int) 998244353;
using Mint = Modular<std::integral_constant<decay<decltype(md)>::type, md>>;
vector<Mint> fact;
vector<Mint> inv_fact;
Mint C(int n, int k) {
if (k < 0 || k > n) {
return 0;
}
if (fact.empty()) {
fact.push_back(1);
inv_fact.push_back(1);
}
while ((int) fact.size() < n + 1) {
fact.push_back(fact.back() * (int) fact.size());
inv_fact.push_back(1 / fact.back());
}
return fact[n] * inv_fact[k] * inv_fact[n - k];
}
void solve() {
int n;
string s;
cin >> s;
n = s.size();
int pc = 0;
Mint cur = 0, out = 0;
for (int i = n - 1; i >= 0; i--) {
int l = n - i - 1;
cur = 2 * cur - C(l - 1, pc + 1);
if (s[i] == '0') cur += C(l, pc + 1);
else pc++;
if (s[i] == '1') out += cur;
}
cout << out << "\n";
}
int32_t main() {
std::ios::sync_with_stdio(false);
cin.tie(NULL);
int tt;
cin >> tt;
while (tt--) {
solve();
}
}
Advanced G: Binary Function II
Rather than solve for a range $$$l...r$$$, instead solve for a range $$$1...x$$$ first.
Either way, there's two solutions: digit DP or precomputation and use math (hints and solution involve the latter.)
Solve the problem for all numbers with a fixed number of bits (e.g., all numbers less than 2^k)
A recurring theme in this approach in general would be to break up the problem into smaller chunks; solve both of those chunks and then their interaction (like divide and conquer but with bits.)
Use Vandermonde's Identity and precomputation.
Let $$$sumf(n)$$$ be the sum of $$$f(x)$$$ for $$$x=1...n-1$$$. Then, the answer would just be $$$sumf(r+1)-sumf(l)$$$. Let's see how to calculate $$$sumf(n)$$$ with the following example:
Let $$$n=10100$$$. Let set $$$A$$$ be numbers to have $$$0$$$ as their first bit ($$$00001, 00010, 00011, 00100, etc.)$$$ and set $$$B$$$ be numbers that have $$$100$$$ as their first 3 bits ($$$10000, 10001, 10010, 10011$$$). Thus, both sets satisfy the condition that they are less than $$$n$$$. We know that the every number in $$$A$$$ < every number in $$$B$$$, so now we need to find how many numbers in $$$A$$$ have a higher popcount than numbers in $$$B$$$.
Using casework and grouping, we find $$${2 \choose 0} ({4 \choose 2} + {4 \choose 3} + {4 \choose 4}) + {2 \choose 1} ({4 \choose 3} + {4 \choose 4}) + {2 \choose 2} {4 \choose 4}$$$. Since $$${n \choose k} = {n \choose {n-k}}$$$.
We can rewrite this to be: $$${2 \choose 2} ({4 \choose 2} + {4 \choose 3} + {4 \choose 4}) + {2 \choose 1} ({4 \choose 3} + {4 \choose 4}) + {2 \choose 0} {4 \choose 4}$$$.
Regrouping, we get $$$({2 \choose 2}{4 \choose 2} + {2 \choose 1}{4 \choose 3} + {2 \choose 0}{4 \choose 4}) + ({2 \choose 2}{4 \choose 3} + {2 \choose 1}{4 \choose 4}) + ({2 \choose 2}{4 \choose 4})$$$.
Applying Vandermonde's, we get: $$${6 \choose 4} + {6 \choose 5} + {6 \choose 6}$$$. This form can be generalized into: $$${n \choose k} + {n \choose k + 1} + ... + {n \choose n}$$$.
Next, we've considered the interaction between the two sets, but what about the values within the sets themselves? Well, since all the numbers in a set share the same prefix, we only have to worry about their suffix because the prefix shares the number of 1s. This is now no different than solving $$$sumf(2^k)$$$ where there are $$$2^k$$$ numbers in the set. To do that, we use a similar technique in breaking up the sets into two smaller sets: numbers that start with $$$0$$$ and numbers that start with $$$1$$$. Let this function be considered $$$solvepart(k)$$$
For instance, consider $$$k=4$$$.
0000 1000
0001 1001
0010 1010
0011 1011
0100 1100
0101 1101
0110 1110
0111 1111
Within each set, $$$\sum{f(x)} = solvepart(k-1)$$$. To find the interaction, the calculation is almost identical to the previous and we use Vandermonde's identity to simplify. Then, $$$solvepart(k)=2 \cdot solvepart(k-1) + \sum_{x=k+1}^{2k-2}{{2k-2} \choose {x}}$$$.
Combining everything together, we create a new set for every time there is a 1 bit by finding numbers that share the prefix but turn that bit into a 0. Then, we calculate the individual contribution of that set. Next, for each pair of sets, we calculate their interaction, and summing everything together would get the final answer. To speed up the process, I precomputed consecutive summations of combinations. My solution alters $$$solvepart$$$ just a bit by changing $$$k$$$ to $$$k-1$$$, but it works the same way.
#include <iostream>
#include <vector>
#include <functional>
#include <string>
#include <cmath>
using namespace std;
const int MOD = 998244353;
const int MAX_N = 1010;
vector<long long> factorial(2 * MAX_N + 1, 1);
void precompute_factorials() {
for (int i = 1; i <= 2 * MAX_N; ++i) {
factorial[i] = factorial[i - 1] * i % MOD;
}
}
long long pow_(long long a, long long b) {
if (b == 0) return 1;
long long res = pow_(a, b / 2);
if (b % 2 == 0) return res * res % MOD;
else return res * res % MOD * a % MOD;
}
long long inv(long long x) {
return pow_(x, MOD - 2);
}
long long C(int n, int k) {
return factorial[n] * inv(factorial[n - k] * factorial[k] % MOD) % MOD;
}
vector<vector<long long>> precomp(2 * MAX_N + 1);
long long solve_part[MAX_N + 1];
void precompute() {
for (int n = 0; n <= 2 * MAX_N; ++n) {
vector<long long> arr;
for (int k = n; k >= 0; --k) {
if (!arr.empty()) arr.push_back((arr.back() + C(n, k)) % MOD);
else arr.push_back(C(n, k) % MOD);
}
precomp[n] = vector<long long>(arr.rbegin(), arr.rend());
}
for (int i = 2; i <= MAX_N; i++) {
solve_part[i] = precomp[2 * i][i + 2];
solve_part[i] += 2 * solve_part[i - 1] % MOD;
solve_part[i] %= MOD;
}
}
long long sum_f(const string &x) {
long long res = 0;
vector<pair<int, int>> pairs;
int count = 0;
for (int i = x.size() - 1; i >= 0; --i) {
if (x[i] == '1') {
if (x.size() - i - 2 >= 0) res += solve_part[x.size() - i - 2]; res %= MOD;
pairs.emplace_back(x.size() - i - 1, count);
count++;
}
}
for (size_t i = 0; i < pairs.size(); ++i) {
for (size_t j = i + 1; j < pairs.size(); ++j) {
int a = pairs[i].first, d1 = pairs[i].second;
int b = pairs[j].first, d2 = pairs[j].second;
int n = a + b;
int min_k = a + abs(d1 - d2) + 1;
if (min_k <= n) {
res += precomp[n][min_k];
res %= MOD;
}
}
}
return res;
}
void binIncr(string& bin) {
int n = bin.length();
for (int i = n - 1; i >= 0; i--) {
if (bin[i] == '0') {
bin[i] = '1'; return;
} else bin[i] = '0';
} bin = '1' + bin;
}
int main() {
ios::sync_with_stdio(false); cin.tie(nullptr);
precompute_factorials();
precompute();
int t = 1;
while (t--) {
string l, r;
cin >> l >> r;
binIncr(r);
cout << (sum_f(r) - sum_f(l) + MOD) % MOD << '\n';
}
return 0;
}
Advanced H: Permutation Composition
To make the solution cleaner, $$$a_x$$$ and $$$b_x$$$ will be written as $$$a(x)$$$ and $$$b(x)$$$, respectively. $$$a(x)$$$ and $$$b(x)$$$ will only refer to the original functions given as input, while $$$a'(x)$$$ and $$$b'(x)$$$ will refer to the functions after applying all the operations.
Read the definitions. Explicitly write out what $$$a'(x)$$$ and $$$b'(x)$$$ in terms of $$$a(x)$$$ and $$$b(x)$$$.
$$$a'(x)=a(b(a(\cdots(a(x))\cdots)$$$ and $$$b'(x)=b(a(b(\cdots(b(x))\cdots)$$$ for some repeated number of $$$a(b(x))$$$ compositions.
Think about how to maintain the number of $$$a(b(x))$$$ compositions.
Think about the permutation cycles of $$$a(x)$$$ and $$$b(x)$$$. What happens to these cycles after many operations?
Read the hints. Let's start from Hint $$$3$$$. Letting $$$a(b(x))=f(x)$$$, we can express $$$a'(x)=f^p(a(x))$$$ and $$$b'(x)=b(f^q(x))$$$, where $$$p$$$ and $$$q$$$ are initially both $$$0$$$.
We will now consider what happens to $$$p$$$ and $$$q$$$ after applying operations. Applying an operation of Type 1 maps $$$(p,q)\rightarrow (2p+q,q)$$$ while applying an operation of Type 2 maps $$$(p,q)\rightarrow (p,2p+q)$$$. We essentially need to compute $$$f^k(x)$$$ for extremely large values of $$$k$$$.
Unfortunately, we can not directly maintain the value of $$$f^k(x)$$$, use a normal binary exponentiation, or even maintain the value of $$$p$$$ and $$$q$$$ due to their immense size. However, since $$$f(x)$$$ is a permutation, we can simply consider its cycle decomposition. For each individual cycle in the permutation, we must only find $$$p_{final}$$$ and $$$q_{final}$$$ under modulo of the size of that cycle.
It turns out there can only be at most $$$\mathcal{O}(\sqrt n)$$$ distinct cycle sizes, a well known lemma. We can maintain $$$p \mod M$$$ and $$$q \mod M$$$ separately for each $$$M$$$ that is the size of a cycle in $$$\mathcal{O}(\text{cycles} \cdot q) = \mathcal{O}(q\sqrt{n})$$$. This is now possible due to the limited size of $$$p \mod M$$$ and $$$q \mod M$$$. We can then compute $$$f^p(x)$$$ and $$$f^q(x)$$$ quickly by referring to $$$p \mod M$$$ and $$$q \mod M$$$ where $$$M$$$ is the size of $$$x$$$'s cycle in $$$f(x)$$$.
Time Complexity: $$$\mathcal{O}(n+q\sqrt{n})$$$.
#include <iostream>
#include <vector>
#include <map>
using namespace std;
int main(){
int n;
cin >> n;
int a [n+1];
int b [n+1];
for(int i = 1; i <= n; i++){
cin >> a[i];
}
for(int i = 1; i <= n; i++){
cin >> b[i];
}
int q;
cin >> q;
vector <bool> ops;
for(int qt = 0; qt < q; qt++){
int s;
cin >> s;
if(s == 1){
ops.push_back(false);
}else{
ops.push_back(true);
}
}
bool vis [n+1];
int a2 [n+1];
int b2 [n+1];
for(int i = 1; i <= n; i++){
vis[i] = false;
}
pair<int,int> mp [n+1];
for(int i = 1; i <= n; i++){
mp[i] = make_pair(-1, -1);
}
for(int i = 1; i <= n; i++){
if(!vis[i]){
int cur = i;
vector <int> aside;
vector <int> bside;
do{
aside.push_back(cur);
bside.push_back(a[cur]);
cur = b[a[cur]];
vis[cur] = true;
}while(cur != i);
int cyc = 2 * aside.size();
int len = aside.size();
if(mp[len] == make_pair(-1, -1)){
int ashift = 1;
int bshift = 1;
for(int j = 0; j < q; j++){
if(ops[j]){
bshift = (2 * bshift + ashift)%cyc;
}else{
ashift = (2 * ashift + bshift)%cyc;
}
}
mp[len] = make_pair(ashift, bshift);
}
int ashift = mp[len].first/2;
int bshift = mp[len].second/2 + 1;
for(int j = 0; j < aside.size(); j++){
a2[aside[j]] = bside[(j+ashift)%len];
b2[bside[j]] = aside[(j+bshift)%len];
}
}
}
for(int i = 1; i <= n; i++){
cout << a2[i] << " ";
}
cout << endl;
for(int i = 1; i <= n; i++){
cout << b2[i] << " ";
}
cout << endl;
}
Advanced I: Permutation Online
Try solving the $$$K = 1$$$ subtask.
A monotonic stack can solve $$$K = 1$$$.
A monotonic stack works for $$$K = 1$$$, since for an element, if there is another element with a higher index and value, that element does not need to be checked anymore. This saves a lot of computation.
When does an element not need to be checked anymore in the general case?
We will start from the monotonic stack approach. The optimization is that for each element in the stack, if a larger element enters, that smaller element does not need to be checked anymore and can be removed. However, for larger $$$K$$$, this doesn't work, as that element could still be a candidate for the second-largest index for future indices, so we can't pop it just yet.
However, if $$$K$$$ larger elements show up, that element can be removed. Note that for an element, if there are $$$K$$$ elements with higher index and greater value, that element can't be a candidate to be one of the $$$K$$$ largest indices anymore, and thus does not need to be checked.
This observation motivates modifying the monotonic stack approach by giving each element $$$K$$$ lives and removing elements once they reach zero lives.
When we process a new element, we scan through the previous elements in descending order of index. If the new element is larger than a previous element, instead of getting removed, the previous element loses a life and is removed if it has no more lives left. Otherwise, the previous element is greater and is thus part of the answer.
However, we can't use a stack anymore, since we need to scan and remove elements that are deeper in the structure. To do this, we can use a linked list.
Miraculously, this is amortized $$$O(NK)$$$, as there are $$$NK$$$ lives total to remove, and there are $$$NK$$$ operations spent on adding an index to the answer.
#include <iostream>
#define ll long long
using namespace std;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int N, K, O;
cin >> N >> K >> O;
ll w [K];
ll a [N+1];
ll lives [N];
ll prev [N];
for(int i = 1; i <= N; i++){
lives[i] = K;
}
for(int i = 0; i < K; i++){
cin >> w[i];
}
ll last = 0;
for(int i = 1; i <= N; i++){
cin >> a[i];
if(O == 1){
a[i] = (last + a[i])%N + 1;
}
prev[i] = i-1;
ll ans = 0;
int pcu = i;
int cur = i-1;
int ind = 0;
while(cur != 0){
if(a[cur] > a[i]){
ans += w[ind] * (cur);
ind++;
if(ind == K){
break;
}
}else{
lives[cur]--;
if(lives[cur] == 0){
prev[pcu] = prev[cur];
cur = pcu;
}
}
pcu = cur;
cur = prev[cur];
}
last = ans;
cout << ans << ' ';
}
}
Advanced J: Triangle Constructive
Some intuition about rectangular 2D prefix sums can help.
The solution uses $$$O(log(N))$$$ operations.
Try to see if you can reduce the triangular region to a new triangular region that is half as large.
You can use a method similar to 2D prefix sums to add a constant $$$c$$$ to any parallelogram using at most $$$4$$$ operations. Call this a parallelogram operation. (As opposed to a regular operation, which the parallelogram must have one vertex at a corner)

Now, we will consider the problem of adding a constant $$$c$$$ to a triangular region. (A more generalized form of adding $$$1$$$ to a triangular region.)
If we apply three parallelogram operations as follows, most of the triangular region has $$$c$$$ added to it, but the overlap of the parallelograms has $$$3c$$$ added to it.
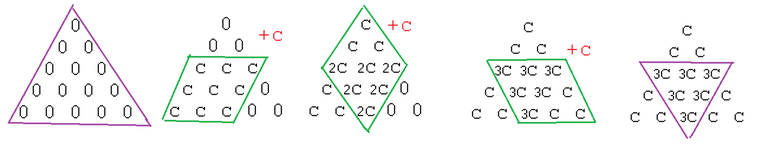
Notice that overlap of the parallelograms is also a triangular region, but with about half the side length. Thus, we have reduced the problem to adding $$$-2c$$$ to a smaller triangular region. We can recursively solve that problem using the same method, and keep going until the triangular region is sufficiently small.
It takes 3 parallelogram operations, and thus 12 normal operations for each reduction. Thus, this solution takes about $$$12 \cdot log_2(N) \approx 360$$$ operations, which is easily under the limit of $$$1000$$$.
#include <iostream>
#include <vector>
#define ll long long
using namespace std;
struct op{
char type;
int a;
int b;
ll c;
op(char type_, int a_, int b_, ll c_){
type = type_;
a = a_;
b = b_;
c = c_;
}
};
vector <op> ops;
void X(int y, int z, ll c){
if(y >= 0 && z >= 0){
ops.push_back(op('X', y, z, c));
}
}
void Y(int z, int x, ll c){
if(z >= 0 && x >= 0){
ops.push_back(op('Y', z, x, c));
}
}
void Z(int x, int y, ll c){
if(x >= 0 && y >= 0){
ops.push_back(op('Z', x, y, c));
}
}
void pX(int ly, int lz, int ry, int rz, ll c){
X(ly-1, lz-1, c);
X(ly-1, rz, -c);
X(ry, lz-1, -c);
X(ry, rz, c);
}
void pY(int lz, int lx, int rz, int rx, ll c){
Y(lz-1, lx-1, c);
Y(lz-1, rx, -c);
Y(rz, lx-1, -c);
Y(rz, rx, c);
}
void pZ(int lx, int ly, int rx, int ry, ll c){
Z(lx-1, ly-1, c);
Z(lx-1, ry, -c);
Z(rx, ly-1, -c);
Z(rx, ry, c);
}
void solve(int n, int qx, int qy, int qz, ll c){
//cout << qx << " " << qy << " " << qz << endl;
if((qx + qy + qz) == n){
pX(qy, qz, qy, qz, c);
}else if((qx + qy + qz) > n){
int size = (qx + qy + qz) - n;
pX(qy - size/2, qz - size/2, qy, qz, c);
pY(qz - size/2, qx - size/2, qz, qx, c);
pZ(qx - size/2, qy - size/2, qx, qy, c);
if(size != 1){
solve(n, qx - size/2, qy - size/2, qz - size/2, -2 * c);
}
}else if((qx + qy + qz) < n){
int size = n - (qx + qy + qz);
pX(qy, qz, qy + size/2, qz + size/2, c);
pY(qz, qx, qz + size/2, qx + size/2, c);
pZ(qx, qy, qx + size/2, qy + size/2, c);
if(size != 1){
solve(n, qx + size/2, qy + size/2, qz + size/2, -2 * c);
}
}
}
int main()
{
int n, qx, qy, qz;
cin >> n >> qx >> qy >> qz;
solve(n, qx, qy, qz, 1);
cout << ops.size() << endl;
for(int i = 0; i < ops.size(); i++){
cout << ops[i].type << " " << ops[i].a << " " << ops[i].b << " " << ops[i].c << endl;
}
return 0;
}
Advanced K: Bocchi The Tour
How would we solve this if we knew how to find the component Bocchi visits each time quickly?
What if we think about the problem as adding 1 to each city she visits and subtracting 1 once they become exciting again? How would we answer the queries?
To transform the queries from component queries to range queries, we can first use a technique called Kruskal Reconstruction Tree. We build a tree where each of the leaves initially isolated, each representing a node in the original graph. Then we can begin adding edges in ascending order, similar to Kruskal's MST algorithm (and hence the name!) We represent our original edges connecting nodes $$$u$$$ and $$$v$$$ with dummy nodes who's value equals the edge weight in our new tree that become the "head" of nodes $$$u$$$ and $$$v$$$. Then, when we want to connect another node $$$w$$$ to node $$$u$$$, we create another dummy node to connect the head of $$$u$$$ to $$$w$$$.
Now for each query, we can simply perform binary lifting to find the highest dummy node who's value is still less than or equal to $$$s_i.$$$ This represents the component Bocchi will visit because we know all nodes in the current subtree are actually edges of weight less than or equal to $$$s_i$$$, and the leaves are the original nodes that she can reach without going through an edge greater than $$$s_i$$$!
To actually answer the queries, we can instead think about marking every node in the component we found with a $$$"+1",$$$ and then marking every node with a $$$"-1"$$$ after $$$k$$$ weeks. Then the answer to each query will just be the number of nodes who's currently marked with $$$0.$$$
In order to quickly do this, we do a Euler tour to take our subtree and flatten it into an array, allowing us to use a lazy segment tree to efficiently update and query for our answer.
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
const int MAXN = 2e5 + 5;
const int LOG = 19;
const int INF = 1e9 + 7;
int n, q, k;
int a[MAXN], b[MAXN], w[MAXN];
int ord[MAXN];
int par[MAXN];
int up[MAXN][LOG];
int timer = 1;
int tin[MAXN], tout[MAXN];
vector<int> adj[MAXN];
struct Query {
int l, r, d;
};
Query queries[MAXN];
bool comp(int a, int b) {
return w[a] < w[b];
}
struct Node {
int cnt, mn, lazy;
Node() : mn{INF}, cnt{0}, lazy{0} {}
};
Node tree[4 * MAXN];
Node merge(Node a, Node b) {
Node ret;
ret.mn = min(a.mn, b.mn);
if(ret.mn == a.mn) ret.cnt += a.cnt;
if(ret.mn == b.mn) ret.cnt += b.cnt;
return ret;
}
void push(int u) {
tree[2 * u].lazy += tree[u].lazy; tree[2 * u].mn += tree[u].lazy;
tree[2 * u + 1].lazy += tree[u].lazy; tree[2 * u + 1].mn += tree[u].lazy;
tree[u].lazy = 0;
}
Node query(int u, int l, int r, int ql, int qr) {
if(r < ql || l > qr) return {};
if(ql <= l && r <= qr) return tree[u];
push(u);
int mid = (l + r) / 2;
return merge(query(2 * u, l, mid, ql, qr), query(2 * u + 1, mid + 1, r, ql, qr));
}
void update(int u, int l, int r, int ql, int qr, int x) {
if(r < ql || l > qr) return;
if(ql <= l && r <= qr) {
tree[u].lazy += x; tree[u].mn += x;
return;
}
push(u);
int mid = (l + r) / 2;
update(2 * u, l, mid, ql, qr, x); update(2 * u + 1, mid + 1, r, ql, qr, x);
tree[u] = merge(tree[2 * u], tree[2 * u + 1]);
}
void build(int u, int l, int r) {
if(l == r) {
tree[u].mn = 0; tree[u].cnt = 1;
return;
}
int mid = (l + r) / 2;
build(2 * u, l, mid); build(2 * u + 1, mid + 1, r);
tree[u] = merge(tree[2 * u], tree[2 * u + 1]);
}
void euler(int u) {
tin[u] = timer;
if(adj[u].size() == 0) ++timer;
for(auto v : adj[u]) euler(v);
tout[u] = timer - 1;
}
int find(int u) {
if(u == par[u]) return u;
return par[u] = find(par[u]);
}
int main() {
cin.tie(0)->sync_with_stdio(false);
cin >> n >> q >> k;
for(int i = 0; i < MAXN; ++i) par[i] = i;
for(int i = 1; i < n; ++i) {
cin >> a[i] >> b[i] >> w[i];
ord[i] = i;
}
sort(ord + 1, ord + n, comp);
for(int i = 1; i < n; ++i) {
int u = find(a[ord[i]]), v = find(b[ord[i]]);
par[u] = par[v] = up[u][0] = up[v][0] = ord[i] + n;
}
for(int i = 1; i <= 2 * n; ++i) adj[up[i][0]].push_back(i);
int krtroot = ord[n - 1] + n;
up[krtroot][0] = krtroot;
euler(krtroot);
for(int j = 0; j < LOG - 1; ++j) {
for(int i = 1; i < 2 * n; ++i) {
up[i][j + 1] = up[up[i][j]][j];
}
}
build(1, 1, n);
int idx = 0;
for(int i = 1; i <= q; ++i) {
int d, u, s; cin >> d >> u >> s;
for(int j = LOG - 1; j >= 0; --j) {
if(w[up[u][j] - n] <= s) u = up[u][j];
}
queries[i] = {tin[u], tout[u], d};
while(queries[idx].d + k <= d) {
update(1, 1, n, queries[idx].l, queries[idx].r, -1);
++idx;
}
Node ret = query(1, 1, n, queries[i].l, queries[i].r);
if(ret.mn != 0) cout << 0 << endl;
else cout << ret.cnt << endl;
update(1, 1, n, queries[i].l, queries[i].r, 1);
}
}
Advanced L: Can you Count?
Denote $$$S_{n,m,k}=\displaystyle\sum_{1\le a_i\le m}\left(\displaystyle\sum^{n}_{i=1}a_i\right)^k$$$. Find a closed form for the exponential generating function
The answer is $$$S_{n,m,k}-\displaystyle \sum^{k}_{j=0} (-1)^{k-j}\binom{k}{j}S_{n,m,j}$$$.
By algebra,
For a fixed sum $$$s$$$, the number of arrays $$$b$$$ of length $$$k$$$ such that $$$\max^k_{j=1} = s$$$ is precisely the number of arrays $$$b$$$ with each element at most $$$s$$$ minus the number of arrays $$$b$$$ with each element almost $$$s-1$$$, which is equal to $$$s^k-(s-1)^k=s^k-\displaystyle\sum^{k}_{j=0} (-1)^{k-j}\binom{k}{j}s^j$$$. Hence, the total number of pairs $$$(a,b)$$$, which we denote as $$$p_{n,m,k}$$$. is given by
as mentioned in Hint $$$2$$$.
Let $$$P(x)=\displaystyle\sum^{\infty}_{k=0} p_{n,m,k}x^k$$$ and $$$Q(x)=\displaystyle\sum^{\infty}_{k=0} S_{n,m,k}x^{k\color{red}{+1}}$$$. We find
Let $$$K$$$ be the maximum $$$k_i$$$ queried. We need the values of $$$S_{n,m,0},S_{n,m,1},...,S_{n,m,K}$$$. Hence, we need to extract the coefficients up to $$$x^K$$$ term in
Division up till $$$x^K$$$ term can be done in $$$O(K\log K)$$$. Taking $$$S(x)=\frac{1-e^{mx}}{e^{-x}-1}$$$ to the $$$n$$$-th power is equivalent to computing $$$e^{n\ln S(x)}$$$. Since exponentiation and logarithms up till $$$x^K$$$ term can also be done in $$$O(K\log K)$$$, all of $$$S_{n,m,0},S_{n,m,1},...,S_{n,m,K}$$$ can be extracted in $$$O(K\log K)$$$. We substitute those values in to find $$$Q(x)$$$ up till $$$x^{K+1}$$$ term. Terms of $$$Q\left(\frac{x}{1+x}\right)=Q\left(1-\frac{1}{1+x}\right)$$$ up till $$$x^{K+1}$$$ can also be obtained in $$$O(K\log K)$$$ time from $$$Q(x)$$$ by doing the compositions $$$Q(x)\circ (1+x)\circ x^{-1}\circ (-x)\circ (1+x)$$$. Hence, terms of $$$P(x)$$$ up till $$$x^K$$$ can be obtained in $$$O(K\log K)$$$ time, and for each query on $$$k_i$$$ just return the coefficient of $$$x^{k_i}$$$ in $$$P(x)$$$.
Time complexity: $$$O(q+K \log K)$$$ where $$$K$$$ is the maximum $$$k_i$$$ queried.
Partial scores:
$$$q=1$$$ and $$$k_i\le 2\cdot 10^4$$$: See below.
$$$q=1$$$: Allows computing $$$p_{n,m,k}=S_{n,m,k}-\displaystyle \sum^{k}_{j=0} (-1)^{k-j}\binom{k}{j}S_{n,m,j}$$$ naively after obtaining the values of $$$S_{n,m,0},S_{n,m,1},...,S_{n,m,k}$$$. Time complexity is $$$O(K \log K)$$$.
$$$k_i\le 2\cdot 10^4$$$: Allows binary lifting to take $$$n$$$-th power. Time complexity is $$$O(q+K \log K\log N)$$$.
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int MOD=998244353;
const int lim=200010; // *
int fact[lim+1],ifact[lim+1],inve[lim+1]; // *
vector <int> root={31},iroot; // #
// * denotes factorial related functions
// # denotes ntt related functions
// $ denotes more gen func stuff
// delete if not needed
int mod(int a){
a%=MOD; a+=MOD; a%=MOD;
return a;
} // use when stuff might get negative
int bigmod(int a,int k){
int ans=1,powa=a;
while(k){
if(k&1) ans=ans*powa%MOD;
powa=powa*powa%MOD;
k>>=1;
}
return ans;
}
void init_fact(){
fact[0]=1;
for(int i=1;i<=lim;i++){
fact[i]=fact[i-1]*i%MOD;
}
ifact[lim]=bigmod(fact[lim],MOD-2);
for(int i=lim;i>=1;i--){
ifact[i-1]=ifact[i]*i%MOD;
}
inve[0]=0;
for(int i=1;i<=lim;i++){
inve[i]=fact[i-1]*ifact[i]%MOD;
}
return;
} // *
int nCr(int n,int r){
if(n<0||r<0||r>n) return 0;
return fact[n]*ifact[r]%MOD*ifact[n-r]%MOD;
} // *
int inCr(int n,int r){
if(n<0||r<0||r>n) return 0;
return ifact[n]*fact[r]%MOD*fact[n-r]%MOD;
} // *
void init_ntt(){
iroot.push_back(bigmod(root[0],MOD-2));
int ptr=0;
while(root[ptr]!=1){
root.push_back(root[ptr]*root[ptr]%MOD);
iroot.push_back(iroot[ptr]*iroot[ptr]%MOD);
ptr++;
}
return;
} // #
void ntt(vector <int> &f,bool inv){
int n=f.size();
int i=1,j=0,ptr=root.size()-1,s=1;
while(i<n){
if(i==s){
s<<=1;
ptr--;
}
int bit=(n>>1);
while(j&bit){
j^=bit;
bit>>=1;
}
j^=bit;
if(i<j) f[i]^=f[j]^=f[i]^=f[j];
i++;
}
int mult=inv?root[ptr]:iroot[ptr];
int poww[n]={1};
for(int k=1;k<n;k++) poww[k]=poww[k-1]*mult%MOD;
int k=1,jmp=n>>1;
for(int K=2;K<=n;K<<=1){
for(int L=0;L<n;L+=K){
int idx=0;
for(int l=L;l<(L^k);l++){
int u=f[l],v=f[l^k]*poww[idx]%MOD;
f[l]=u+v; if(f[l]>MOD) f[l]-=MOD;
f[l^k]=u-v; if(f[l^k]<0) f[l^k]+=MOD;
idx+=jmp;
}
}
k=K; jmp>>=1;
}
if(inv){
int in=bigmod(n,MOD-2);
for(int k=0;k<n;k++) f[k]=in*f[k]%MOD;
}
}
vector <int> conv(vector<int> f,vector<int> g){
int k=f.size()+g.size()-1,n=1;
while(n<k) n<<=1;
f.resize(n,0); g.resize(n,0);
ntt(f,0); ntt(g,0);
for(int i=0;i<n;i++) f[i]=f[i]*g[i]%MOD;
ntt(f,1);
return {f.begin(),f.begin()+k};
} // #
vector <int> add(vector<int> f,vector<int> g){
int k=max(f.size(),g.size());
f.resize(k,0);
g.resize(k,0);
for(int i=0;i<k;i++){
f[i]+=g[i];
if(f[i]>MOD) f[i]-=MOD;
}
return f;
} // $
vector <int> neg(vector<int> f){
int k=f.size();
for(int i=0;i<k;i++){
f[i]=(f[i])?(MOD-f[i]):0;
}
return f;
} // $
vector <int> inverse(vector<int> f){
vector<int> ret={bigmod(f[0],MOD-2)};
int k=f.size();
f=neg(f);
while(ret.size()<k){
int d=ret.size()*2;
if(k<d) f.resize(d);
vector <int> temp=conv({f.begin(),f.begin()+d},ret);
temp[0]+=2;
if(temp[0]>MOD) temp[0]-=MOD;
ret=conv({temp.begin(),temp.begin()+d},ret);
ret={ret.begin(),ret.begin()+d};
}
return {ret.begin(),ret.begin()+k};
} // $
vector <int> divide(vector<int> f,vector<int> g){
int k=max(f.size(),g.size());
f.resize(k,0);
g.resize(k,0);
f=conv(f,inverse(g));
return {f.begin(),f.begin()+k};
} // $
vector <int> derivative(vector<int> f){
int k=f.size();
if(k==1) return {0};
vector <int> ret(k-1);
for(int i=1;i<k;i++){
ret[i-1]=f[i]*i%MOD;
}
return ret;
} // $
vector <int> integrate(vector<int> f){
int k=f.size();
vector <int> ret(k+1); ret[0]=0;
for(int i=1;i<k;i++){
ret[i]=f[i-1]*inve[i]%MOD;
}
return ret;
} // $
vector <int> ln(vector<int> f){
int k=f.size();
vector <int> ret=integrate(divide(derivative(f),f));
return {ret.begin(),ret.begin()+k};
} // $
vector <int> expo(vector<int> f){
vector<int> ret={1};
int k=f.size();
while(ret.size()<k){
int d=ret.size()*2;
if(k<d) f.resize(d);
vector <int> temp={f.begin(),f.begin()+d};
ret.resize(d,0);
temp=add(temp,neg(ln(ret)));
temp[0]+=1;
if(temp[0]>MOD) temp[0]-=MOD;
ret=conv(temp,ret);
ret={ret.begin(),ret.begin()+d};
}
return {ret.begin(),ret.begin()+k};
} // $
vector <int> ead(vector <int> f,int a){
vector <int> g;
int n=f.size()-1,powa=1;
g.resize(n+1);
for(int i=0;i<=n;i++){
f[i]=f[i]*fact[i]%MOD;
g[n-i]=powa*ifact[i]%MOD;
powa=powa*a%MOD;
}
g=conv(f,g);
for(int i=0;i<=n;i++) g[n+i]=g[n+i]*ifact[i]%MOD;
return {g.begin()+n,g.end()};
} // $
void solve(){
int n,m,q,k=200010;
cin >> n >> m >> q;
vector <int> f(k),g(k);
int powm=1;
bool neg=0;
for(int i=0;i<k;i++){
powm=powm*m%MOD; neg=!neg;
f[i]=MOD-powm*ifact[i+1]%MOD;
g[i]=(neg)?(MOD-ifact[i+1]):ifact[i+1];
}
f=divide(f,g);
f=ln(f);
for(int i=0;i<k;i++){
f[i]=f[i]*n%MOD;
}
f=expo(f);
int mult=bigmod(m,n);
for(int i=0;i<k;i++){
f[i]=f[i]*mult%MOD;
}
neg=0;
cout << '\n';*/
f.resize(k+1);
for(int i=k;i>0;i--){
f[i]=f[i-1]*fact[i-1]%MOD;
}
f[0]=0;
cout << '\n';*/
vector <int> P=ead(f,1),Q(k+1);
for(int i=1;i<=k;i+=2){
if(P[i]>0) P[i]=MOD-P[i];
}
reverse(P.begin(),P.end());
P=ead(P,1);
int curc=1;
for(int i=0;i<=k;i++){
if(i){
curc=MOD-curc*(k+i-1)%MOD;
}
Q[i]=curc;
}
curc=ifact[k];
for(int i=k;i>=0;i--){
Q[i]=Q[i]*curc%MOD;
curc=curc*i%MOD;
}
P=conv(P,Q);
for(int i=0;i<k;i++){
f[i]=f[i+1]-P[i+1];
if(f[i]<0) f[i]+=MOD;
}
for(int i=0;i<q;i++){
int K; cin >> K;
cout << f[K] << ' ';
}
}
int32_t main(){
ios_base::sync_with_stdio(0);
cin.tie(0); cout.tie(0);
init_fact(); // *
init_ntt(); // #
int t=1;
while(t--){
solve();
}
}


