


See https://twitter.com/cHHillee/status/1732868066558792189 for the original tweet. Contents mimicked below.
TL;DR: I found AlphaCode2 accounts, and through stalking their submission history, I manually performed the AlphaCode2 Codeforces evals, and found the model to perform at about a ~1650 rating.
I am somewhat concerned about data leakage, see https://twitter.com/cHHillee/status/1732636161204760863. This is an AlphaCode2 contributor's response https://twitter.com/RemiLeblond/status/1732677521290789235 However, for the purposes of this analysis I'll take the results at face value.
Methodology
Disclaimer: I'm trying to reverse-engineer info from their public submissions, so apologies in advance for any errors.
There is a fixed set of 12 contests that they submit to. When they kick off a "run" they submit to these contests from several accounts at a time.
As far as I can tell they didn't do extensive evals on other contests. They performed most of their evaluation between the middle of october and november, and they repeatedly eval on the same set of contests.
Identifying their accounts is pretty easy. They all have the form <noun, usually animal>.
To find a full "eval" run, I found a particular time that they started submitting. For example, October 25th around 10pm. Generally, there are at least 10 submissions for every problem across all accounts. I then went down all submissions done to the contest, and noted down which submissions were made by AC2 accounts around the time.
For each contest, I note down whether any of the accounts solved it and how many incorrect submissions they had before the first accepted submission.
For example, for 1810, they solved A,B,C, and G. B took 6 incorrect submissions before acceptance.
As you folks know, Codeforces also has a penalty (either less points or a completely separate penalty score) depending on the submission time + # of incorrect submissions. I compute the penalty using the approach mentioned in the paper, where AC2 makes submissions throughout the contest. I also compute a penalty assuming instant submission, since in some sense, AC2 having a "speed edge" is fair when comparing it against humans.
Then, for the given score/results for the model, I manually expect the leaderboard to find the "rating" that the model performs at. For example, for contest 1837 3 problems solved + 118 penalty results in a 1104 rating.
Overall, after repeating this procedure for 11 (I skipped one contest) of the contests, I arrive at a final rating of 1630 with 43% of the problems solved! This is a 400 rating improvement over the original AlphaCode2.
This is already better than many humans, which is pretty impressive.
One concern I had about this eval is whether this "run" actually represented their performance, or whether it was using a worse model or something like that for this run. So, for every problem that wasn't solved, I checked whether there were any AlphaCode2 submissions that solved the problem. There were only 2 problems that AlphaCode2 ever solved that this particular run didn't. And those runs failed on other problems.
Concerns
Now, some hesitance. The first is the reliance on pretests. Codeforces provides sample inputs for each problem, and especially on easy problems, these sample inputs are often quite "strong" and informative.
AlphaCode2 submits a lot of wrong answers.
And these submissions already pass the pretest! I would expect that on problems without informative pretests (quite common among harder ratings or say, constructive problems) AC2's performance suffers drastically.
For example, no AC2 run solved this 1200 rated problem (https://mirror.codeforces.com/contest/1834/problem/C) and not for a lack of trying. I'm guessing because the pretests weren't informative enough for the filtering to work well.
In addition, it doesn't solve many hard problems. Other than the problem identified in the press release, the hardest problems it solves are a 2200, 2100, 1800 and an 1700. It solves nothing else above 1600. This is partially why solving the 3200 rated stands out so much!
Also, AC2 generally benefits quite a bit from solving problems "quickly". Compared to other contestants around its level, it's generally solving easy problems very fast.
e.g. On CF round 880, it obtains 2196 rating. But everybody down to 1640 solved the same problems.
I also find the contest selection a bit unusual. One note is that when the paper says "Div 2" and "Div 1 + 2" contests, they mean 11 Div 2 contests and a single Div 1+2 contest (which is also where AC2 solved its hardest problem).
Another question is why they chose the contests they evaled on?
My particular qualms 1. why choose a relatively old set of contests? AFAICT, the evals were performed in Oct/Nov, but the latest contest is from June. 2. Why not a contiguous set of contests? For example, contest 1844 was skipped despite doing contest 1841 and 1845.
In addition, one of the contests (https://mirror.codeforces.com/contest/1814) was declared non-rated halfway through the contest! Undoubtedly, many contestants stopped participating at this point, leading to a skewed distribution of performance.
Conclusion
Overall, great work from the AC2 team! Solid progress over AC1, although perhaps not enough that I think competitive programming will be solved imminently :)
I'd love to see more transparency (maybe a live evaluation?), but I understand their hands are tied.
And here's my datasheet where I tracked my manual eval of AlphaCode2






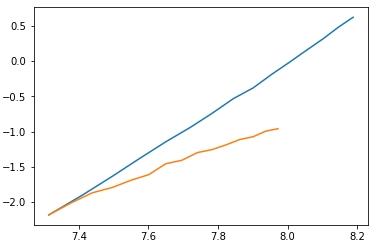 where blue is the runtime of Dinic's without scaling and orange is the runtime of Dinic's with scaling. Since the important thing to look at is the slope of the line, I normalized the lines to start at the same point.
where blue is the runtime of Dinic's without scaling and orange is the runtime of Dinic's with scaling. Since the important thing to look at is the slope of the line, I normalized the lines to start at the same point.