


В этом месте напрашивается эпиграф про удава и попугаев. Тем не менее, ниже вы найдете мою версию ответа на интригующий вопрос из заглавия теста.
Занимаясь подготовкой VK Cup 2015, мы столкнулись с интересной задачей подсчета изменений рейтингов участников в командных контестах. Сразу скажу, что таковых будет немного, и значительного вклада они не должны внести.
Коротко напомню, что рейтинги Codeforces считаются примерно так:
- у каждого участника есть какой-то рейтинг ri на начало раунда,
- так как рейтинг Codeforces наследует идеологию рейтинга Эло, то мы стремимся к оценке, что участник b побеждает участника a с вероятностью:

- зная вероятности микроматчей выиграть/проиграть для каждой пары участников, можно посчитать ожидаемое место участника i (как сумму вероятностей его проигрыша по всем остальным участникам),
- если участник i занимает место лучше ожидаемого, то надо увеличить его рейтинг, иначе — уменьшить.
Это совсем общий принцип, который покрыт противо-инфляционными поправками и некоторыми эвристиками. Кстати, у меня есть большое желание пересмотреть точные формулы с помощью сообщества, попутно сделав рейтинг публичным. Но речь сейчас не об этом, а о том как посчитать рейтинг команды.
Кажется естественной идея распространить текущий подход на командное участие. Одна из проблем — отсутствие правила для вычисления рейтинга команды, если известны рейтинги ее членов. Если бы такое правило было, скажем какая-то функция teamRatings(r1, r2), то довольно логично использовать именно это значение для вычисления ожидаемого места, а потом одинаково изменить рейтинги участников команды в зависимости от того удачным было выступление (лучше ожидаемого места) или нет (хуже ожидаемого места).
Вот такая идея пришла в голову во время обеда команды Codeforces.
Во-первых, искомая функция teamRatings(r1, r2) от рейтингов членов команды должна быть такой, что teamRatings(r1, r2) ≥ max(r1, r2). Кроме того, понятно, что если к tourist-у добавить кого-то не очень сильного (скажем, зеленого участника), то рейтинг команды не должен сильно отличаться от рейтинга tourist-а.
Мной была предложена такая забавная модель. Пусть есть команда AB из двух участников A и B. Попробуем хоть как-то сравнить ее с одиноким участником C. В моей модели вместо командного контеста A + B против C проведем пару встреч A против C и B против C. Если хотя бы в одной из таких встреч победил член команды AB, то засчитаем победу команде, иначе — участнику C.
Конечно, такой подход не учитывает какой-то совместной работы A и B, но хотя бы честно пытается учесть шансы обоих победить C. Если все три рейтинга известны, то легко посчитать вероятность победы C — это произведение вероятностей победить A и победить B. Просто дважды применим формулу Эло и перемножим результаты.
Теперь, когда известен рейтинг C и рейтинг его победы над командой, то, обратив формулу Эло, можно посчитать рейтинг команды.
Есть тонкость, что при таком подсчете рейтинг команды зависит от рейтинга противника C. Как же его выбрать? Можно показать, что при изменении C, результат меняется монотонно. Кажется красивой идея выбрать такое C, чтобы рейтинг команды в конце концов оказался ему и равен. То есть, в качестве противника команде подобрать такого, который играет с командой на равных. Это можно сделать бинпоиском, хотя, наверное, можно и вывести точную формулу (кто поможет?).
В результате получается примерно такой код:
long double getWinProbability(long double ra, long double rb) {
return 1.0 / (1.0 + pow((long double) 10.0, (rb - ra) / 400.0));
}
long double aggregateRatings(vector<long double> teamRatings)
{
long double left = 1;
long double right = 1E4;
for (int tt = 0; tt < 100; tt++) {
long double r = (left + right) / 2.0;
long double rWinsProbability = 1.0;
forn(i, teamRatings.size())
rWinsProbability *= getWinProbability(r, teamRatings[i]);
long double rating = log10(1 / (rWinsProbability) - 1) * 400 + r;
if (rating > r)
left = r;
else
right = r;
}
return (left + right) / 2.0;
}
Полный код можно посмотреть найти по ссылке http://pastebin.com/HnteNGuN
Еще раз отмечу, что какой-то абсолютно справедливой модели посчитать рейтинг команды по рейтингам ее членов мне кажется нет. У меня есть мнение, что это неплохой вариант. Что скажете?
Вот интересные примеры:
| Первый член команды | Второй член команды | Итоговый рейтинг |
|---|---|---|
| tourist, 3239 | Petr, 3045 | 3314 |
| tourist, 3239 | niyaznigmatul, 2700 | 3253 |
| tourist, 3239 | tourist, 3239 | 3392 |
| Petr, 3045 | Petr, 3045 | 3198 |
| tourist, 3239 | Bredor, 1766 | 3239 |
| Bredor, 1766 | Bredor, 1766 | 1919 |
Или вот еще интересное следствие: команда из 3350-ти Бредоров будет решать как tourist.
Заметно, что такой подход, видимо, как-то занижает рейтинг команды (или нет?). Наверное, это не очень страшно — ведь рейтинги команд будут сравниваться почти всегда с рейтингами команд (а команды из одного члена будут, возможно, получать некоторый буст).
Буду рад альтернативным моделям агрегирования рейтингов.






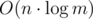 .
.
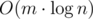 .
.







 , where
, where 









