


Hope you enjoyed the problems!
UPD 1: Added implementations!
UPD 2: It seems my wording for the solution to C is not the best, and it is causing some confusion. I've updated it to be better!
UPD 3: Implementation links didn't work for some reason, so I've just added the code directly.
Look at the distance between the frogs.
Notice that regardless of how the players move, the difference between the numbers of the lilypads the two players are standing on always alternates even and odd, depending on the starting configuration. Then, the key observation is that exactly one player has the following winning strategy:
- Walk towards the other player, and do not stop until they are forced onto lilypad $$$1$$$ or $$$n$$$.
For instance, if Alice and Bob start on lilypads with the same parity, Bob cannot stop Alice from advancing towards him. This is because at the start of Alice's turn, she will always be able to move towards Bob due to their distance being even and therefore at least $$$2$$$, implying that there is a free lilypad for her to jump to. This eventually forces Bob into one of the lilypads $$$1, n$$$, causing him to lose.
In the case that they start on lilypads with different parity, analogous logic shows that Bob wins. Therefore, for each case, we only need to check the parity of the lilypads for a constant time solution.
#include <bits/stdc++.h>
using namespace std;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(0);
int T; cin >> T;
while (T--) {
int N, A, B; cin >> N >> A >> B;
if ((A ^ B) & 1) cout << "NO\n";
else cout << "YES\n";
}
cout.flush();
return 0;
}
The order of the moves is pretty much irrelevant. What happens if we try to make two different materials?
The key observation is that we will never use the operation to craft two different types of materials $$$i, j$$$. This is because if we were to combine the net change in resources from these two operations, we would lose two units each of every material $$$k \neq i, j$$$, and receive a net zero change in our amounts of materials $$$i, j$$$. Therefore, we will only ever use the operation on one type of material $$$i$$$.
An immediate corollary of this observation is that we can only be deficient in at most one type of material, i.e. at most one index $$$i$$$ at which $$$a_i \lt b_i$$$. If no such index exists, the material is craftable using our starting resources. Otherwise, applying the operation $$$x$$$ times transforms our array to
i.e. increasing element $$$a_i$$$ by $$$x$$$ and decreasing all other elements by $$$x$$$. We must have $$$x \geq b_i - a_i$$$ to satisfy the requirement on material type $$$i$$$. However, there is also no point in making $$$x$$$ any larger, as by then we already have enough of type $$$i$$$, and further operations cause us to start losing materials from other types that we could potentially need to craft the artifact. Therefore, our condition in this case is just to check that
i.e. we are deficient in type $$$i$$$ by at most as many units as our smallest surplus in all other material types $$$j \neq i$$$. This gives an $$$O(n)$$$ solution.
// #include <ext/pb_ds/assoc_container.hpp>
// #include <ext/pb_ds/tree_policy.hpp>
// using namespace __gnu_pbds;
// typedef tree<int, null_type, std::less<int>, rb_tree_tag, tree_order_statistics_node_update> ordered_set;
#include <bits/stdc++.h>
#define f first
#define s second
#define pb push_back
typedef long long int ll;
typedef unsigned long long int ull;
using namespace std;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
template<typename T> int die(T x) { cout << x << endl; return 0; }
#define mod_fft 998244353
#define mod_nfft 1000000007
#define INF 100000000000000
#define LNF 1e15
#define LOL 12345678912345719ll
struct LL {
static const ll m = mod_fft;
long long int val;
LL(ll v) {val=reduce(v);};
LL() {val=0;};
~LL(){};
LL(const LL& l) {val=l.val;};
LL& operator=(int l) {val=l; return *this;}
LL& operator=(ll l) {val=l; return *this;}
LL& operator=(LL l) {val=l.val; return *this;}
static long long int reduce(ll x, ll md = m) {
x %= md;
while (x >= md) x-=md;
while (x < 0) x+=md;
return x;
}
bool operator<(const LL& b) { return val<b.val; }
bool operator<=(const LL& b) { return val<=b.val; }
bool operator==(const LL& b) { return val==b.val; }
bool operator>=(const LL& b) { return val>=b.val; }
bool operator>(const LL& b) { return val>b.val; }
LL operator+(const LL& b) { return LL(val+b.val); }
LL operator+(const ll& b) { return (*this+LL(b)); }
LL& operator+=(const LL& b) { return (*this=*this+b); }
LL& operator+=(const ll& b) { return (*this=*this+b); }
LL operator-(const LL& b) { return LL(val-b.val); }
LL operator-(const ll& b) { return (*this-LL(b)); }
LL& operator-=(const LL& b) { return (*this=*this-b); }
LL& operator-=(const ll& b) { return (*this=*this-b); }
LL operator*(const LL& b) { return LL(val*b.val); }
LL operator*(const ll& b) { return (*this*LL(b)); }
LL& operator*=(const LL& b) { return (*this=*this*b); }
LL& operator*=(const ll& b) { return (*this=*this*b); }
static LL exp(const LL& x, const ll& y){
ll z = y;
z = reduce(z,m-1);
LL ret = 1;
LL w = x;
while (z) {
if (z&1) ret *= w;
z >>= 1; w *= w;
}
return ret;
}
LL& operator^=(ll y) { return (*this=LL(val^y)); }
LL operator/(const LL& b) { return ((*this)*exp(b,-1)); }
LL operator/(const ll& b) { return (*this/LL(b)); }
LL operator/=(const LL& b) { return ((*this)*=exp(b,-1)); }
LL& operator/=(const ll& b) { return (*this=*this/LL(b)); }
}; ostream& operator<<(ostream& os, const LL& obj) { return os << obj.val; }
int N;
vector<ll> segtree;
void pull(int t) {
segtree[t] = max(segtree[2*t], segtree[2*t+1]);
}
void point_set(int idx, ll val, int L = 1, int R = N, int t = 1) {
if (L == R) segtree[t] = val;
else {
int M = (L + R) / 2;
if (idx <= M) point_set(idx, val, L, M, 2*t);
else point_set(idx, val, M+1, R, 2*t+1);
pull(t);
}
}
ll range_add(int left, int right, int L = 1, int R = N, int t = 1) {
if (left <= L && R <= right) return segtree[t];
else {
int M = (L + R) / 2;
ll ret = 0;
if (left <= M) ret = max(ret, range_add(left, right, L, M, 2*t));
if (right > M) ret = max(ret, range_add(left, right, M+1, R, 2*t+1));
return ret;
}
}
void build(vector<ll>& arr, int L = 1, int R = N, int t = 1) {
if (L == R) segtree[t] = arr[L-1];
else {
int M = (L + R) / 2;
build(arr, L, M, 2*t);
build(arr, M+1, R, 2*t+1);
pull(t);
}
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(0);
int T = 1; cin >> T;
while (T--) {
int N; cin >> N;
vector<int> A(N), B(N);
for (int i = 0; i < N; i++) cin >> A[i];
int bad = -1, margin = 1e9, need = 0;
bool reject = 0;
for (int i = 0; i < N; i++) {
cin >> B[i];
if (A[i] < B[i]) {
if (bad != -1) reject = 1;
bad = i;
need = B[i] - A[i];
} else {
margin = min(margin, A[i] - B[i]);
}
}
if (reject) {
cout << "NO" << endl;
continue;
} else {
cout << ((margin >= need) ? "YES" : "NO") << endl;
}
}
}
Pick $$$x$$$, and find the sum of the whole grid. What does this tell you?
Once you know $$$x$$$, the top left cell is fixed.
What about the next cell on the trail?
The naive solution of writing out a linear system and solving them will take $$$O((n + m)^3)$$$ time, which is too slow, so we will need a faster algorithm.
We begin by selecting a target sum $$$S$$$ for each row and column. If we calculate the sum of all numbers in the completed grid, summing over rows gives a total of $$$S \cdot n$$$ while summing over columns gives a total of $$$S \cdot m$$$. Therefore, in order for our choice of $$$S$$$ to be possible, we require $$$S \cdot n = S \cdot m$$$, and since it is possible for $$$n \neq m$$$, we will pick $$$S = 0$$$ for our choice to be possible in all cases of $$$n, m$$$. Notice that all choices $$$S \neq 0$$$ will fail on $$$n \neq m$$$, as the condition $$$S \cdot n = S \cdot m$$$ no longer holds. As such, $$$S = 0$$$ is the only one that will work in all cases.
Now, we aim to make each row and column sum to $$$S$$$. The crux of the problem is the following observation:
- Denote $$$x_1, x_2, \dots, x_{n+m-1}$$$ to be the variables along the path. Let's say variables $$$x_1, \dots, x_{i-1}$$$ have their values set for some $$$1 \leq i \lt n+m-1$$$. Then, either the row or column corresponding to variable $$$x_i$$$ has all of its values set besides $$$x_i$$$, and therefore we may determine exactly one possible value of $$$x_i$$$ to make its row or column sum to $$$0$$$.
The proof of this claim is simple. At variable $$$x_i$$$, we look at the corresponding path move $$$s_i$$$. If $$$s_i = \tt{R}$$$, then the path will never revisit the column of variable $$$x_i$$$, and its column will have no remaining unset variables since $$$x_1, \dots, x_{i-1}$$$ are already set. Likewise, if $$$s_i = \tt{D}$$$, then the path will never revisit the row of variable $$$x_i$$$, which can then be used to determine the value of $$$x_i$$$.
Repeating this process will cause every row and column except for row $$$n$$$ and column $$$m$$$ to have a sum of zero, with $$$x_{n+m-1}$$$ being the final variable. However, we will show that we can use either the row or column to determine it, and it will give a sum of zero for both row $$$n$$$ and column $$$m$$$. WLOG we use row $$$n$$$. Indeed, if the sum of all rows and columns except for column $$$m$$$ are zero, we know that the sum of all entries of the grid is zero by summing over rows. However, we may then subtract all columns except column $$$m$$$ from this total to arrive at the conclusion that column $$$m$$$ also has zero sum. Therefore, we may determine the value of $$$x_{n+m-1}$$$ using either its row or column to finish our construction, giving a solution in $$$O(n \cdot m)$$$.
#include <bits/stdc++.h>
#define f first
#define s second
#define pb push_back
typedef long long int ll;
typedef unsigned long long int ull;
using namespace std;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
template<typename T> int die(T x) { cout << x << endl; return 0; }
#define mod 1000000007
#define INF 1000000000
#define LNF 1e15
#define LOL 12345678912345719ll
using namespace std;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(0);
int T; cin >> T;
while (T--) {
int N, M; cin >> N >> M;
string S; cin >> S;
vector<vector<ll>> A;
for (int i = 0; i < N; i++) {
A.push_back(vector<ll>(M));
for (int j = 0; j < M; j++) {
cin >> A[i][j];
}
}
int x = 0, y = 0;
for (char c : S) {
if (c == 'D') {
long long su = 0;
for (int i = 0; i < M; i++) {
su += A[x][i];
}
A[x][y] = -su;
++x;
} else {
long long su = 0;
for (int i = 0; i < N; i++) {
su += A[i][y];
}
A[x][y] = -su;
++y;
}
}
long long su = 0;
for (int i = 0; i < M; i++) {
su += A[N-1][i];
}
A[N-1][M-1] = -su;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
cout << A[i][j] << " ";
}
cout << endl;
}
}
return 0;
}
Should you ever change the order of scarecrows?
What's the first thing that the leftmost scarecrow should do?
What's the only way to save time? Think in terms of distances and not times.
Look at the points where the crow "switches over" between scarecrows.
Greedy.
We make a few preliminary observations:
- (1) The order of scarecrows should never change, i.e no two scarecrows should cross each other while moving along the interval.
- (2) Scarecrow $$$1$$$ should spend the first $$$a_1$$$ seconds moving to position zero, as this move is required for the crow to make any progress and there is no point in delaying it.
- (3) Let's say that a scarecrow at position $$$p$$$ `has' the crow if the crow is at position $$$p + k$$$, and there are no other scarecrows in the interval $$$[p, p+k]$$$. A scarecrow that has the crow should always move to the right; in other words, all scarecrows that find themselves located to the left of the crow should spend all their remaining time moving to the right, as it is the only way they will be useful.
- (4) Let there be a scenario where at time $$$T$$$, scarecrow $$$i$$$ has the crow and is at position $$$x$$$, and another scenario at time $$$T$$$ where scarecrow $$$i$$$ also has the crow, but is at position $$$y \geq x$$$. Then, the latter scenario is at least as good as the former scenario, assuming scarecrows numbered higher than $$$i$$$ are not fixed.
- (5) The only way to save time is to maximize the distance $$$d$$$ teleported by the crow.
The second and fifth observations imply that the time spent to move the crow across the interval is $$$a_1 + \ell - d$$$.
Now, for each scarecrow $$$i$$$, define $$$b_i$$$ to be the position along the interval at which it begins to have the crow, i.e. the crow is transferred from scarecrow $$$i-1$$$ to $$$i$$$. For instance, in the second sample case the values of $$$b_i$$$ are
The second observation above implies that $$$b_1 = 0$$$, and the first observation implies that $$$b_1 \leq \dots \leq b_n$$$. Notice that we may express the distance teleported as
with the extra definition that $$$b_{n+1} = \ell$$$. For instance, in the second sample case the distance teleported is
and the total time is $$$a_1 + \ell - d = 2 + 5 - 4.5 = 2.5$$$.
Now, suppose that $$$b_1, \dots, b_{i-1}$$$ have been selected for some $$$2 \leq i \leq n$$$, and that time $$$T$$$ has elapsed upon scarecrow $$$i-1$$$ receiving the crow. We will argue the optimal choice of $$$b_i$$$.
At time $$$T$$$ when scarecrow $$$i-1$$$ first receives the crow, scarecrow $$$i$$$ may be at any position in the interval $$$[a_i - T, \min(a_i + T, \ell)]$$$. Now, we have three cases.
Case 1. $$$b_{i-1} + k \leq a_i - T.$$$ In this case, scarecrow $$$i$$$ will need to move some nonnegative amount to the left in order to meet with scarecrow $$$i-1$$$. They will meet at the midpoint of the crow position $$$b_{i-1} + k$$$ and the leftmost possible position $$$a_i - T$$$ of scarecrow $$$i$$$ at time $$$T$$$. This gives
Case 2. $$$a_i - T \leq b_{i-1} + k \leq a_i + T.$$$ Notice that if our choice of $$$b_i$$$ has $$$b_i \lt b_{i-1} + k$$$, it benefits us to increase our choice of $$$b_i$$$ (if possible) as a consequence of our fourth observation, since all such $$$b_i$$$ will cause an immediate transfer of the crow to scarecrow $$$i$$$ at time $$$T$$$. However, if we choose $$$b_i \gt b_{i-1} + k$$$, lowering our choice of $$$b_i$$$ is now better as it loses less potential teleported distance $$$\min(k, b_i - b_{i-1})$$$, while leaving more space for teleported distance after position $$$b_i$$$. Therefore, we will choose $$$b_i := b_{i-1} + k$$$ in this case.
Case 3. $$$a_i + T \leq b_{i-1} + k.$$$ In this case, regardless of how we choose $$$b_i$$$, the crow will immediately transfer to scarecrow $$$i$$$ from scarecrow $$$i-1$$$ at time $$$T$$$. We might as well pick $$$b_i := a_i + T$$$.
Therefore, the optimal selection of $$$b_i$$$ may be calculated iteratively as
It is now easy to implement the above approach to yield an $$$O(n)$$$ solution. Note that the constraints for $$$k, \ell$$$ were deliberately set to $$$10^8$$$ instead of $$$10^9$$$ to make two times the maximum answer $$$4 \cdot \ell$$$ fit within $$$32$$$-bit integer types. It is not difficult to show that the values of $$$b_i$$$ as well as the answer are always integers or half-integers.
#include <bits/stdc++.h>
#define f first
#define s second
#define pb push_back
typedef long long int ll;
typedef unsigned long long int ull;
using namespace std;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(0);
int T; cin >> T;
while (T--) {
int N, k, l;
cin >> N >> k >> l;
double K = k;
double L = l;
vector<int> A(N);
for (int i = 0; i < N; i++) cin >> A[i];
double T = A[0];
double last_pt = 0;
double S = 0;
for (int i = 1; i < N; i++) {
double this_pt = min(L, min(A[i] + T,
max(last_pt + K,
(A[i] - T + last_pt + K)/2.0)));
T += max(0.0, this_pt - last_pt - K);
S += min(K, this_pt - last_pt);
last_pt = this_pt;
}
S += min(K, L - last_pt);
cout << (int)round(2*(L - S + A[0])) << endl;
}
return 0;
}
Let's say you have to empty the haystacks in a fixed order. What's the best way to do it?
Write the expression for the number of moves for a given order.
In an optimal ordering, you should not gain anything by swapping two entries of the order. Using this, describe the optimal order.
The constraint only limits what you can empty last. How can you efficiently compute the expression in Hint 2?
Let's say we fixed some permutation $$$\sigma$$$ of $$$1, \dots, n$$$ such that we empty haystacks in the order $$$\sigma_1, \dots, \sigma_n$$$. Notice that a choice of $$$\sigma$$$ is possible if and only if the final stack $$$\sigma_n$$$ can be cleared, which is equivalent to the constraint
With this added constraint, the optimal sequence of moves is as follows:
- Iterate $$$i$$$ through $$$1, \dots, n-1$$$. For each $$$i$$$, try to move its haybales to haystacks $$$1, \dots, i-1$$$, and if they are all full then move haybales to haystack $$$n$$$. Once this process terminates, move all haystacks from $$$n$$$ back onto arbitrary haystacks $$$1, \dots, n-1$$$, being careful to not overflow the height limits.
The key observation is that the number of extra haybales that must be moved onto haystack $$$n$$$ is
To show this, consider the last time $$$i$$$ that a haybale is moved onto haystack $$$n$$$. At this time, all haybales from haystacks $$$1, \dots, i$$$ have found a home, either on the height limited haystacks $$$1, \dots, i-1$$$ or on haystack $$$n$$$, from which the identity immediately follows. Now, every haystack that wasn't moved onto haystack $$$n$$$ will get moved once, and every haystack that did gets moved twice. Therefore, our task becomes the following: Compute
for $$$\sigma$$$ satisfying
Notice that the $$$\sum_{i=1}^n a_i$$$ term is constant, and we will omit it for the rest of this tutorial. We will first solve the task with no restriction on $$$\sigma$$$ to gain some intuition. Denote $$$ \lt _{\sigma}$$$ the ordering of pairs $$$(a, b)$$$ corresponding to $$$\sigma$$$.
Consider adjacent pairs $$$(a_i, b_i) \lt _{\sigma} (a_j, b_j)$$$. Then, if the choice of $$$\sigma$$$ is optimal, it must not be better to swap their ordering, i.e.
As a corollary, there exists an optimal $$$\sigma$$$ satisfying the following properties:
Claim [Optimality conditions of $\sigma$].
- All pairs with $$$a_i \lt b_i$$$ come first. Then, all pairs with $$$a_i = b_i$$$ come next. Then, all pairs with $$$a_i \gt b_i$$$.
- The pairs with $$$a_i \lt b_i$$$ are in ascending order of $$$a_i$$$.
- The pairs with $$$a_i \gt b_i$$$ are in descending order of $$$b_i$$$.
It is not hard to show that all such $$$\sigma$$$ satisfying these properties are optimal by following similar logic as above. We leave it as an exercise for the reader.
Now, we add in the constraint on the final term $$$\sigma_n$$$ of the ordering. We will perform casework on this final haystack. Notice that for any fixed $$$a_n, b_n$$$, if
is maximized, then so is
So, if we were to fix any last haystack $$$\sigma_n$$$, the optimality conditions tell us that we should still order the remaining $$$n-1$$$ haystacks as before. Now, we may iterate over all valid $$$\sigma_n$$$ and compute the answer efficiently as follows: maintain a segment tree with leaves representing pairs $$$(a_i, b_i)$$$ and range queries for
This gives an $$$O(n \log n)$$$ solution.
Note that it is possible to implement this final step using prefix and suffix sums to yield an $$$O(n)$$$ solution, but it is not necessary to do so.
#include <bits/stdc++.h>
#define f first
#define s second
#define pb push_back
typedef long long int ll;
typedef unsigned long long int ull;
using namespace std;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
template<typename T> int die(T x) { cout << x << endl; return 0; }
#define LNF 1e15
int N;
vector<pll> segtree;
pll f(pll a, pll b) {
return {max(a.first, a.second + b.first), a.second + b.second};
}
void pull(int t) {
segtree[t] = f(segtree[2*t], segtree[2*t+1]);
}
void point_set(int idx, pll val, int L = 1, int R = N, int t = 1) {
if (L == R) segtree[t] = val;
else {
int M = (L + R) / 2;
if (idx <= M) point_set(idx, val, L, M, 2*t);
else point_set(idx, val, M+1, R, 2*t+1);
pull(t);
}
}
pll range_add(int left, int right, int L = 1, int R = N, int t = 1) {
if (left <= L && R <= right) return segtree[t];
else {
int M = (L + R) / 2;
pll ret = {0, 0};
if (left <= M) ret = f(ret, range_add(left, right, L, M, 2*t));
if (right > M) ret = f(ret, range_add(left, right, M+1, R, 2*t+1));
return ret;
}
}
void build(vector<pll>& arr, int L = 1, int R = N, int t = 1) {
if (L == R) segtree[t] = arr[L-1];
else {
int M = (L + R) / 2;
build(arr, L, M, 2*t);
build(arr, M+1, R, 2*t+1);
pull(t);
}
}
vector<int> theoretical(const vector<pii>& arr) {
vector<int> idx(arr.size());
for (int i = 0; i < arr.size(); ++i) {
idx[i] = i;
}
vector<int> ut, eq, lt;
for (int i = 0; i < arr.size(); ++i) {
if (arr[i].first < arr[i].second) {
ut.push_back(i);
} else if (arr[i].first == arr[i].second) {
eq.push_back(i);
} else {
lt.push_back(i);
}
}
sort(ut.begin(), ut.end(), [&arr](int i, int j) {
return arr[i].first < arr[j].first;
});
sort(eq.begin(), eq.end(), [&arr](int i, int j) {
return arr[i].first > arr[j].first;
});
sort(lt.begin(), lt.end(), [&arr](int i, int j) {
return arr[i].second > arr[j].second;
});
vector<int> result;
result.insert(result.end(), ut.begin(), ut.end());
result.insert(result.end(), eq.begin(), eq.end());
result.insert(result.end(), lt.begin(), lt.end());
return result;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(0);
int T = 1; cin >> T;
while (T--) {
cin >> N;
vector<pll> data(N);
ll sum_a = 0;
ll sum_b = 0;
for (int i = 0; i < N; i++) {
cin >> data[i].f >> data[i].s;
sum_a += data[i].f;
sum_b += data[i].s;
}
vector<int> order = theoretical(vector<pii>(data.begin(), data.end()));
vector<pll> data_sorted;
for (int i : order) data_sorted.push_back({data[i].first, data[i].first - data[i].second});
data_sorted.push_back({0, 0});
++N;
segtree = vector<pll>(4*N);
build(data_sorted);
ll ans = LNF;
for (int i = 0; i < N-1; i++) {
if (sum_b - (data_sorted[i].first - data_sorted[i].second) >= sum_a) {
point_set(i+1, data_sorted[N-1]);
point_set(N, data_sorted[i]);
ans = min(ans, range_add(1, N).first);
point_set(i+1, data_sorted[i]);
point_set(N, data_sorted[N-1]);
}
}
if (ans == LNF) cout << -1 << endl;
else cout << ans + sum_a << endl;
}
}
The results of the partition must be convex. Can you see why?
The easier cases are when the polyomino must be cut vertically or horizontally. Let's discard those for now, and consider the "diagonal cuts". I.e. let one polyomino start from the top row, and another starting from some row $$$c$$$. WLOG the one starting on row $$$c$$$ is on the left side, we will check the other side by just duplicating the rest of the solution.
Both sub-polyominoes are fixed if you choose $$$c$$$. But, it takes $$$O(n)$$$ time to check each one.
Can you get rid of most $$$c$$$ with a quick check?
Look at perimeters shapes, or area. Both will work.
Assume there exists a valid partition of the polyomino. Note that the resulting congruent polyominoes must be convex, as it is not possible to join two non-overlapping non-convex polyominoes to create a convex one.
Then, there are two cases: either the two resulting polyominoes are separated by a perfectly vertical or horizontal cut, or they share some rows. The first case is easy to check in linear time. The remainder of the solution will focus on the second case.
Consider the structure of a valid partition. We will focus on the perimeter: 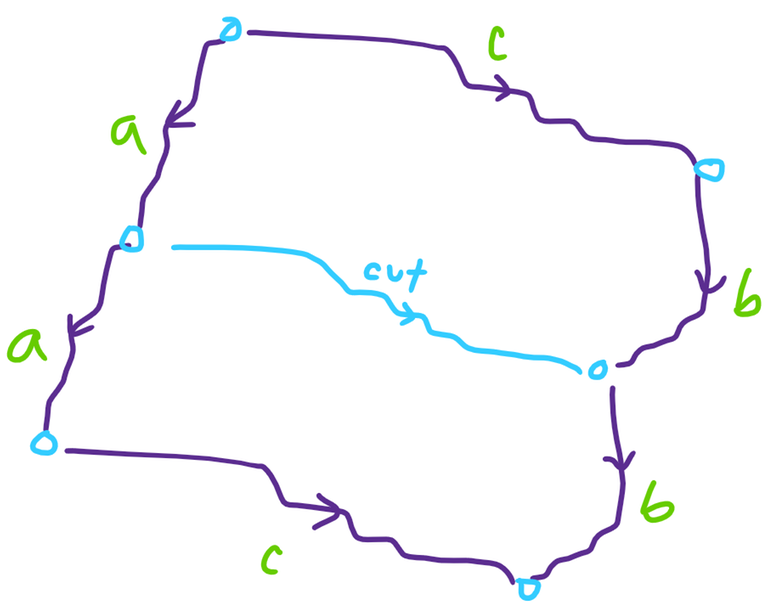
Notice that the cut separating the two polyominoes must only ever move down and right, or up and right, as otherwise one of the formed polyominoes will not be convex. Without loss of generality, say it only goes down and right.
In order for our cut to be valid, it must partition the perimeter into six segments as shown, such that the marked segments are congruent in the indicated orientations ($$$a$$$ with $$$a$$$, $$$b$$$ with $$$b$$$, $$$c$$$ with $$$c$$$.) If we label the horizontal lines of the grid to be $$$0, \dots, n$$$ where line $$$i$$$ is located after row $$$i$$$, we notice that the division points along the left side of the original polyomino are located at lines $$$0, k, 2k$$$ for some $$$1 \leq k \leq n/2$$$.
Notice that if we were to fix a given $$$k$$$, we can uniquely determine the lower polyomino from the first few rows of the upper polyomino. Indeed, if $$$a_i = r_i - \ell_i + 1$$$ denotes the width of the $$$i$$$-th row of the original polyomino, we can show that the resulting polyomino for a particular choice of $$$k$$$ has
cells in its $$$i$$$-th row, for $$$1 \leq i \leq n - k$$$. Therefore, iterating over all possible $$$k$$$ and checking them individually gives an $$$O(n^2)$$$ solution.
To speed this up, we will develop a constant-time check that will prune ``most'' choices of $$$k$$$. Indeed, we may use prefix sums and hashing to verify the perimeter properties outlined above, so that we can find all $$$k$$$ that pass this check in $$$O(n)$$$ time. If there are at most $$$f(n)$$$ choices of $$$k$$$ afterwards, we can check them all for a solution in $$$O(n \cdot (f(n) + \text{hashing errors}))$$$.
It can actually be shown that for our hashing protocol, $$$f(n) \leq 9$$$, so that this algorithm has linear time complexity. While the proof is not difficult, it is rather long and will be left as an exercise. Instead, we will give a simpler argument to bound $$$f(n)$$$. Fix some choice of $$$k$$$, and consider the generating functions
The perimeter conditions imply that $$$(1 + x^k) B(x) = A(x)$$$. In other words, $$$k$$$ may only be valid if $$$(1 + x^k)$$$ divides $$$A(x)$$$. Therefore, we can use cyclotomic polynomials for $$$1 + x^k \mid x^{2k} - 1$$$ to determine that
As the degree of the $$$k$$$-th cyclotomic polynomial is $$$\phi(k)$$$ for the Euler totient function $$$\phi$$$, we can see that $$$f(n)$$$ is also at most the maximum number of $$$k_i \leq n$$$ we can select with $$$\sum_i \phi(k_i) \leq n$$$. Since $$$\phi(n) \geq \frac{n}{\log \log n}$$$, this tells us that
and this looser bound already yields a time complexity of at most $$$O(n \sqrt n \cdot \log \log n).$$$ While this concludes the official solution, there exist many other heuristics with different $$$f(n)$$$ that also work.
It is in the spirit of the problem to admit many alternate heuristics that give small enough $$$f(n)$$$ ``in practice'', as the official solution uses hashing. One such heuristic found by testers is as follows:
We take as our pruning criteria that the area of the subdivided polyomino $$$\sum_{i=1}^{n-k} b_i$$$ is exactly half of the area of the original polyomino, which is $$$\sum_{i=1}^n a_i$$$. Algebraically manipulating $$$\sum_{i=1}^{n-k} b_i$$$ to be a linear function of $$$a_i$$$ shows it to be equal to
The calculation of all these sums may be sped up with prefix sums, and therefore pruning of $$$k$$$, can be done in amortized $$$O(n \log n)$$$ time since any fixed choice of $$$k$$$ has $$$\frac nk$$$ segments.
However, for this choice of pruning, it can actually be shown that $$$f(n) \geq \Omega(d(n))$$$, where $$$d(n)$$$ is the number of divisors of $$$n$$$. This lower bound is obtained at an even-sized diamond polyomino, e.g.
Despite our efforts, we could not find an upper bound on $$$f(n)$$$ in this case, though we suspect that if it were not for the integrality and bounding constraints $$$a_i \in {1, \dots, 10^9}$$$, then $$$f(n) = \Theta(n)$$$, with suitable choices of $$$a_i$$$ being found using linear programs. Nevertheless, the solution passes our tests, and we suspect that no countertest exists (though hacking attempts on such solutions would be interesting to see!).
#include <bits/stdc++.h>
#define f first
#define s second
typedef long long int ll;
typedef unsigned long long int ull;
using namespace std;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
void print_set(vector<int> x) {
for (auto i : x) {
cout << i << " ";
}
cout << endl;
}
void print_set(vector<ll> x) {
for (auto i : x) {
cout << i << " ";
}
cout << endl;
}
bool connected(vector<ll> &U, vector<ll> &D) {
if (U[0] > D[0]) return 0;
for (int i = 1; i < U.size(); i++) {
if (U[i] > D[i]) return 0;
if (D[i] < U[i-1]) return 0;
if (U[i] > D[i-1]) return 0;
}
return 1;
}
bool compare(vector<ll> &U1, vector<ll> &D1, vector<ll> &U2, vector<ll> &D2) {
if (U1.size() != U2.size()) return 0;
if (!connected(U1, D1)) return 0;
for (int i = 0; i < U1.size(); i++) {
if (U1[i] - D1[i] != U2[i] - D2[i]) return 0;
if (U1[i] - U1[0] != U2[i] - U2[0]) return 0;
}
return 1;
}
bool horizontal_check(vector<ll>& U, vector<ll>& D) {
if (U.size() % 2) return 0;
int N = U.size() / 2;
auto U1 = vector<ll>(U.begin(), U.begin() + N);
auto D1 = vector<ll>(D.begin(), D.begin() + N);
auto U2 = vector<ll>(U.begin() + N, U.end());
auto D2 = vector<ll>(D.begin() + N, D.end());
return compare(U1, D1, U2, D2);
}
bool vertical_check(vector<ll>& U, vector<ll>& D) {
vector<ll> M1, M2;
for (int i = 0; i < U.size(); i++) {
if ((U[i] + D[i]) % 2 == 0) return 0;
M1.push_back((U[i] + D[i]) / 2);
M2.push_back((U[i] + D[i]) / 2 + 1);
}
return compare(U, M1, M2, D);
}
ll base = 2;
ll inv = 1000000006;
ll mod = 2000000011;
vector<ll> base_pows;
vector<ll> inv_pows;
void precompute_powers() {
base_pows.push_back(1);
inv_pows.push_back(1);
for (int i = 1; i <= 300000; i++) {
base_pows.push_back(base_pows.back() * base % mod);
inv_pows.push_back(inv_pows.back() * inv % mod);
}
}
ll sub(vector<ll> &hash_prefix, int a1, int b1) {
return ((mod + hash_prefix[b1] - hash_prefix[a1]) * inv_pows[a1]) % mod;
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(0);
precompute_powers();
int T; cin >> T;
while (T--) {
int N; cin >> N;
vector<ll> U(N), D(N), H(N);
vector<pii> col_UL(N), col_DR(N+1);
vector<ll> hash_prefix_U(N), hash_prefix_D(N);
for (int i = 0; i < N; i++) {
cin >> U[i] >> D[i];
H[i] = D[i] - U[i] + 1;
col_UL[i] = {i,U[i]};
col_DR[i] = {i+1,D[i]+1};
}
// hashing
for (int i = 1; i < N; i++) {
hash_prefix_U[i] = (((mod + U[i] - U[i-1]) * base_pows[i-1])
+ hash_prefix_U[i-1]) % mod;
}
for (int i = 1; i < N; i++) {
hash_prefix_D[i] = (((mod + D[i] - D[i-1]) * base_pows[i-1])
+ hash_prefix_D[i-1]) % mod;
}
// horizontal split
if (horizontal_check(U, D)) {
cout << "YES" << endl;
goto next;
}
// vertical split
if (vertical_check(U, D)) {
cout << "YES" << endl;
goto next;
}
for (int _ = 0; _ < 2; _++) {
// down-right split
for (int c = 1; c <= N/2; c++) {
// check upper portion
if (sub(hash_prefix_U, 0, c-1) != sub(hash_prefix_U, c, 2*c-1)) continue;
if (H[0] - U[2*c] + U[2*c-1] != U[c-1] - U[c]) continue;
// check lower portion
if (sub(hash_prefix_D, N-c, N-1) != sub(hash_prefix_D, N-2*c, N-c-1)) continue;
if (H[N-1] + D[N-2*c-1] - D[N-2*c] != D[N-c-1] - D[N-c]) continue;
// check main portion
if (sub(hash_prefix_U, 2*c, N-1) != sub(hash_prefix_D, 0, N-2*c-1)) continue;
// brute force section
// polynomial division
bool ok = 1;
vector<ll> H_copy(H.begin(), H.end());
vector<ll> quotient(N);
// calculate quotient
for (int i = 0; i < N-c; i++) {
quotient[i] = H_copy[i];
H_copy[i+c] -= H_copy[i];
if (quotient[i] < 0) ok = 0;
}
// check for no remainder
for (int i = N-c; i < N; i++) if (H_copy[i]) ok = 0;
if (!ok) continue;
// construct subdivision
vector<ll> U1, D1, U2, D2;
for (int i = c; i < N; i++) {
int ref_height = quotient[i-c];
U1.push_back(D[i-c] - ref_height + 1);
D1.push_back(D[i-c]);
U2.push_back(U[i]);
D2.push_back(U[i] + ref_height - 1);
}
if (compare(U1, D1, U2, D2)) {
cout << "YES" << endl;
goto next;
}
}
// flip and go again!
swap(hash_prefix_U, hash_prefix_D);
swap(U, D);
for (int i = 0; i < N; i++) {
U[i] = -U[i];
D[i] = -D[i];
}
}
cout << "NO" << endl;
next:;
}
return 0;
}






fast editorial...orz
woah that was fast! we've been getting lots of quick editorials lately, nice!
tell me I'm not the one who use lazy segtree on B
whoa candidate master things ... we don't use lazy propagation here in div2B
lmao
i was thinking about it a lot
oh wow, thank you for fast editorial
What in the Itachi Crow Montage D problem :}
I spent lot of time to figure out C, but then was about to give up without any idea, but then I tried to make a submission by making sum of rows and column Zero, and it worked .. I am not proud. But I hope to get some idea from the editorial.
ok I think Sum = 0 works because n*S = m*S ... does that mean when n!=m ... there is no other possible value of S .. actually I was trying to find that value but didn't get any ideas
orz
I couldn't figure this myself during competition .. I read from the editorial ...
I never thought that Problem D is a Greedy!
Can someone please tell me why my submission 300745220 for Problem D is failing?
The logic seems correct, but the error may be with the way you print the answer. Your
valis long double, so when it becomes large enough, it prints in scientific notation, e.g. 4e+08 instead of 400000000Converting to long long should fix that:
cout << 2 * (ll)val << endl;And generally, as a rule of thumb, if the answer to the problem is an integer, but your variable is a floating point, better always cast it to the int before printing, just in case :)
Oh! I didn't know that. Thank you
Use binary search, problem C is possible. Really inspiring problem C, I hardly solved it in 90mins.
I feel upset that I didn't solve it like editorials. I should practice more.
its completely normal to have a solution that isnt like the editorials.
I feel my solution was completely complex, did anyone do like this?300738374
Could you explain what are you binary searching on?
We choose any $$$x$$$ to fill $$$(1, \, 1)$$$, then the next cell can be calculate. After $$$n + m - 2$$$ operations, we still remain the last cell of $$$(n, \, m)$$$. Any number $$$a$$$ we choose may not satisfy, the sum of cols and the sum of rows have difference. The difference can be positive of negative(decided by the last operation you do on the row or col). We assume that we operate on the last row, and donate $$$\Delta x = sum_{row} - sum_{col}$$$. If $$$\Delta x \lt 0$$$, we need to enlarge the last number to ensure it can be an equation. So try to enlarge $$$x$$$ and try to fill the cells again.
Hi can you explain why S = 0 works for the case when n == m as then we can have a solution where S can be anything?
Why won't it work? , like clearly S*n = S*m , as you claim(n == m) , they cancel out leaving S = S , which is always true , as it turns out S can be set to any value so obviously S = 0 will work as well....But since when n != m , S needs to be set to zero , then its beneficial for us to always choose s = 0 so that we can do it in a single algo....
got it thanks
What he said is not correct, how do you even get it? S*n = S*m and canceling doesn't mean anything, you still don't know the value of S.
Hey S*n = S*n means S will satisfy for every value if you look at this equation only so S = 0 will be one of the solution here in this case you can have any sollution , you can compute S to any random number also in this case and you will get a solution for all values
In the question some part of the matrix are fixed numbers, you have to prove the S = 0 works based on the given matrix, not just looking at S*n = S*n. It only means you can find a n*n matrix with row and column of sum S and S can be any value but it has nothing to do with the question.
Again if S = 0 then we can have solve this problem as defined in a approach and we can have one equation and one variable for missing number (0) so we will definitely have a solution and then Sum of all rows and columns will be same so all constraints are satisfied
Yes, that's what I am talking about. You have to prove it with the approach to say that it works for any integer not because just a S*n = S*n.
Hey. I am not sure I understand your idea of binary searching over sum value but in your code , you will never have more than one iteration as sum=0 in first iteration itself which will satisfy required conditions.
Oh, it could be a coincidence, after all, I didn't even think about that aspect of $$$S = 0$$$ when I was working on the problem.
Actually, if we choose $$$x$$$ to fill $$$(1,1)$$$, and donate $$$y = sum_{row} - sum_{col}$$$, we can notice that they have a linear relationship, which means $$$y = k \times x + b$$$. So, we can successively let $$$x = 0,1$$$ and fill the cells, then calculate the value of $$$k,b$$$. After that, let $$$x = -\frac{k}{b}$$$, and fill the cells again.
My English is quite poor. If you can't understand me, you may check my submission. Some of the implementations in my code differ from the above process to some extent.
I tried to use binary search for C as well here: https://mirror.codeforces.com/contest/2055/submission/300745300
But I still don't know why it doesn't pass, because from my analysis, my program would eventually search the case where $$$S=0$$$.
The difference between the last row and last col can be positive or negative. You should check if it is positive, then let $$$r = mid - 1$$$, or it will get wrong.
That's what I tried to do. In my code, one of the sums (either row or col) will be equal to $$$S$$$, depending on whether the last instruction was D or R, so when I check whether one of the sums is larger than $$$S$$$, I'm essentially checking whether the difference is positive. I must be missing something here I guess but I still can't really see where in my program is wrong.
It makes sense. What would happen if you break when the difference equals 0?
why should S be 0 ?
The editorials explaiined well. S equals 0 means the matrix gets balanced.
It does explain that $$$S=0$$$ will be the only solution when $$$n \neq m$$$, but it does not prove that a solution always exists when $$$S=0$$$. I'm still wondering about that.
This kind of question should be more about math. But since the question says that there is a guaranteed solution, you must just find the necessary conditions while working on the problem. I wouldn't be too good at adding a specific proof, but this must be far more difficult than the C and D problems.
i guess solution always exist because when we solving it we have one variable and one equation so the solution would always exist for each values whether it is stated gurated solution or not
Maybe the rank of the matrix?
C was, brutal not gonna lie!
agreed, i had a similar approach to the editorial but i got overwhelmed with the 120 lines of code that i wrote and couldn't debug it in the last 10 mins.
still, getting this close to solving C being rated 800 feels nice!
That's literally what I was trying to do for B and it didn't pass :-| My approach was to create a new array c that's a — b. If there are more than 1 negatives in c (we need to make more than 2 materials) the answer is NO.
Otherwise take the minimum positive in c and check whether it's large enough to turn the negative into 0.
your approach is correct though, i had the exact same approach and it passed. could you share your code?
https://mirror.codeforces.com/contest/2055/submission/300708247
Probably missed something important, will check it out again tomorrow. Thanks for confirming the approach is correct though, I was so confused. lol
In addition to what was written above, seems like you're not checking indexes, where
a[i] == a[b], and therefore yourmin_positiveis not equal to zero, when it should beeven tho i didnt do well this has to be the highest quality div 2 in a very long time
personally i didn't get to d and onward in time but i'd say the difficulty had a very sudden jump on c,yet the solution to it is very basic it's weird
I didnt think I could solve D during the contest is D hard for average pupil.I think C was easy for div2c (SO MANY PEOPLE USED GPT UNFORTUNATELY
how do you find if people used gpt
that problem was GPT-solvable you can try
I saw someone was complaining about it and I just tried lol
but the balancing was horrendus ,no one ,i mean no one solve E or F
man if i didnt get WA due to using int not ll I would rank 1000 places higher
Aren't there any code that I can read so I can understand better??
look at jiangly or other high rankers code
@Dominater069 writes very simple code
questions were good ngl , although i dont know how to even start D
Problem C is really amazing.
I can't unserstand why shoudl S be equal to 0 ??
Because the sum of all rows shoule be equal to the sum of all columns (Both are equal to the sum of all elements), the equation S*rows = S*cols should held. However, the only possible solution is S = 0 when rows != cols. I hope it can help you.
Can someone point out the mistake in my submission for D 300739742. Looking at the editorial feels like my approach is similiar.
Convert time to an integer and will pass.
why this failing for c
Please use spoiler...
you can use spoiler like this.
1)
<spoliler>2) then three backticks (```)
3) Then your code.
4) again three backticks (```)
5) </ spoiler> ( remove space between
/and thespoiler).Can someone please explain me why my submission 300732331 for Problem C is failing? I thought the way i coded that was the same thing that what written on the solution but i guess there's something i don't understand.
the added value can be long long, which will overflow if you set number type as int, I guess ?
sorry i misread the turorial and made a dum comment
why in c we have to make sum ==0 of all rows and cols .... why can't we make sum of all rows and col equal max of sum of rows or col or anyother number
Because s = 0 is the only possible solution for s*rows == s*cols when rows != cols.
yeah same question, did someone make any other sum apart from zero.
Considering the difficulty of all the problems, I sincerely wish, if the contest had 2:15 minutes or 2:30 minutes.
I think, I solved D ( passing pretest 1 xD ), right after 5 minutes of contest ending :( .
I don't know, if anyone else solved D, within 10 minutes after the contest.
https://mirror.codeforces.com/contest/2055/submission/300750943 ( It worked !!! ).
For the problem C, what is the intuition behind trying to make the sums of all rows and columns as 0. In the editorial it is written S.N has to be equal to S.M
But in the problem statement the only requirement is that we need to make sums of all individual rows and column same, am I missing something?
so (sum of each row == sum of each column) ..if that sum is 'S', so the total sum of GRID is S * n ... and also S * m .. so they should be equal
but because n and m can be unequal ... S=0 is a solution to S*n = S*m
I didn't realise S.n and S.m means the total grid sum. It makes sense. Thank you!
I got TLE in problem c. If someone finds the problem please let me know. My solution:- https://mirror.codeforces.com/contest/2055/submission/300745877
I am not really sure, but can it be because of using slow input method Scanner or slow output ?
feeling happy after climbing mountains of problem C
i submitted 2 correct submissions for problem D(300739717 and 300743089), and 300743089 is just 300739717 with some ints turned into longs. I submitted 300743089 since I was scared that someone might be able to hack it to cause overflow. However, my first submission, 300739717 got skipped because it was almost identical to 300743089, but my second submission 300743089 didn't. Now, I have to incur the extra penalty for the second submission, since i submitted it 8 minutes later than the first. Does codeforces usually do this or should I get the points off of my first submission?
Whenever you have multiple submissions that pass pretests, all but the last are skipped. You could have completely rewritten the code without a hint of similarity between the two submissions, and 300739717 would have still been skipped and ignored.
thank you innocentkitten for the wonderful contest and letting catgirl reach master orz
did you really become master in 6 months or were you doing cp in the past.
I did indeed start competitive programming 6 months ago, but I was doing math olympiads before, so that for sure helped ^-^
Can someone please explain the maths behind C? My observation:
There exists $$$n + m$$$ variables: $$$n + m − 1$$$ values from cells, and the sum $$$S$$$.
There exists $$$n + m$$$ equations: From each row and each column.
So there can be $$$0, 1$$$ or $$$\infty$$$ solutions. But the editorial choosing sum $$$S$$$ implies there are infinite solutions. What is the proof of this?
Update: Nevermind I understood it.
so what's your conclusion
Assume the first sample. Let the unknown numbers be $$$a, b, c, d, e$$$, and the sum be $$$x$$$.
So the grid is:
$$$a$$$ $$$2$$$ $$$3$$$
$$$b$$$ $$$c$$$ $$$d$$$
$$$3$$$ $$$1$$$ $$$e$$$
The equations are:
Now, realize that the equations $$$(i)$$$ + $$$(ii)$$$ + $$$(iii)$$$ — $$$(iv)$$$ — $$$(v)$$$ = $$$(vi)$$$
So equation $$$(vi)$$$ is not giving any new information, it can be derived from the first $$$5$$$ equations.
So we can conclude that there are $$$n + m$$$ variables and $$$ \lt n + m$$$ equations. So there are infinite combinations of values satisfying these equations, and we have to choose the easiest calculable solution of them.
I would argue that this only happens because, in the first sample, the grid is a square. In any other case, there is exactly one solution for all variables (x = 0)
See it this way, in the first $$$n$$$ equations, each number is considered once.
In the next $$$m - 1$$$ equations, we'll have each number from the first $$$m - 1$$$ columns.
So subtracting the $$$n$$$ equations with the $$$m - 1$$$ equations gives the $$$m$$$-th equation.
cout << (long long)2*tim << endl; cost me an AC in D
It should have been cout << (long long)(2*tim) << endl;
Very Dumb of me obviously to write that , even very dumb of me to not recognise it in my 15 mins debugging.
Can anyone help me with todays B 2055B - Crafting.
My thought was: 300755890 We cannot increase more than one element for sure, why? Because if we try to increase A and B then we will inc. A then we have to dec B by atleast 1 and to inc B by 2 now we have to dec A by 2.
My second observation was that as the inc is dependent on dec so I calulated the minimum decrease that we can do and the max increase that we have to do although it is the single element. Now if the max increase is greater than the min decrease that we can bear than the ans in simply no.
for rest of the cases we can do the task so the ans is yes.
Can anyone please help me where I went wrong ?
Am I too dumb to ask this shit ?
a[i]>b[i] should be a[i]>=b[i]
EF are way harder than it should be. I've never seen a *3000 div2E.
True, there should be 1 or 2 problems between d and e, e is like a div 1 E
Problem Haystacks is so cool, I love it <3
Unbalanced as hell though
awang11 the implementations are not visible, we "aren't allowed to view the requested page"
For me, an easier way to reason about problem D is to think of two cases:
At the end, if there remains any distance, the last scarecrow must move forward by that distance (adding to the elapsed time). The special case of the first scarecrow can be handled before the main loop. 300755131
I am really disappointed by how nowadays contests are formed, do guys from 1400-1800 have no oppurutunity to solve problems involving some Data structure or algo, I mean this level of greedy upto D, i mean we should give some advantage to guys who have read something extra over heavily intelligent guys who are gud at observing or greedy.
remember people complaining last week why segment tree was required for D. i guess there will always be people complaining about smth
I understand your point, but my complaint was very generic like not so intelligent guys like me wants to solve graphs or maybe any DS in C or D, maybe I will also not like Segment tree but that will not be a complaint from my side bcse I think segment tree for D is sometimes okay.
In Problem C
Can it be proven that when n=m the solution x=0 is also possible?
I appreciate the detailed editorial with hints and everything... also, I enjoyed the contest! :D
In C, why is it correct to assert S × n = S × m? Why does the sum of the sum of the rows need to be equal to that of the columns? Oh, I get it, it's just the sum of the grid
Nice explanation for problem C, I just guessed that setting x = 0 will work but wasn't able to prove why.
Very high quality C and D, loved the round
For problem C: The fact that $$$S = 0$$$ will hold when $$$n = m$$$ is not trivial and the editorial's argument is not sufficient for that.
One argument for $$$m = n$$$ is that there are $$$n+m$$$ variables ($$$n+m-1$$$ on the path and $$$1$$$ which is $$$S$$$) but the $$$n+m$$$ linear equations are not linearly independent (since $$$m=n$$$, sum of all columns equal sum of all rows). So, we can pick $$$S$$$ to be anything we want since there are only $$$n+m-1$$$ linearly independent equations.
For $$$n = m$$$, it is solvable for any choice of $$$S$$$.
For D, you can multiply l, k, and the entries of a by 2 (but keep the speed at 1), so that you don't need to work with doubles.
Also, the solution to D is well-written, thanks!
Problem A is identical to an atcoder task: https://atcoder.jp/contests/agc020/tasks/agc020_a
ah, unfortunate. Given that the problem idea is relatively standard it's not a surprise it's come up before... but since it's problem A there isn't much to be done. Sorry about that.
Here's the other way to implement the last part of problem E, which is simpler I'd say. Basically we choose the last haystack in the following way:
If we have a haystack with $$$b_i \le a_i$$$ which can be used as the final haystack, then it's not worse to use it as the last haystack, so we use it and calculate the answer.
Otherwise let $$$f_i$$$ be $$$a_i + \sum_{j \lt i} b_j - a_j$$$, and let $$$g_i = min_{i \le j}(f_j)$$$, then if we move the $$$i$$$-th haystack to the end (if possible) the answer will increase by $$$max(0, b_i - a_i - g_{i+1})$$$. So we choose a haystack that minimizes it.
In problem E, can someone elaborate on why this part holds true? "It is not hard to show that all such σ satisfying these properties are optimal by following similar logic as above."
Hi Everyone, Here is my intuition for C
I made a linear equation (n + m ) * x = 2 * (total_sum_grid)
(n + m)*x = 2 * (partial_sum + y)
let (n +m) = p , partial_sum = q;
p*x = 2 * (q + y)
p.x = 2.q + 2.y
p.x — 2.y = 2.q (here we know the p , q values)
so after generating equations for test cases I felt this linear equation will always have solutions and x, y values can be any ranging {0 infinity}. So here I was stuck for 20min how can I pick x from this at some point I thought it could be done with binary search but then I realized it won't form 000000011111. since I got stuck I though let's start with a simple thought by fixing x = 0 , I tried few test cases and it is always balancing all rows and columns. But at this point I don't have prof why sticking to x = 0 will work but after few test cases I felt x = 0 will always work (I just assumed my prof as since all column's and rows have same sum and because of the given path I thought I can always adjust all columns and rows as I have few positions to adjust but I know this is not a nice way to prove). Now my issue is how can I implement it as of now from my observations I have x = 0 but how can I traverse the grid in such a way that rows and columns will be adjusted. Then I thought of what is the use of the given path and what will happen when we fix one element in the path given. Here I could see we can always fix a row or column as 0 based on our next step as given in the editorial as we never going to return back to either a row or column. At this point I got confidence that we can always adjust x = 0 why because the path will traverse in such a way that all columns and rows will be adjusted if we travel along the path(as path covers all rows and columns). Even though I got AC on this but after seeing editorial I felt i am just lucky. **I don't know should I feel happy or sad about my solution **.I will be happy with any of yours suggestions. ThankYou.
mysolution 300780643 TC = (N*M + N + M)
Can someone tell the exact movements in last test case of the sample test case ?
Suppose you are talking about D,
$$$n,k,l = 9, 12, 54$$$
when $$$t=0$$$, scarecrows:
3 3 8 24 25 27 29 34 53crow:0At $$$t=3$$$, scarecrows:
0 6 11 21 28 30 32 37 50crow:12->18->23->33->40->42->44->49Then, at $$$t=3.5$$$ scarecrows:
0 6 11 21 28 30 32 37.5 49.5crow:49->49.5->61.5Thanks , wrong greedy drove me crazy ...
D was amazing
I tried binary search for problem D, check for max time T then adjusting scarecrow positions greedily to give max push in right direction 300834214
but not sure why it's failing :(
woah that was fast! we've been getting lots of quick editorials lately, nice!
Can anyone tell me why this 300740665 solution giving wa in tc2
Some values are still 0 after you do the operations. Consider RDRDRDRDRD... So going row by row: We can't have an answer for row1, row2, row3, row4 and so on Similarly for column, col1 will have the answer but col2, col3, col4 and so on In this case if you do alternate col to row it will work(only in this case). There can be more cases. Come up with some general algorithm.
Got it. Thanks man.
I have WA on B with similar logic as in solution: https://mirror.codeforces.com/contest/2055/submission/300902104 — help plz
Your code does not guarantee that all b[i] are read in, and that can lead to issues with the next test. A small modification allows your code to pass: https://mirror.codeforces.com/contest/2055/submission/300902799
D is too clever and too difficult for me.
the $$$i$$$-th scarecrow wants to be at position $$$k*i$$$.
Intuition comes from the best possible scenario, where scarecrows are at positions : $$$0, k, 2k, ..., (n - 1) * k$$$. In which case, we can instantly move to the last scarecrow and go one by one from there.
300980679
Here's a fun way to skip the optimality claim in E:
The problem is numerically stable, which means we can add infinitesimals to $$$a_i$$$ and $$$b_i$$$ and get essentially the same answer (well, we can't, because $$$a_i$$$ and $$$b_i$$$ are integers, but we can just work with the continuous version of the problem, where we move $$$x$$$ haybales for possibly non-integer cost $$$x$$$).
So if we replace $$$a_i$$$ by $$$a_i + i \varepsilon$$$ and $$$b_i$$$ by $$$b_i - i \varepsilon$$$, $$$\min(a_j, b_i)$$$ and $$$\min(a_i, b_j)$$$ are never equal. Since $$$ \lt _{*} := \min(a_j, b_i) \geq \min(a_i, b_j)$$$ is transitive, we can go ahead and just sort the elements to get $$$\sigma$$$.
...it's probably easier to come up with the constructive solution anyway.
I've encountered a tricky problem. These four pieces of code only differ in the comparison function when a_i=b_i, but they yield different results. The comparison function should have no impact.Someone please help me.[submission:301500898][submission:301502091][submission:301501960][submission:301501852]
Problem C can be solved in O(n+m-2), i.e., O(n+m), using the precomputed sum of each row and column of the matrix. [Note: Here, I am ignoring the complexity of i/o and col-wise sum calculation.]
IDEA: In the current index (i, j), I will make the current col and row sum 0, but the question is, what should I proceed with first, or can I make both col and row 0 from standing at (i, j)? The answer is no. so if the next step is 'D' I will make the row first zero, and then moving into the row I will make the col sum 0. For the next step 'R' does vice versa.
I am giving the solution here for better understanding,
In C.
What if grid is 2X3
0 10^6 10^6
0 0 0
10^6 10^6 0
DRRD
We have to fill a[0][0] as -2*(10^6) but the minimum value of a cell can be -10^6. How will this test case work?
B。。。Why did you write a Merge Sort,I can't understand........ If you just wanted to spoof new talent,I can't say that I am unrated....
In C.
What if grid is 2X3
0 10^6 10^6
0 0 0
10^6 10^6 0
DRRD
We have to fill a[0][0] as -2*(10^6) but the minimum value of a cell can be -10^6. How will this test case work?