


Hello everybody,
So 4 months ago I wrote a blog about an online game I created. The game was basically you trying to type words moving in linear trajectories on the screen with different speeds for one minute. Your score was, and still is, the number of characters in all words you managed to type correctly while still on the screen. A lot of time has passed, during which I have learned some more thing, and now I would like to introduce you to the new version of it.

The website address is the same — http://crazytyper.cf. The first thing you will be asked to do is to pick a nickname which you will be able to change at any moment by clicking on the "Edit nickname" label which will appear in the upper left corner.
The game now has two modes — standard and survival. You will notice that I added leaderboards showing the top 5 results for the last 24 hours for each mode. To play some mode, simply click on the respective buttons under the scoretables.
Standard mode is pretty much what the previous version was but with much improved interface — you try to type words for a minute and you get a score equal to the total number of characters in the words typed correctly. After that minute passes, your score will automatically be inserted into the database with all scores and will eventually be shown on the top 5 leaderboard, if good enough.
Survival mode is the new feature which I believe is much more entertaining. You start with 10 seconds and again try to type the words you see. For each word you type correctly, you get a 1-second increment but you can never have more than 10 seconds. The score is again the number of characters in the words you type correctly. After your timer reaches zero, your score will automatically be inserted into the database and shown on the top 5 leaderboard, if good enough.
I would love to hear some feedback from you, also maybe share your scores here. My best ones are around ~390 for standard and ~2600 for survival.







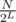 . So the complexity will be
. So the complexity will be 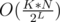 per query.
per query. 
 by
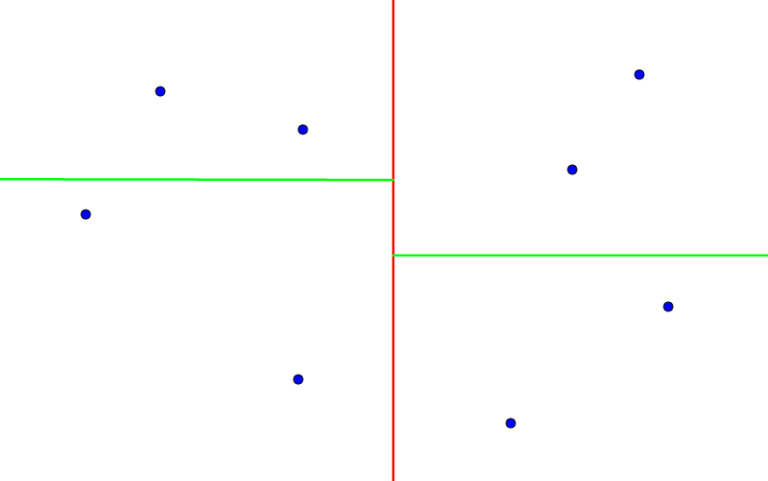
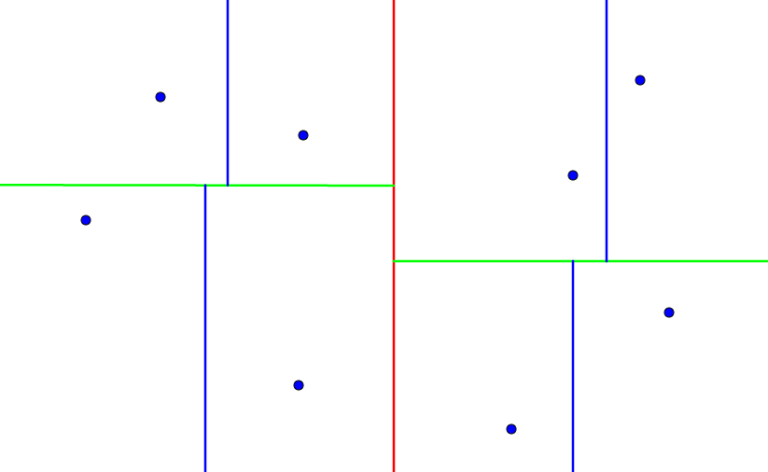
by  . Which means that we will only need to consider the squares surrounding this current cell (which happen to be 8), if the distribution is perfectly uniform. So the average complexity turns out to be around
. Which means that we will only need to consider the squares surrounding this current cell (which happen to be 8), if the distribution is perfectly uniform. So the average complexity turns out to be around  .
.

{kind=link}
{kind=link}
{kind=link}