


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | Radewoosh | 3415 |
| 8 | Um_nik | 3376 |
| 9 | maroonrk | 3361 |
| 10 | XVIII | 3345 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 145 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 135 |
| 7 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 132 |
|
On
Pyqe →
Codeforces Round #902 (Div. 1, Div. 2, based on COMPFEST 15 — Final Round) Editorial, 3 years ago
+29
I have an alternative solution for G that runs in $$$O((n+q)(\log{n} + \log{\max{x}}))$$$. Same as editorial, to answer a query $$$(l,r,x)$$$, we take $$$x$$$ and run through gates $$$r$$$ to $$$l$$$ sequentially, where gate $$$i$$$ is the function $$$f(x)=\min{(a_i,\lfloor \frac{x+a_i}{2} \rfloor)}$$$. We can retrieve the answer after computing the sum of results after running each gate. Suppose all queries have $$$r=n$$$. Then we can get some solution sketch like this: gradually increment $$$x'$$$ from $$$0$$$ to $$$10^9$$$, while maintaining $$$ans_i$$$ for $$$1 \le i \le n$$$, where $$$ans_i$$$ is the result of $$$x'$$$ after running through gates $$$n$$$ to $$$i$$$. Then, to answer a query $$$(l,r,x)$$$, we just pick the moment we have $$$x'=x$$$, and we take the sum of $$$ans_i$$$ for $$$l \le i \le n$$$. To maintain $$$ans_i$$$, we can store a set of active gates, which are gates $$$i$$$ that have $$$a_i \le ans_{i+1}$$$. Once a gate is activated, it will never be deactivated. Obviously, if gate $$$i$$$ is not active, then $$$ans_i = ans_{i+1}$$$. So by knowing positions active gates, we can divide the $$$ans$$$ array into continuous blocks of equal value. Now, when we increase $$$x$$$ by $$$1$$$, we update the $$$ans$$$ array in a similar fashion as how we would do $$$+1$$$ on a big integer represented in binary. This takes $$$O(1)$$$ amortized. We then check, for each changed value of $$$ans_i$$$, whether it would activate some gates. This can be detected by RMQ, and we can have a $$$O(\max{x}+n\log{n})$$$ idea. To improve, we can compute the next value of $$$x'$$$ which either activates a gate or we need to answer a query of that value, instead of increasing $$$x'$$$ one by one. This improves the time complexity to $$$O((n+q)(\log{n} + \log{\max{x}}))$$$. Finally, let's think of how to also handle queries with arbitrary $$$r$$$. Let's say we have a query $$$(l,r,x)$$$, If at any moment we manage to have $$$ans_{r+1}=x$$$, then we are very happy as we can get what we want by just computing sum of $$$ans_i$$$ for $$$l \le i \le r$$$. So we can just modify the previous solution to detect the next important $$$x$$$ that either activates a gate, or hits some $$$ans_{r+1}=x$$$. But there might be some ugly situation where we have cooked $$$x'$$$ up to $$$10^9$$$, but $$$ans_{r+1} \lt x$$$ still holds. Now, the funny trick is that we realise at this moment, all queries with $$$r=n$$$ are already answered, and gate $$$n$$$ is already activated. So, we can simply pretend gate $$$n$$$ never exist, and repeat our process with the new $$$x'$$$ to be $$$ans_n$$$. By the time we removed all the gates, we would have already found out the answer for all queries. The data structure details are not too ugly, but it took me a long time to implement... |

|
+19
Tell us your top 3 favourite atcoder problems)) |
|
+60
I have another idea for H. First we solve by hand for $$$p_i=q_i=n-i+1$$$, it is easy using idea for $$$n=2$$$. Now whenever $$$p_i \gt p_{i+1}$$$, the corresponding paths must intersect and so you can untangle them and swap $$$p_i$$$ and $$$p_{i+1}$$$. So we can just do bubble sort and do $$$O(n^2)$$$ such subroutines to modify into correct $$$p$$$. Same idea for fixing $$$q$$$. Thanks for the contest, very interesting problems. |
|
+10
Thank you for the round. |
|
+27
I didn't like the problem names. They were boring. |
|
+59
With good loyal employees |
|
+8
Having good memory is important for success in CP |
|
+120
Any plans on offering money to testers like codechef? |
|
+30
How long has your round been in queue for? |
|
On
anchal_1171 →
How do I Write the program If I know the Algorithm to be used But don't know the way to Implement it, 5 years ago
+42
I'm not sure if I understand step 3 very well. Why are you dividing the problem again after alreading solving it in pen and paper? |
|
+127
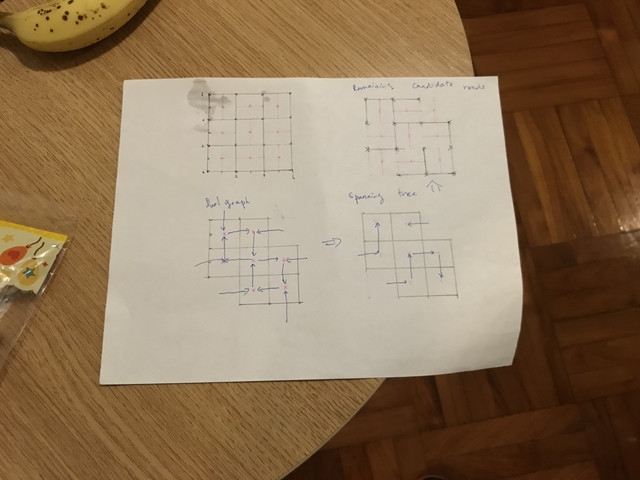
For every pair of adjacent fountains, lets assign a bench that can take care of the road between them if it is built. Firstly, we split the coordinate plane into 2x2 grids and colour them with chessboard pattern. The center of each square is a candidate position of a bench, denoted with a pink cross in the figure. For each black square, we want the center to be responsible for the roads vertically above and below it, and for each white square, we want the center to be responsible for the roads left and right of it. That is, in the figure, we want each pink cross to take care of the two candidate roads that is touched by the pink line passing through it. Now, lets solve subtask 5, where there are no 4 fountains forming a 2x2 square. We can consider all roads that we can possibly build, and if they dont form connected component we know answer is 0. Otherwise, lets find a spanning tree. Then, for each road that is in the tree, we will assign it to the bench that is responsible for it from the previous paragraph. Because there are no 2x2 squares, we know that each bench will only take care of at most 1 road and therefore we find a solution. To get full solution, we want to stop considering some candidate roads so that: 1) Each bench is responsible for 1 candidate road only. 2) The fountains remain connected. Lets consider all 2x2 squares where there is a fountain in all 4 corners. We will build dual graph, which is a graph with these 2x2 squares as vertices along with an additional vertex representing the outside region. Then, for each of these 2x2 squares $$$u$$$, there are two roads where the center is responsible for. If we walk through each of these edges, we will reach another vertex $$$v$$$. Lets build edge from $$$v$$$ to $$$u$$$. Now, we will run a dfs from the outside vertex. It can be easily seen that we will reach all vertices, and thus we will get a dfs tree spanning all vertices. Now, we know that each edge in this spanning tree cuts a candidate road. Lets stop considering these roads that are cut. We can make such observations: 1) A spanning forest of fountains that belong to at least one 2x2 square remains. You can refer to the proof of $$$V-E+F=1+C$$$ to understand this. With this result we know that even after cutting, the connectivity of the graph doesnt change. 2) For each bench that are originally responsible for 2 candidate roads, we will cut at least one of them, because we need to pass through at least one of them to enter that 2x2 square. Thus we can just continue with the new graph and plug solution for subtask 5 to finish the problem.
|
|
+3
I think this method can get under $$$10000 $$$ queries deterministically |
|
+10
Round is cool! |
|
+35
thats just bad ordering at most, not bad problems |
|
+84
icpc needs antontrygubO_o to coordinate contests for them |
|
+73
hardest problem unsolved in a contest, must be geometry |
|
+20
I had a workaround which helped me to avoid segment tree. Let the last edge of the shortest path to reach $$$v$$$ from a certain direction is $$$u - \gt v$$$, and then $$$v'$$$ be the previous node on this direction. Then either you cannot go directly from $$$u$$$ to $$$v'$$$ (due to distance being too short), or the last edge of the shortest path to reach $$$v'$$$ from this direction is $$$u - \gt v'$$$, and that the distance to $$$v'$$$ is shorter than distance to $$$v$$$ from this direction. Thus, we can run dijkstra with $$$8n$$$ nodes (but only $$$\le 3n$$$ will be visited) and when we visit a node $$$v'$$$, we only add the closest one we can reach in each direction ($$$\le 3$$$ edges of the form $$$v'- \gt x$$$), and we should also take care of the above case and add edges $$$u- \gt v$$$ suitably. Still, my code is 200+ lines... So much pain |
|
+18
How to prove the ternary search? |
|
+153
|
|
+37
I am very angry about the fact that 1475F - Unusual Matrix is included in the set. What am I supposed to learn from adhoc problems??? |
|
+74
Support |
|
+68
|
|
+53
Yes, I have talked to lior5654 and he is an extremely diligent and hardworking individual. |
|
+16
mulgokizary |
|
+14
Why not fill in this time? |
|
+3
Why are you speaking in all caps? |
|
+18
300iq provided a fix to my idea. So we can use the Queue Undo Trick for this idea, by imagining that we insert and pop vertices, as here inserting vertices is $$$O(1)$$$ updates to dsu, but we cannot use this to replace the LCT in editorial. |
|
0
Very amazing blog! |
|
+153
|
|
+13
Orz |
|
+142
|

|
+76
yeah lior5654 trying to ruin my reputation :( |
|
+44
So you don't want samples? |
|
+45
I'm sure using foul language like "shit" in blog titles and in handle is more likely to be disturbing and annoying, compared to numbers. Also, technically you don't need to look at the samples, we have tried our greatest effort to make sure that every contestant can understand the problem just by the problem statement. By the way, do you want some advice on improving at Competitive Programming? Spoiler |
|
+39
nice |
|
+61
I agree completely. William Lin is definitely the top notch streamer in Competitive Programming. |
|
+213
|
|
+43
Training an AI agent on problemsetting seems more reasonable... Good luck |
|
+137
antontrygubO_o I love your problems, please don't stop! |
|
+45
Will it block MikeMirzayanov's comments because he is unrated? Would be great if users can make a customized white list. Awesome and handy tool. |
|
0
The similar happened to me recently. I have talked about it here and we are ignored lol... Maybe we are not important enough |
|
0
You can do binary lifting and dsu, which is much more easier to code than LCT/HLD |
|
+23
Hi ko_osaga |
|
+3
I can confirm that I didn't giveaway my solution and its not quite possible to steal, as I compile with my Dev-C++ locally (not ideone). I think its is a coincidence |
|
+20
There are cool facts for $$$n=4$$$ Link, which i think is the motivation of this problem. I found them by google search and i think its cool. I also had a solution based on that. When $$$n=4$$$, plot the points $$$A,B,C,D$$$ in complex plane. Then the answer is the intersection of two lines, one passes through $$$A \times B$$$ and $$$C \times D$$$ ($$$\times$$$ is multiplication), another passes through $$$A \times D$$$ and $$$C \times B$$$. Also, these two lines are perpendicular. We can do some simple deduction and realise that the answer is $$$(AB+BC+CD+DA)/2$$$ For $$$n \geq 4$$$, we can just count the average of the above value for any 4 points, so we can just count the contribution to the answer for every pair of points in $$$O(n^2)$$$ For $$$n = 3$$$, just copy formula from somewhere :P $$$n=3$$$ was hardest for me... |
|
0
Speaking about IOI syllabus, I always have this problem about whether we needed to know splay/treap/etc or not. It says, "Problems will not be designed to distinguish between the implementation of BBSTs, such as treaps, splay trees, AVL trees, or scapegoat trees" Does that mean i only have to know how to use std::set? I asked several people and most of them thinks we need to know to write our own BST, while i think otherwise. It also appears that IOI 2013 Game requires a treap or something (? not sure), but i dont know how to get the 2013 version syllabus. What do you guys think? |
|
+31
You can solve B with the same trick you used on the problem you created! If you do it this way you can avoid tedious implementation! |
|
+36
the time where you finish the first subtask is the time where you ACed the problem |
|
+62
I think 300iq will win.
|
|
+6
codechef problem authors get money bro... |
|
+3
what, scanf also has return value. i think this is not the issue |
|
0
Yes, but i was surprised that this would make the program fail to detect a runtime error. I thought this would always return RTE |
|
0
I realised that my arrays weren't big enough. I resubmitted and it still got the same verdict. Hmm, i thought this would only get runtime error. That's interesting to know. |
|
+10
RIP |
|
-28
|
|
0
why u tag me tmw, I dont need further reminder on how smart you are |
|
+8
IOI is like marathon. Its hard to stay focus and acute for 5 hours straight. I usually get sleepy after 2 hours, maybe i do too much CF. Thats probably why some people cant perform well on IOI despite having high rating on CF. |
|
+15
How to solve Day4 Q1? |
|
+21
I assume you are talking about Day 3. Q1: Centroid Decomposition. Choose a centroid, and assume you pick nodes from subtress of at least 2 children from it, or you pick the node itself. Then you can do greedy, greedily pick the node that descreases the cost most. By some small-to-large, you can compute the costs in O(size*lg).You then update the answer of [1,size], so solving a subtree is O(size*lg), and overall complexity is O(N*lg^2) I think you need special handle for E=1, but shouldn't be trouble. For E>=2 we only pick leaves actually, but i don't see how to use that. Q2: Simple DP. Note that there exists a optimal solution that does all "set range" before "flip range". Also, all "set range" do not overlap itself, and same for all "flip range". Consider that you have x "set ranges" and you have to open/close range for y "flip ranges". Then the cost is x+ceil(y/2). Run DP from left to right, maintain dp[i][j], which is the minimum x+y you can do, for prefix i, j=0: no "set ranges" are opened j=1: You have opened a range for "set range to 0" and haven't closed it j=2: You have opened a range for "set range to 1" and haven't closed it Then you can do transition, as following: I tried the best to explain :) |
|
+10
you just put pointer 1 on A and pointer 2 on B, and maintain a BIT on a+b values Then you just do like how you do it on regular Mo's |
|
+10
use MO's algorithm |
|
+30
Break the naan evenly(by happiness) into N pieces for each person. Call p(i,j) as the position of the jth cut for the ith person The B of p(i,j) should be N*v<=2e8 Repeat j from 1 to N, take the smallest p(i,j) out of the remaining people and stop considering i afterwards It is easy to see that it works (its just a slight modification to the greedy) |
|
+29
You can delete a lot of edges and get a 2*2^(N-1) rectangle, so its pretty easy :) |
|
0
I also had this feeling but i wanted to check if the number of terms that makes up a_k grows linearly so i computed more. |
|
+9
you can derive it by https://en.wikipedia.org/wiki/Pr%C3%BCfer_sequence , which seems intuitive enough, i guess |
|
+35
https://en.wikipedia.org/wiki/Cayley%27s_formula #generalizations Then you just enumerate the number of points between A and B Knowing how to google properly gives 1750 in div1! How motivational |
|
+11
No. 150 lines is definitely not friendly (at least for me). |
|
0
How to solve B,K? |
|
0
I have found a solution! For those who are curious: https://pastebin.com/D38nbWik I think many solutions exist. I would like to hear about different approaches as well. |
|
0
Thanks for your help! I got AC now :) |
|
0
Auto comment: topic has been updated by gamegame (previous revision, new revision, compare). |
|
+10
For all possible queries we can ensure that cell 1 and 2 are either both inverted or both not inverted. It will be impossible to distinguish them. |
|
+21
Wow how to solve D? Also, more importantly, how to solve D in less than 200 lines? |
|
+1
Is there a way to view the first paper without paying? |
|
On
majk →
The Lyft Level 5 Challenge 2018 Elimination Round (Div. 1 + Div. 2) Editorial, 8 years ago
+64
Why did you cut the limit to 20000 on E? Is it because of the time limits or are you afraid that some solutions with bad asymptotic could pass? To me, i think that it would be cool if solutions with correct asymptotic and bad constants could pass too. |
|
+13
Sort the initial array and use segment tree with lazy propagation. Lets say your array is now 2 3 4 4 4 4 4 5 6 7 and you have to increase the first 5 elements You can binary search for the last element that has the same value as the xth element and update like this. (2+1) (3+1) 4 4 (4+1) (4+1) (4+1) 5 6 7 It can be done with 2 range updates. The array maintains monotone. For queries of type 2 just do binary search Im not sure what you mean about that y thing but i think you can deal with it with binary search. |
|
0
[Solved] I am able to register now |
|
+11
I have an O(NQ) solution but I'm not sure it's right or not. But if it is wrong, I would like to know a counter-example/why it doesn't work. Basically I do DP like how we do it without the ranges. Then I do sweepline, adding and removing values. When removing, I sort of undo by reversing the way how the dp is processed. http://mirror.codeforces.com/contest/981/submission/38675426 |
|
+52
Anyone else thought problem B was that normal cats get grumpy when you touch them too much? |
|
+10
How about this. Your method: (3+2)*(3+2) = 25 while max weight = (3+2)*(3+1) = 20Graph |
|
+10
Could you elaborate more about that = 0? Do you mean that you set every Bi to 0 then find max sumA? Thanks |
|
-10
Auto comment: topic has been updated by gamegame (previous revision, new revision, compare). |
|
+8
Notice that a star graph has extremely low cost. I dissected the tree into K+1 small trees where the radius of each small tree is small. Then I build a star graph with the centres of the small tree. I scored 89. I think dissecting the tree wisely (maybe dp) can get a higher score because I only used greedy. |
|
0
Can somebody explain more on how to solve D online using Cartestian tree please? |
|
0
Auto comment: topic has been updated by gamegame (previous revision, new revision, compare). |
|
0
Yeah me too. I was so frustruated when i got hacked. Took me ages to find out. |
|
0
I don't understand why this would work. How come ((S*T)mod(N*M)-O)/M = answer. |
|
0
I had troubles understanding this. Could you give a more detailed proof on why this works please? |
