|
+6
It is very simple with bitsets Sample code |
|
On
ak82 →
Invitation to CodeChef March Starters 29 (Rated for Div 2, 3 & 4) — 9th March, 4 years ago
+3
Sorry, this was unexpected and unknown to us. I couldn't find this problem while searching for it, otherwise this wont be there. |
|
+41
Short summary of my solutions for P1 to P6 : P1 P2 P3 P4 P5 P6 |
|
+4
Wow, its just a single leap of faith from $$$O(3^N)$$$ solution. All time, I was being conservative by using only submasks to account for all elements, and not missing out. But we can let go of some elements and collect them at the end, that's cool. |
|
+13
You don't have to consider only set bits to perform operation on mask https://www.codechef.com/viewsolution/56343428 (replaced ss[k] with k from 0 to nn — 1) |
|
On
Utkarsh.25dec →
Invitation to CodeChef Starters 17 (Rated for Div 2 & 3) - 17th November, 4 years ago
+4
It means that Interactive Judge was waiting for user input and User's code didnt gave, so that Time limit exceeded. |
|
+7
Thank you providing feedback for each problem. It really helps when preparing future contests. Here is my take on CAPATHS : Lets consider simple problem where we have to find a path having maximum sum. That is standard dp on trees. Now we can formulate the original problem as : Given a tree where each node has a pair {x,y} where x is 0/1. Find a path having maximum sum of y values such that xor of x values is 0. We can use standard dp on trees while maintaining maximum sum for xor 0 and 1.(+ve and -ve) |
|
+32
Intended solution for DLTNODE : Lets consider a simple problem where we remove an element from array. Here we usually maintain prefix and suffix gcds. We can do the same by flattening tree using euler tour and compute prefix,suffix gcds. Now we can find gcd of subtree using dfs and all nodes except subtree using these arrays. Works in O(N) (log of computing suffix gcd will be amortized) |
|
+26
"Sorry for inconveniences caused. Site is under maintenance. Servers will be up soon." So when ? |
|
+25
For a fixed starting position, prefix gcd changes only log(A_max) times. So we can find n*log(A_max) tuples of type [g,L,R1,R2] , where subarrays [L,R1] to [L,R2] has gcd g. Let's consider queries for single gcd g : we maintain a segment tree where ith value stores maximum length of subarray ending at that index. For a single tuple [L,R1,R2] we add R1-L+1 at index R1, R1-L+2 at index R2 and so on. Process all the tuples and queries offline in reverse sorted order of L. |
|
+3
If bruteforce worked pretty fast, means values were pretty small, why didn't you just do that ? For x,y,z choose first 10 and last 10 numbers. For n choose all numbers as above plus the numbers around phi(m). I just tried it and it passed. Spoiler |
|
+20
FFT is not required. Since polynomial can be converted to this form : (1 + x^k + x^2k + ... + x^mk) We can find resultant polynomial in O(n) using prefix sums taken at k distances. |
|
-10
I think it will work. When binary searching, if length is odd, keep edge as center else keep node as a center. To handle edges, just make another tree of n-1 nodes from edges. |
|
+55
Fixed thanks |
|
+78
Unable to share webcam through OBS (it shows blank) and system is lagging a lot. Proctoring platform needs to be |
|
+12
Solutions for Singleton Code seems strange. After well establishing that S(n) = n % 9 , why not do just that ? My solutions : Easy version Hard version |
|
0
The same code passes in 1950ms if you choose language GNU C++17 (64 bit) |
|
On
radoslav11 →
Invitation to CodeChef July Lunchtime 2021 - Saturday, 31st July, 6 PM IST, 5 years ago
+5
The transitions become much harder this way. Instead of prefix,use suffix because : If group j starts from index i, then xor of suffix [i...n] is multiple of 2^j. and (j+1)th group can start from any index k > i without disturbing jth group. Then, DP[i][j] => Number of sequences in suffix [i...n] where $$$j_{th}$$$ group start from $$$i_{th}$$$ point. For transitions, 1) suffix[i...n] is the last group : 1 way 2) next group starts at index k > i : DP[k][j+1] ways. So we can just store sums of DP[i][j] for each j. Ideally we would have to maintain it for j <= n (when xor is 0,we can have many groups), but again all values after j >= log(A[i]) will be same. |
|
On
radoslav11 →
Invitation to CodeChef July Lunchtime 2021 - Saturday, 31st July, 6 PM IST, 5 years ago
+26
Please tell your approach. For me, an array of size O(log(A[i])) is enough. |
|
0
Its wrong |
|
+6
For rocket, go to https://judge.yosupo.jp/problem/point_add_rectangle_sum and find a submission that makes sense to you |
|
+3
I think BLAZA can be done this way (I might be wrong), I ran out of time implementing it. First we build suffix automaton for the given string and get the tree of links. For each node (state) we can maintain index where that suffix ends and occurences of the string at that state. Also for each node of the tree, we have to find the two closest indices considering all nodes in its subtree (which can be done using DSU on trees). Finally, for each node we know the length of the 2 closest occurences, the lengths of strings that appear at that node and number of times it appears in string. |
|
+53
Thank you very much. It's great that you care so much that you resolved it even before I wrote. |
|
+48
Today I received 2 messages from the system telling that my codes for problem B (117877311) and C (117883398) matches with the codes of aerfanr for problem for B (117886611) and C(117894142). So please note that I do not share my codes to anyone and I have been using rextester.com to run my codes, which does not automatically publish any code. The match is a coincidence which has occured due to the simplicity of the solutions, For both of the submissions the main part is only 10-12 lines and the approaches are same as in the editorial. Also check that at any point, the implementations entirely different. MikeMirzayanov Please help me and tell me if there is anything more I can do to prove the coincidence. |
|
0
Same Here |
|
+25
Whenever there is a combinatorics problem in one dimension, it is often the case it's formula or some related information will be available on OEIS. So find the answer for small terms and search these terms in oeis.org and you will get the formula for it. To solve E , Step 1 : Try to reduce a problem to find the answer for only 1 row having N white color cells. Step 2 : Write bruteforce and search OEIS. |
|
+33
OEIS |
|
+25
It can also be done this way : First we remove all the nodes with indegree 0 or outdegree 0. (After removing a node, we would again need to check for it and keep removing such nodes). Now if we have two nodes, $$$A$$$ and $$$B$$$, $$$k_A \gt = k_B$$$ then I claim that we can go from $$$B$$$ to $$$A$$$ (Yes! without any other assumption). Number of nodes reachable from $$$B$$$ = $$$n - k_B$$$ and Number of nodes reachable to $$$A$$$ = $$$k_A + 1$$$ If we can't reach from $$$B$$$ to $$$A$$$, total nodes would be $$$n + 1 + k_A - k_B \gt n$$$ , its not possible. So we can go from $$$B$$$ to $$$A$$$. |
|
+5
Still not able to make submission. |
|
+3
Queue Is Full, Try In Few Secs from last 5 mins. |
|
+15
I submitted A at 14 minutes 50 second and italso passed pretests, but it doesn't show green colour and option to lock in Dashboard. Though, it is there for other 3 problems. |
|
0
I havent look at the code, but there csn be many nodes with same value. |
|
0
Is there an option to run our code for custom testcases like custom invocation ? Because many times it happened that my code ran well on other compiler and but gave runtime error on codeforces. So I would better run few cases on the platform to test my code. |
|
+16
Well, this is a great news to me. But, Do I have to be happy about it or not : Both the Preliminary Round & Regional Round will be held " online " on CODEDRILLS platform. |
|
+15
I have a different explanation for problem F , though the final approach is almost the same. At each point we have two choices : 1) Make $$$a[i] = b[i]$$$ 2) Make $$$a[i] = b[i]-$$$(prefix_sum up to $$$i-1$$$ elements in a[]). So answer could have been $$$2^n$$$ except when both choices gives the same array. When both the choices give the same array , prefix_sum of $$$i-1$$$ elements should be 0. This way I got 2 tasks , (1) Find the number of distinct arrays for first i elements : dp1 , (2) Find the number of distinct arrays for first i elements having sum 0 : dp2. Then we directly have, $$$ dp1_i = (2*dp1_{i-1}) - dp2_{i-1}$$$. To calculate $$$dp2_i$$$, we have one more observation that, when we do operation of type (1), $$$b[i]$$$ adds to the previous prefix_sum and for type (2), prefix_sum becomes $$$b[i]$$$. This tells us that, prefix sum of i elements in a[] will be a subarray of b ending at i. So $$$dp2_i$$$ considers the smallest subarray of b ending at $$$i-1$$$ and having sum 0 (This is a standard task using hashmap). Let's say $$$[x,i-1]$$$. Then we take a unique subarray of $$$x-1$$$ elements, do a type 2 operation for x and do type 1 operation for elements in range $$$(x+1,i-1)$$$. This gives $$$dp2_i = dp1_{x-1}$$$. |
|
+32
My simplest solution to Div.1C : Randomly choose an index and check if its value is not k. When we find such index, break. If value is more than k, keep going left else keep going right till we find k. Is it hackable ? |
|
0
Can we do it like this then ? (just assuming R_min >= L_max for ease) sort all the pairs by R[i]. consider these N ranges now : L_max to R[0] R[1] to R[2] R[2] to R[3] ... R[N-2] to R[N-1] For each range, we find contribution of that range in the expected value, where we consider (N — i) i.i.d. RVs. |
|
0
Can you tell if this is true, Expected value when there are N ranges, all having same range[L,R] is : L + (R-L)*(N/(N+1)) |
|
+41
Max flow :) |
|
+13
Please enlighten with your solution to F. I was clueless even after spending an hour. |
|
0
Maybe this can give you some courage to fight for your dream : https://youtu.be/DQ4IU6D7YwY |
|
+5
It is incorrect actually. |
|
+5
Thanks, I seem to get it. I thought it will follow Acyclic order of evaluation, but it is not the case. Technically I should get WA on subtask 1 too. |
|
+13
I set DP[i][j] = -1 Initially In the recursive function, If DP[i][j] != -1 return DP[i][j] else DP[i][j] = 10^12 Calculate here.... |
|
+16
Can you tell if this Dynamic programming is equivalent ? DP[i][j] = Cost to product stone j at city i I check 3 ways :
|
|
+4
How am I getting AC in subtask 1 and WA in subtask 2 for Problem D, (I guessed TLE would be okay) |
|
0
I also have the same problem. If you find checker or anything else please do tell me |
|
+6
Same issue happens at every phase, I was stuck at "challenge phasee 0:00:00" after it ended, and after relogin it stucked at "system testing 0:00:00". |
|
+14
I am not getting how to challenge someone, I opened the someone's code from my room, I scroll down the whole code and don't see challenge button. Can anyone tell me where to find it ? |
|
+13
I am also unable to enter the round. I can find myself in registrants list. |
|
0
Does it uses idea of convex hull ? |
|
+14
This might give you the idea where it fails : Input : 4 3 1000000000 1 2 1 2 3 100000 1 4 99999 Here you will be getting maximum answer by repeating the edge 99999. But there comes a time when 100000 will dominate. |
|
0
|
|
0
Now I got it. Thanks for the help. |
|
+27
Problemset was nice. Here is a simpler solution for Problem A : let k denote the number odd values in the array. Answer is "no" if one of the following satisfies : 1) k = 0 2) k = n and x is even 3) x = n and k is even Why ? (Left to reader) |
|
0
I didn't, that's why I converted double to int and then calculated the result. I am yet to find any solution which always works for doubles. |
|
0
Thank you very much. This is what I was looking for. Being skeptic, if x_double is 4.50 is there any chance I will get 5 instead 4 using your suggested solution ? |
|
0
Yes, that works well. I used the similar thing to get AC later. Thanks for the answer. |
|
0
Thanks for the solution. Any advice on how to avoid these errors in future ? |
|
0
Why does long double over double changes anything ? considering value of is B < 10, having 2 digits are decimal point. |
|
0
Why does long double over double changes anything ? considering value of is B < 10, having 2 digits are decimal point. |
|
0
But here multiplications are in long long, the only place where precision could affect is assigning "b = c*100". |
|
0
Any care to explain why is this wrong for problem C ? It gives WA for random_12.txt Edit : I always define int as long long in my template. |
|
+8
It seems that Ofast + target("avx2") together causes Runtime Error. But using them separately gives AC. |
|
0
Well, Thanks for the hack. There are some mistakes in your calculation because I can check 6 primes (why not ?) and I stick to word "remaining" so I remove checked primes for next queries. Still proof by hack says it is significant. Here I changed limit from 1000 to 800. Because If all 3 primes are > 800, answer is atmost 8. |
|
+8
I have a randomised solution here. Can it be hacked or improved ?? Here are the details of my solution: I ask for all the primes less than (10^9)^(1/4). Which can be packed into 4 queries. Then I ask for the primes found in another 5 queries. Now the remaning part has atmost 3 primes. Let's denote the remaning part as 'Y' and the no. of divisors found so far as "res". Case 1 : Y = p / p*p / p*p*p / p*q , answer = res*2 Case 2 : Y = p*q*r / p*q*q , Here If I manage to find atleast one prime's existence, I can safely answer res*4, otherwise I answer res*2. Atleast one prime among these will be less than X^(1/3). So for each remaning query, I shuffle the remaining primes from (10^9)^(1/4) to (10^9)^(1/3) and ask the query by taking maximum primes. |
|
+6
Problem Statement says : Note that the order the variables appear in the statement is fixed. For example, if f(x1,x2):=(x1<x2) then you are not allowed to make x2 appear first and use the statement ∀x2,∃x1,x1<x2. If you assign Q1=∃ and Q2=∀, it will only be interpreted as ∃x1,∀x2,x1<x2. |
|
+15
The requirement for a variable x(i) to be universal is that, In the directed acyclic graph, No node x(j) with j < i can reach x(i) and x(i) also cant reach such x(j). In other words, all nodes reachable from x(i) and reachable to x(i) should have higher labels. To check that, we do DP and find minimum below and minimum above in reversed graph. |
|
+5
The problem is that, x3 < x2 Now you have fixed x2, (As There exists x2 comes first in order) , so not all x3 holds x3 < x2. A requirement for universality is that the variable is only comparable with larger-indexed variables. It is mentioned in the 2nd paragraph of editorial. |
|
0
It is O(n*n) because, 1) To reach node 1 to node t, You will buy coins O(n) times. 2) Among above O(n) cities, it takes O(n) edges to move to node where we buy the coins next. |
|
0
Thanks for pointing this. I tried to figure out what went wrong and I found that my solution is wrong as it requires O(n*n) iterations. It passed due to weak testcase. Testcases where I get WA : (An extension to 3rd sample case) |
|
0
I don't understand the case you are talking about. Here is my code. Input format is same as lightOJ's question (without testcases). I got AC in lightOJ using this approach for n < 1000. Time complexity : O(N*N) |
|
0
Consider the code Here The part where I construct the matrix, I think it will take very less time than actual time complexity because most of the transitions will share 0 characters to prefix. |
|
0
Yes, you are right. Though 26*N*N cant pass N = 10000 but It seems that 26*N*N never occurs. What will be the actual worst case ?? |
|
+11
There are total N*N states and each state might require O(N) operations to update. In case like abacacacac, DP[i][2] updates from DP[i][3], DP[i][5] etc. (I dont know of such a hard case which updates O(N) states but I think it can exist) |
|
0
3) Let DP[i] denote number of strings of length i such that T ends at i for the first time. (At last we can add DP[i]*26^(N-i) to get all strings which containt string T and subtract it from 26^N. ) Initialize DP[i] to be 26^(i-len(T)) for i >= len(T). Now we subtract from it all cases where string can end before i. (Similar to this ) Note that there may be indices j > i — len(T) from which we can update (preprocess needed) |
|
+11
2) DP[i][j] denoting current string has length i and its suffix shares j characters with prefix of T. DP[i][j] updates from DP[i-1][j-1] for j > 0. DP[i][0] updates from DP[i-1][k] for each k. DP[i][j] can also be updated from DP[i-1][k] where k>j (preprocessing will be required to find) |
|
0
Here you go |
|
+3
You are right, Thanks. |
|
+5
Your submission can pass with given time complexity, but you are using much memory so it increases the time. |
|
+5
You can try the following : dp[i][j] denotes minimum time to go to the ith node with j silver coins from 1. Now repeatedly update this dp (n+1) times, as in bellman — ford. ( + 1 because initially I don't initialize it ) UPD : There is a case where this gets Wrong Answer. Sorry. Theoretically it requires O(m*m) iterations. |
|
0
This is what I see during the whole contest and still it is showing the same.
|
|
-18
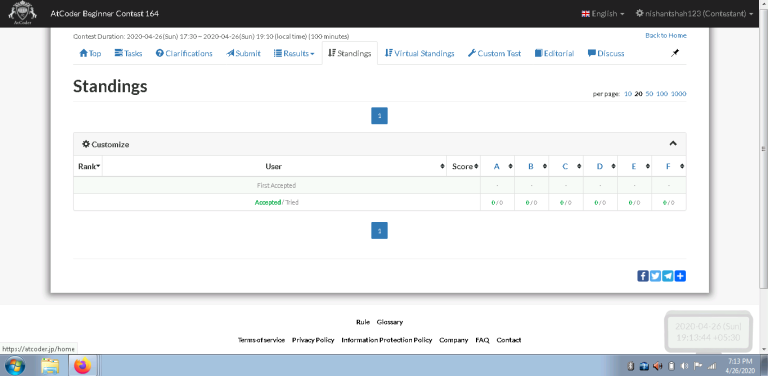
Are standings hidden ? |
|
0
It seems different than what I am asking for. The way I planned to update answer is simply A[i]*query(i,i). |
|
+3
Need help in proceeding through different approach of the problem DOTTIME : My approach : I maintain a segment tree seg[N], where seg[i] represents the sum of all the elements which multiplies to A[i]. (Consider A[i] to be the first element of the product pair) I proceed to check how A[i] multiplies to the elements from j = 1 to n, by creating an array B[N][N] (Just for bruteforce), where B[i][j] represents how many times A[i] and A[j] multiplies. I observed that B is symmetric and each row of B is a combination of 4 Arithmetic Progressions. Which first increases from 1 with difference 1 ,then some constant terms , and then decreases to 0. (This helps me to do 4 range updates in segment tree for each query.) It was complicated for me to find the indices where these APs start in temrs of i. Can anyone help me with a neat way to find this ?? |
|
0
|
|
+9
1) I can compute nth row of probabilities (no restrictions) using FFT. First row is simple.Now polynomial (1+x/2+(x/2)²+...+)/2 computes next row. I compute (r+1)th row. Then I sum over 1 to u-1 and each time remove previous term/2 to not overcount. Similarly for (d+1) row. 2) It seems that implementation above is for Modular field only. I was seeking for doubles. |
|
0
Yes, it was simpler to use combinatorics. But I had no experience of computing large N choose R in doubles so I didnt think that way. and even if I find that formula, I wont be sure of precision errors. |
|
0
Did anyone else solved D using FFT ?? I want to know their implementation of FFT. (Yes it was an overkill and took me upto last 2 minutes to optimize) |
|
+17
In F,Why did you keep 1 as white and 0 as black ? If your intention was to delay submission time by 2 minutes, congrats :D |
|
+5
This was brilliant !! How did you come up with this approach ?? Thank you. And thank you for your wonderful book Guide to CP. I started my journey from that. |
|
+13
Need help in the last problem, It turned out for me that there are only 3 types of matrices needed. Where in the diagonal : 1) x appearing n times. 2) y and z appearing 1 time and x appearing n-2 times. 3) y appearing 2 times and x appearing n-2 times. 1) is simply shifted identity permutations. 2) is just swapping first row and second row,then we can swap 2 digits to get intended diagonal. 3) I did not found any direct solution. (btw we can easily do it when n is even.) Does anyone know a constructive approach to build the matrix of type 3 ?? Thanks. Edit : By constructive approach I mean a direct pattern based solution which we can perform by hand. I am not good with flows. |
|
+9
I used the example I found yesterday here : https://stackoverflow.com/questions/20847463/finding-length-of-shortest-cycle-in-undirected-graph Instead of one chain from A to C, I used 8 horizontal chains between B to D. Gave 8 as the input to the following : |
|
+44
During the contest, I automatically got logged out from codeforces. I had two tabs of codeforces open in firefox. When I tried to submit I got to know I am not logged in. This has happened thrice. Is it normal/minor bug or there is some other problem ? |
|
+1
Yes it is. Initially it passed at around 30ms so I thought there must be some magic, but when I calculated time complexity I got exponential so I hacked it. |
|
+23
Yes, good to keep it lower otherwise I would rather think about the different solution. Nonetheless it was a good problem. |
|
+12
More reasonable bound should be around 10^4, given t <= 1000 and time 3s. Unless and until there is some magic :D |
|
+2
Greedy + Divide and conquer solution for E : The greedy observation is that, minimum value in the array must be combined if possible. Now consider a subarray having equal minimum elements. Case 1 : It's length is even, then combine each pair is optimal Case 2 : It's length is odd, then you should combine first few even elements, left one element which will break array into two, combine last remaining even elements. Now call solve function for these 2 partitioned array, Do this for each possible breaking element at odd positions in subarray. During contest, for Case 2, I called solve for the whole array again instead of 2 partitioned array. Which I hacked after the contest. Update : Sorry, but this solution is also hacked by me. |
|
+20
In problem F, how to find upper bound on precalculation ? What I did is calculate 3 grundy values for 3 different attacks for a particular castle. Since x,y,z <= 5 , we need atleast 5 states to repeat. First value can be from 0 to 3 and 2nd,3rd value can be from 0 to 2. So I thought (4*3*3)^5 is an upper_bound which is not the case. |
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 158 |
| 2 | adamant | 152 |
| 3 | Proof_by_QED | 146 |
| 3 | Um_nik | 146 |
| 5 | Dominater069 | 144 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 9 | TheScrasse | 134 |